
預訓練模型——開創NLP新紀元
阿新 • • 發佈:2020-11-17
## 預訓練模型——開創NLP新紀元
[論文地址](https://arxiv.org/pdf/2003.08271v3.pdf)
[BERT相關論文列表](https://github.com/tomohideshibata/BERT-related-papers)
[清華整理-預訓練語言模型](https://github.com/thunlp/PLMpapers)
[awesome-bert-nlp](https://github.com/cedrickchee/awesome-bert-nlp)
[BERT Lang Street](https://bertlang.unibocconi.it/)
[huggingface models](https://huggingface.co/models)
### 論文貢獻

- 對如今自然語言處理研究中常用的預訓練模型進行了全面的概述,包括背景知識、模型架構、預訓練任務、預訓練模型的各種擴充套件、預訓練模型的適應方法、預訓練模型相關資源和應用。
- 基於現有的對預訓練模型分類方法,從四個不同的角度提出了一個新的分類方法,它從四個不同的角度對現有的原型系統進行分類:
- 表示型別
- 模型結構
- 預訓練任務的型別
- 特定型別場景的擴充套件
- 收集了大量的預訓練模型的資源,包括預訓練模型的開源實現、視覺化工具、語料庫和論文列表
- 針對預訓練模型,提出了幾個可能的未來研究方向。
### 背景
#### 語言表示學習
一個好的語言嵌入表示應該能夠蘊含文字語料中隱含的語言規則和常識資訊,例如**詞彙的含義、句法結構、語義角色、語用學**等資訊。**分散式表示**的核心在於用**低維實值向量**來描述一段文字的含義,該向量的每個維度上的值都沒有對應的意義,但是向量**整體代表了一個具體的概念**。
##### 與上下文無關的嵌入
將離散的語言符號對映到分散式嵌入空間中,具體來說,對於詞彙表 $\text{V}$ 中每個單詞 $x$ ,將其對映成一個 $d$ 維的實值向量,由此得到一個由**詞彙表中全部單詞的嵌入向量作為列向量**的嵌入矩陣 $\text{E}^{d × |\text{V}|}$,矩陣的列數就是詞彙表 $\text{V}$ 中單詞的總數 $|\text{V}|$,矩陣的行數就是嵌入向量的維度 $d$。因此,**單詞 $x$ 的嵌入向量 $e_{x}$ 也可以由其唯一的獨熱編碼 $h_{x}$乘上嵌入矩陣得到**,即
$$
e_{x} = h_{x}E
$$
**問題**
- 嵌入是**靜態**的,即單詞的嵌入與上下文無關。然而當遇到**多義詞**時,不跟據上下文語境的話,無法判斷其真實代表的含義。
- **詞彙量不足**。採用字元或者單詞的**子詞**作為基本表示單位。例如**CharCNN、FastText**和**Byte-Pair Encoding**等表示方法。
##### 語境嵌入
為了解決與上下文無關嵌入存在的問題,需要區分單詞在不同語境下代表的語義。
**利用不同的神經上下文編碼器 $f_{\mathrm{enc}} \left(·\right)$ 對與上下文無關的嵌入 $x_{t}$ 進行編碼,得到蘊含上下文資訊的語境嵌入 $h_{t}$。**
$$
\left[\mathbf{h}_{1}, \mathbf{h}_{2}, \cdots, \mathbf{h}_{T}\right]=f_{\mathrm{enc}}\left(x_{1}, x_{2}, \cdots, x_{T}\right)
$$
下圖是展示了利用神經編碼器對上下文無關嵌入向量進行編碼後得到語境嵌入,然後將其用於下游的面向具體任務的模型。
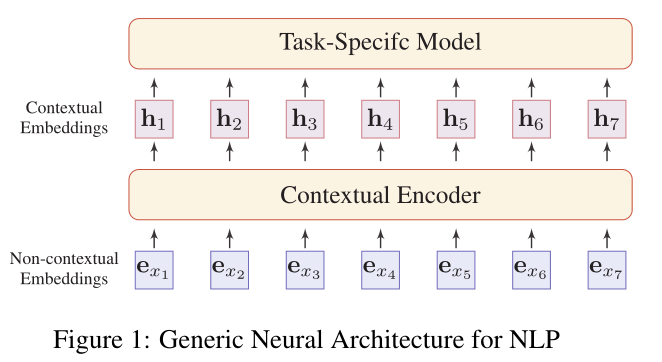
#### 神經上下文編碼器
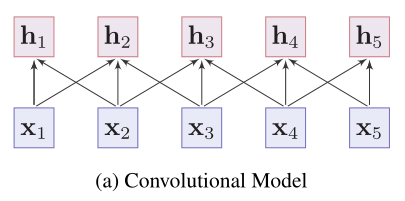
大多數神經上下文編碼器可以歸結為兩類:
- **序列模型** —— 按照順序捕捉單詞的區域性上下文資訊
- **卷積模型** —— 將輸入句子中單詞的嵌入作為輸入,通過卷積運算**聚集**某個單詞來自其**鄰居的區域性資訊**來獲取該單詞的含義
- **遞迴模型** —— 遞迴模型**捕捉短記憶單詞的上下文表示**,如**LSTMs 和GRUs**。從一個詞的兩邊收集資訊,但遞迴模型的效能往往受到**長句子語義依賴問題**的影響。
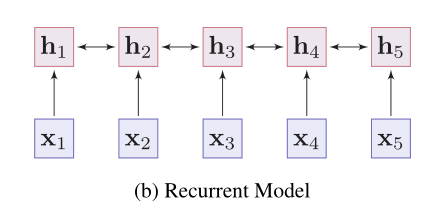
- **優點**
- 易於訓練
- 對於各種自然語言處理任務能獲得良好的結果
- **缺點**
- 學到的單詞的上下文表示具有區域性性偏差
- 難以捕捉單詞之間的長期互動
- **非序列模型** —— 非序列模型通過預先定義的單詞之間的樹或圖結構來學習上下文表示,例如句法結構或語義關係。經典的模型包括**Recursive NN、TreeLSTM和圖卷積網路GCN。**
- **圖模型存在的問題**
- 如何建立一個好的圖結構也是一個具有挑戰性的問題
- 圖結構嚴重依賴於專家知識或外部NLP工具。
- **全連線自注意力模型**
- 為所有單詞嵌入建立全連線圖,讓模型自行學習關係結構。
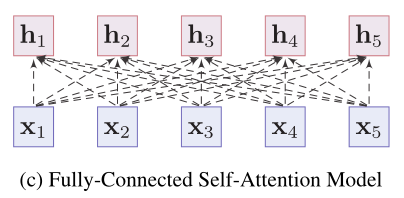
- 連線權重由自注意力機制動態計算得到
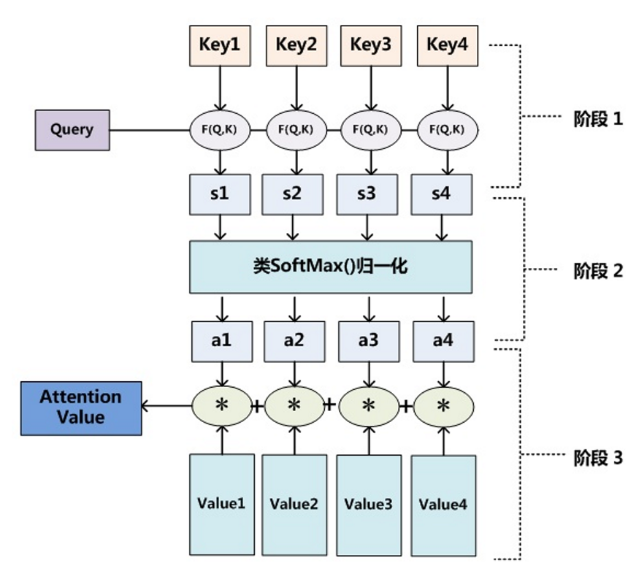
- **Transformer**
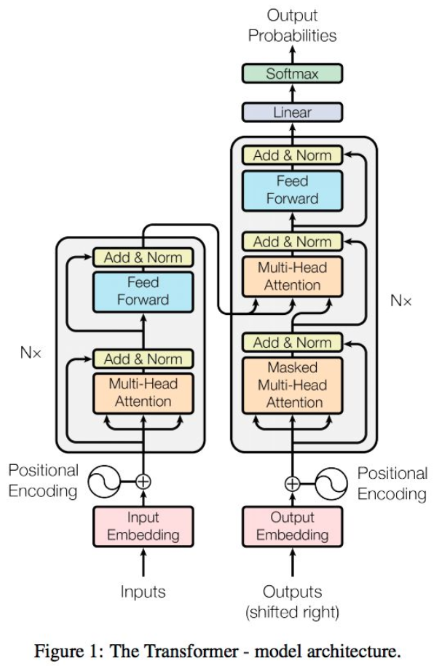
- **優點**
- 直接對序列中每兩個單詞之間的依存關係進行建模,更強大,已成為當前預訓練模型採用的主流架構
- 更適合對語言的長程依存關係進行建模
- **缺點**
- 由於其複雜而又沉重的架構以及較小的模型偏差,Transformer通常需要一個大的訓練語料庫進行訓練
- 訓練時,容易在小的或中等大小的資料集上出現過擬合問題
#### 預訓練模型誕生背景
隨著深度學習的發展,模型引數的數量迅速增加。需要更大的資料集來充分訓練模型引數並防止過度擬合。然而,對於大多數自然語言處理任務來說,構建大規模標註資料集是一個巨大的挑戰,因為標註成本非常昂貴,尤其是對於語法和語義相關的任務。相比之下,大規模的無標籤語料庫相對容易構建。
為了利用大量未標記的文字資料,可以首先從它們那裡學習一個好的表示,然後將這些表示用於其他任務。研究表明,藉助於從大型未標註語料庫的語料庫中提取的表徵,許多自然語言處理任務的效能有了顯著提高。
預訓練的優勢有如下幾點:
- 在大規模文字語料庫中能學習到一般的語言表示以用於下游任務
- 使得下游任務採用的模型能更好地被初始化,並獲得更好的泛化表現,加速下游任務模型的收斂
- 預訓練可以看作一種正則化的方式,避免模型在小規模資料上過擬合
#### 預訓練模型的發展史
預訓練一直是學習模型引數的一種有效策略,預訓練完畢之後,利用標記資料對模型引數進行微調以適應下游任務。
##### 第一代:預訓練詞嵌入
**模型發展:**
- **NNLM**
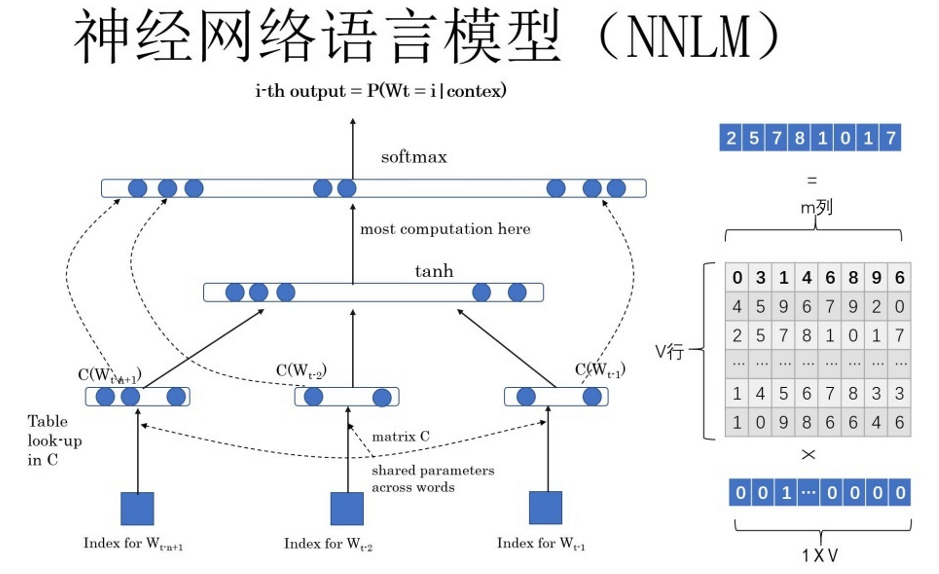
**學習任務**
輸入某個句子中某個單詞的前 $t-1$ 個單詞,要求NNLM網路**最大化**第 $t$ 個位置出現該單詞的概率,例如給定文字句子:”The most popular pre-train models is Bert",根據前6個單詞,讓模型預測單詞"Bert"即最大化以下概率:
$$
P\left(W_{t}="Bert" \mid W_{1},W_{2},W_{3},\cdots,W_{t-1};\theta\right)
$$
其中 $W_{i}$ 為單詞的獨熱編碼,它們作為模型的初始輸入,$W_{i}$ 乘上矩陣 $Q$ 之後就得到對應單詞的word embedding值 $C\left(W_{i}\right)$。將每個單詞的word embdding拼接起來,上接隱層向量,然後經過一個 $softmax$ 層預測後面緊跟著應該接哪個詞。
事實上,矩陣 $Q$ 的每一行代表著對應單詞的word embedding值,只不過矩陣 $Q$ 的內容也是模型引數,需要學習獲得,$Q$ 最初用隨機值初始化。當模型訓練完畢,矩陣 $Q$ 就是NNLM模型在大規模文字語料庫上完成語言模型的訓練任務後得到的副產品,這個 $Q$ 的每一行都是對應單詞的嵌word embedding。
- **Word2Vec** —— 基於預測的模型(兩種不同訓練方式)
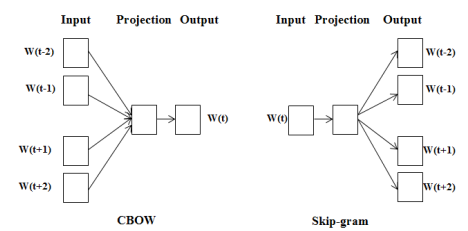
- **CBOW** —— 從上下文預測中間詞(完形填空)
- **Skip-Gram** —— 從中間詞預測上下文
- **Glove** —— 基於統計的模型
基於全域性語料庫構建詞的**共現矩陣**,矩陣的每一行是一個word,每一列是context。共現矩陣就是計算每個word在每個context出現的頻率。通過對詞的共現計數矩陣進行降維,來得到詞向量;首先需要根據整個語料建立一個大型的體現詞共現情況的矩陣,其**目標是優化減小重建損失**(reconstruction loss),即降維之後的向量能儘量表達原始向量的完整資訊。
GloVe 相對於 Word2Vec 有一個優點是**更容易並行化執行**,可以更快,更容易地在大規模語料上訓練。
**第一代預訓練詞嵌入的優勢:**
- 儘管網路結構簡單,但是仍然可以學習到高質量的單詞嵌入來捕捉單詞之間潛在的句法和語義相似性
**不足之處:**
- 得到的詞嵌入向量與上下文無關,當詞嵌入被應用於下游任務時,模型的其他引數需要重新訓練。
##### 第二代:預訓練語境編碼器
**模型發展**:
$$
\text{ELMO} \rightarrow \text{GPT} \rightarrow \text{BERT}
$$
由於大多數自然語言處理任務超出了單詞層面,自然要在句子層面或更高層面對神經編碼器進行預訓練。神經編碼器的輸出向量也被稱為上下文單詞嵌入,因為它們根據單詞的上下文來表示單詞的語義。
研究者發現,序列模型**Seq2Seq**在做文字分類任務時,編碼器和解碼器的權重用兩種語言模型的預訓練權重初始化,然後用標記資料微調。模型的表現大大提升。
現如今,預訓練模型通常使用**更大規模**的語料庫、更復雜的神經網路模型結構(例如,Transformer)和新的預訓練任務來訓練。
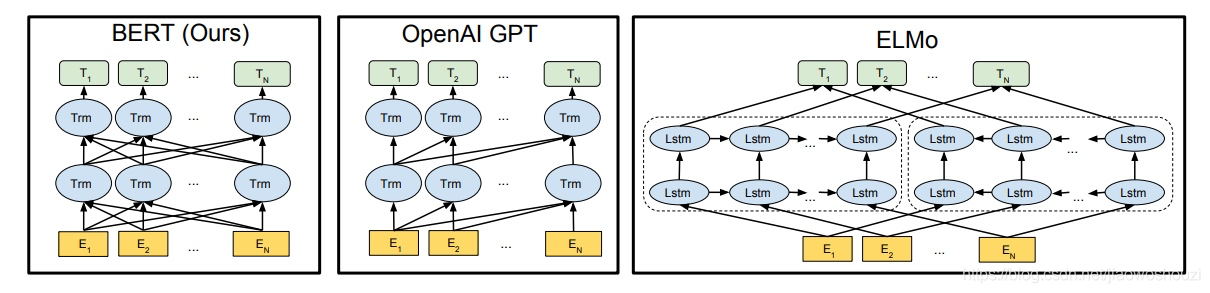
- **ELMo**
- **預訓練階段**
- 利用**語言模型**進行預訓練,該語言模型的任務是根據單詞的上下文序列正確預測該單詞。
- **ELMO**網路結構**採用了雙層雙向LSTM**,左右兩端分別是正反向的雙層的LSTM編碼器。
- 模型輸入的句子中每個單詞都能得到對應的三個嵌入向量:最底層的(**黃色部分**)是詞嵌入Word Embedding,第一層雙向LSTM中對應單詞位置的Embedding,蘊含單詞的**句法資訊**;然後第二層LSTM中對應單詞位置的Embedding,蘊含單詞的**語義資訊**。
- **微調階段**
- 將下游任務模型的輸入通過ELMO進行編碼得到文字嵌入,整合三種Embedding,將整合後的Embedding用於下游任務模型網路結構中對應單詞的輸入。
- **特點**
- 採用了典型的**預訓練-微調**的兩階段過程
- 預訓練過程中,不僅學會了單詞的word embedding,還學到了一個雙層雙向的LSTM網路結構,這個雙層雙向的網路結構可以用來提取文字的句法資訊、語義資訊。
- **不足**
- LSTM的**特徵抽取能力**遠比不上Transformer
- 雙向拼接的**融合特徵的能力**不夠強
- **GPT**
- **預訓練階段**
- 預訓練的過程其實和ELMO類似,仍然以語言模型為目標任務,但是**語言模型改成單向**的,即只根據上文正確預測當前位置的單詞,而把單詞的下文完全拋開。
- 特徵抽取器換成了**Transformer**,特徵抽取的能力大大提升
- **微調階段**
- 對於不同的下游任務,**網路結構要向GPT的網路結構看齊**。在做下游任務的時候,利用預訓練好的引數初始化GPT的網路結構,這樣通過預訓練學到的語言學知識就被引入到下游任務中。
- 模型引數初始化後,用下游任務去訓練這個網路,對網路引數進行Fine-tuning,使得網路更適合解決下游問題。
- 改造下游任務
(1)對於**分類**問題,加上一個起始和終結符號即可;
(2)對於**句子關係**判斷問題,比如Entailment NLI,兩個句子中間再加個分隔符即可;
(3)對**文字相似性**判斷問題,把兩個句子順序顛倒下做出兩個輸入即可,這是為了告訴模型句子順序不重要;
(4)對於**多項選擇**問題,則多路輸入,每一路把文章和答案選項拼接作為輸入即可
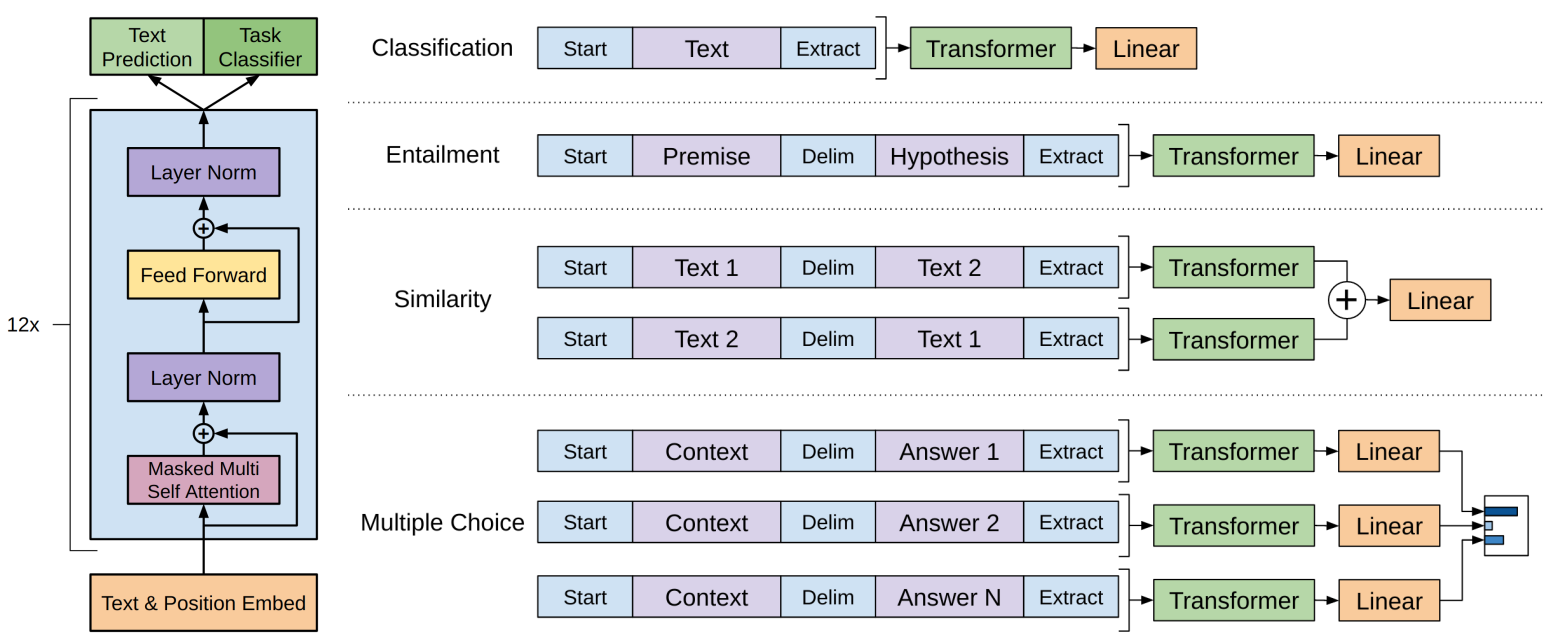
- **特點**
- 訓練的是單向語言模型
- 採用更強大的特徵提取器Transformer
- **不足**
- 單向語言模型改成雙向就好了
- **BERT**
- **預訓練階段**
- **MLM(掩蓋語言模型)**
(1)**MLM**任務,即**隨機遮蔽**(MASK)部分輸入token,然後只預測那些被遮蔽的token。
(2)但是這麼幹之後,預訓練階段和finetuning階段之間就不匹配了,因為在finetuning期間不會見到[MASK]。為了解決這個問題,BERT的做法是:不總是用實際的[MASK]替換被“masked”的詞彙。相反,訓練一個數據生成器隨機選擇15%的token,執行以下過程:
**80%**的時間:用**[MASK]標記替換**單詞,例如,my dog is hairy → my dog is [MASK]
**10%**的時間:用一個**隨機的單詞替換**該單詞,例如,my dog is hairy → my dog is apple
**10%**的時間:保持單詞**不變**,例如,my dog is hairy → my dog is hairy.
(3)**缺陷**:MLM模型下,一些單詞會被隨機替換,而Transformer的encoder部分不知道它將被要求預測的那些單詞或哪些單詞已被隨機單詞替換,因此它被迫保持每個輸入token的分散式上下文表示。同時,由於訓練MLM時,每個batch只預測了15%的token,這表明模型可能需要更多的預訓練步驟才能收斂。這無疑增加了訓練成本。
- 和GPT不同的地方在於,BERT採用和ELMO一樣的**雙向語言模型任務**作為預訓練任務;
- 和ELMO不同的地方在於,BERT採用和GPT一樣的特徵提取器**Transformer**,集兩家之所長。
- **微調階段**
- 和GPT一樣,BERT也面臨對下游任務進行改造的問題
- 改造下游任務
**(1)句子對分類** —— 在句子開頭加上[**CLS**],後接單句的組成token,句子對之間用[**SEP**]分隔開,最後[**CLS**]對應位置輸出的向量 $C$ 由於不具備特別的語義特徵,因此能更好地表示整個**句對的語義資訊**。最後, 把第一個起始符號對應的**Transformer**最後一層位置上的輸出 $C$ 串接一個 $\mathbf{softmax}$ 分類層對句對關係進行分類
**(2)單句分類** —— [**CLS**]作為句子開頭,後接單句的組成token,同樣[**CLS**]對應位置輸出的向量 $C$ 後接上一個 $\mathbf{softmax}$分類器對句子進行分類
**(3)問答** —— [**CLS**]作為句子開頭,問題句的組成token和背景文字句的組成token用[**SEP**]隔開,將每個屬於背景句子的token所在對應位置的輸出向量與**Start**向量**做點積算得分**,根據得分確定答案在背景文字中的起始位置,結束位置的確定也是一樣。最後在背景文字中,**起始位置和結束位置之間對應的這段文字就當作問題的最終回答**。
**(4)序列標註** —— [**CLS**]作為句子開頭,後接單句的組成token,將每個token對應位置輸出的向量輸入到一個多分類器中,輸出每個token的標註分類預測。
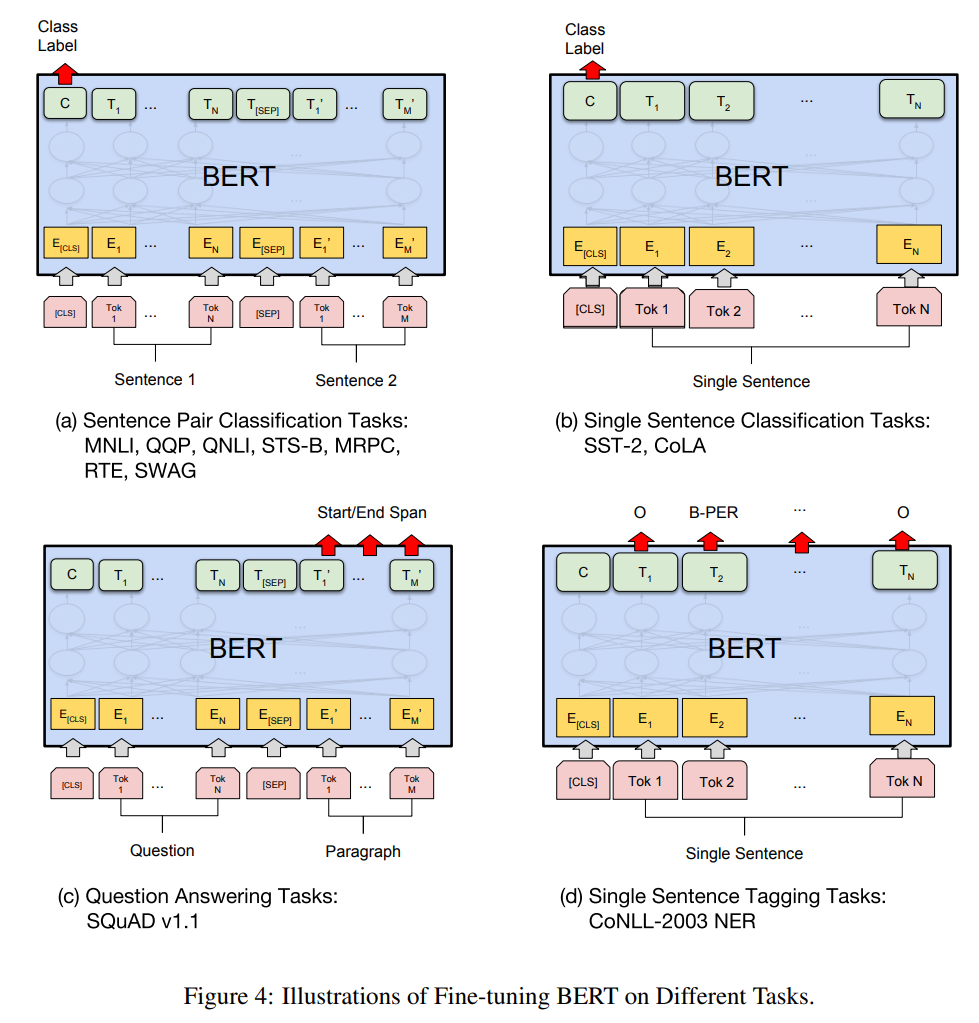
- **特點**
- **MLM**雙向語言模型
- **Transformer**做特徵提取器
- **BERT**輸入部分的處理
**輸入部分是個線性序列**,兩個句子通過分隔符分割,最前面和最後增加兩個識別符號號。每個單詞有三個embedding
(1)**單詞embedding**
預訓練後得到的單詞Embedding。
(2)**位置embedding**
自注意力機制沒有位置概念,每個位置等同看待,為了弄清楚token所在位置,需要引入位置嵌入,告訴模型當前的token處於句子的什麼位置。
(3)**句子embedding**
整個句子的Embedding代表了整個句子的語義資訊,句子嵌入需要給到那個句子中每個token。
**把單詞對應的三個embedding疊加,就形成了Bert的輸入。**
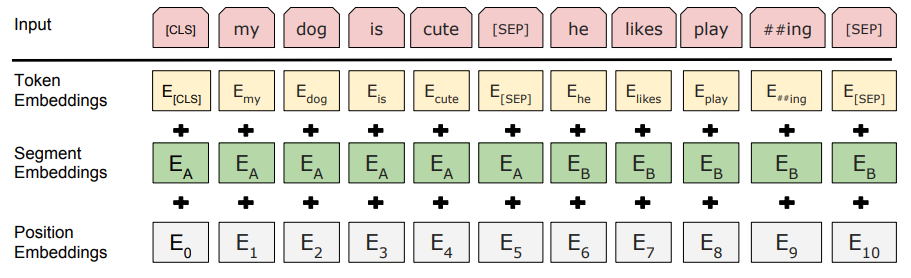
- **不足**
- 同預訓練階段**MLM**模型的缺陷
### 預訓練模型概覽
#### 預訓練任務
##### 語言模型(LM)
語言模型通常特指自迴歸語言模型或者單向語言模型。
- **任務** —— 給定上文,根據緊接著的下一詞彙在詞彙表中的概率分佈輸出更可能的下文,即最大化句子出現的概率。給定一串文字序列 $ x_{1:T} = \left[ x_{1},x_{2}, \dots, x_{T} \right]$,其聯合分佈概率可以表示為如下條件概率的乘積:
$$
p\left(\mathbf{x}_{1: T}\right)=\prod_{t=1}^{T} p\left(x_{t} \mid \mathbf{x}_{0: t-1}\right)
$$
其中,$ x_{0} $ 為起始標記 $[Start]$ 對應的token。上述條件概率 $ p\left(x_{t} \mid \mathbf{x}_{0: t-1}\right)$ 可以通過計算給定語境下(即上文$x_{0:t-1}$) 詞彙表中所有詞的概率分佈來建模,其中,語境上文又可以通過神經編碼器 $ f_{enc}(·)$ 來進行編碼,利用一個預測層 $g_{LM}(·) $ 輸出詞彙表中所有詞在當前位置出現的概率分佈。
$$
p\left(x_{t} \mid \mathbf{x}_{0: t-1}\right)=g_{LM}( f_{enc}(x_{0:t-1}))
$$
當給定一個巨大的語料庫時,可以用最大似然估計來訓練整個網路。
- **缺點** —— 每個token的表示只編碼了上文的token和它自己。然而,更好的文字語境表示應該編碼來自上文和下文兩個方向的上下文資訊。
- **改進** —— 考慮單向LM的缺陷,用兩個單向LM組合起來構成雙向LM(BiLM)。BiLM由兩個單向LM組成:一個向前的從左到右LM和一個向後的從右到左LM。
- **代表模型**
- 單向 —— GPT、GPT2、GPT3
- 雙向 —— ELMO
##### 掩蓋語言模型(MLM)
- **任務** —— 完形填空(cloze task),從文字中的其他詞預測當前被掩蓋位置最可能出現的詞。由於是同時考慮文字的上文和下文對掩蓋詞進行預測,因此MLM很好地克服了標準單向線性模型語境編碼不完全的缺點。
- **缺點** —— 由於MLM首先會從輸入文字中隨機掩蓋掉一些token,然後用其餘的token來預測掩蓋掉的token。因此,這種預訓練方法會在預訓練階段和微調階段之間造成不匹配,因為 $[MASK] $ 不會在微調階段出現。
- **改進** —— 不總是用 $[MASK]$ 進行替換,訓練一個數據生成器
- 在80%的時間內使用特殊的$[MASK]$進行替換
- 在10%的時間內使用隨機的token執行替換
- 在10%的時間內使用原始token來執行替換
- **代表模型** —— BERT及其龐大的BERT家族
##### 排列語言模型(PLM)
雖然MLM效果驚人,但是不能忽視的是,MLM在預訓練中使用的一些特殊標記(如[MASK])在模型應用於下游任務時並不存在,這導致預訓練和微調之間存在差距。為了克服這個問題,提出了排列語言模型PLM。
- **任務** —— 基於輸入序列的隨機排列的語言建模。簡單來說,就是從所有可能的排列中隨機抽樣一個排列。然後,將排列序列中的一些token作為目標,然後訓練模型來預測這些目標。需要注意的是,這種隨機排列不會影響序列的自然位置,僅會定義token預測的順序。
- **代表模型** —— XLNet
##### 去噪自編碼器(DAE)
- **任務** —— 輸入部分損壞的文字,重建原始的未失真的文字。
破壞文字的方式有:
1. token掩蓋:從輸入中隨機取樣token,並用[MASK]替換它們。
2. token刪除:從輸入中隨機刪除token。與掩蓋token不同,模型需要確定缺失輸入的位置。
3. 文字填充:像SpanBERT一樣,許多文字跨度被取樣並用單個[MASK]標記替換。每個跨度長度由泊松分佈(λ = 3)得出。該模型需要預測一個跨度中缺少多少個token。
4. 句子排列:根據句號將文件分成句子,並以隨機順序排列這些句子。
5. 文件翻轉:隨機均勻地選擇一個token,並翻轉文件,使其從該token開始。模型需要識別文件的真正開始位置
##### 比較學習(CL)
- **總體任務** —— 假設一些觀察到的文字對在語義上比隨機抽樣的文字更相似。學習文字對 $(x,y)$ 的得分函式 $s(x,y)$ 以最小化目標函式:
$$
\mathcal{L}_{\mathrm{CTL}}=\mathbb{E}_{x, y^{+}, y^{-}}\left[-\log \frac{\exp \left(s\left(x, y^{+}\right)\right)}{\exp \left(s\left(x, y^{+}\right)\right)+\exp \left(s\left(x, y^{-}\right)\right)}\right]
$$
其中,$(x, y^{+})$ 是更相似的一對,$y^{+}$ 和 $y^{-}$ 分別為正樣本和負樣本。文字對的得分函式 $s(x,y)$ 通常通過訓練神經網路來學習。
訓練的方式有兩種:
1. $s(x, y)=f_{\mathrm{enc}(x)}^{\mathrm{T}} f_{\mathrm{enc}(y)}$
2. $s(x, y)=f_{\text {enc }}(x \oplus y)$
- **代表任務**
- 下一句預測(NSP) —— NSP訓練模型來區分兩個輸入句子是否是來自訓練語料庫的連續片段。具體來說,在為每個預訓練例子選擇句子對時,50%的時候,第二句是第一句的實際下一句,50%的時候,是從語料庫中隨機抽取的一句。通過這樣做,它能夠教模型理解兩個輸入句子之間的關係,從而有利於對該資訊敏感的下游任務,例如問答和自然語言推理。 但是NSP任務的有效性和必要性備受質疑。
- 句子順序預測(SOP) —— 和NSP不同,SOP使用同一文件中的兩個連續片段作為正面示例,使用相同的兩個連續片段,但它們的順序交換作為反面示例。
#### 模型分類
為了闡明自然語言處理中現有預訓練模型之間的關係,可以從四個不同的角度對現有預訓練模型進行分類:
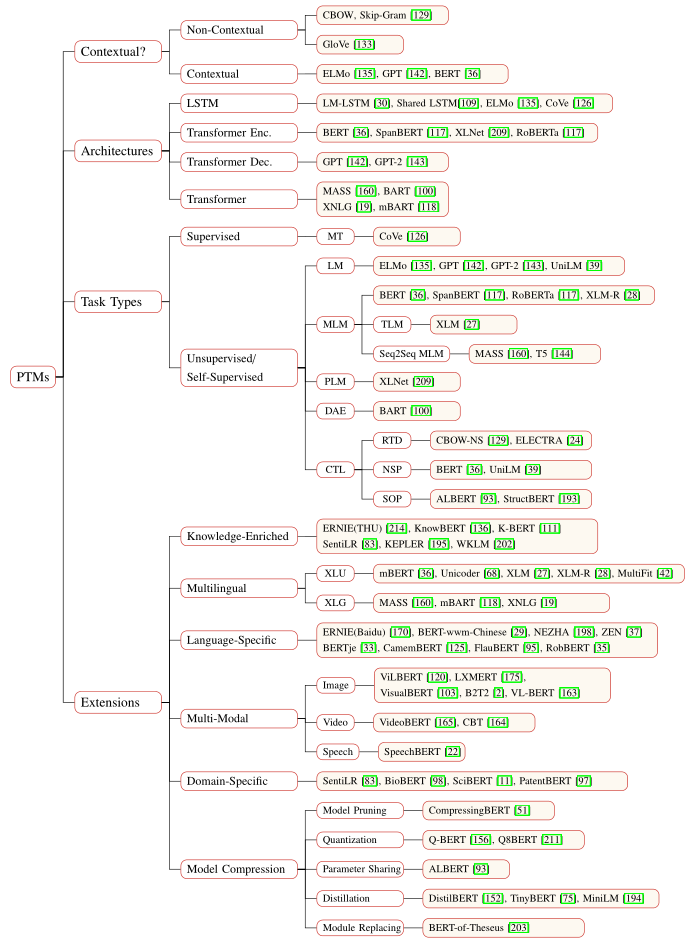
- 表示型別
- 與上下文獨立的表示 —— Word2Vec、Glove等
- 與上下文相關的表示 —— ELMO、GPT、BERT等
- 架構(基礎網路)
- LSTM —— ELMO
- Transformer
- encoder —— BERT
- decoder —— GPT(使用了三角矩陣實現了掩蓋自注意力機制,即不允許模型在預測的時候看到下文)
- full
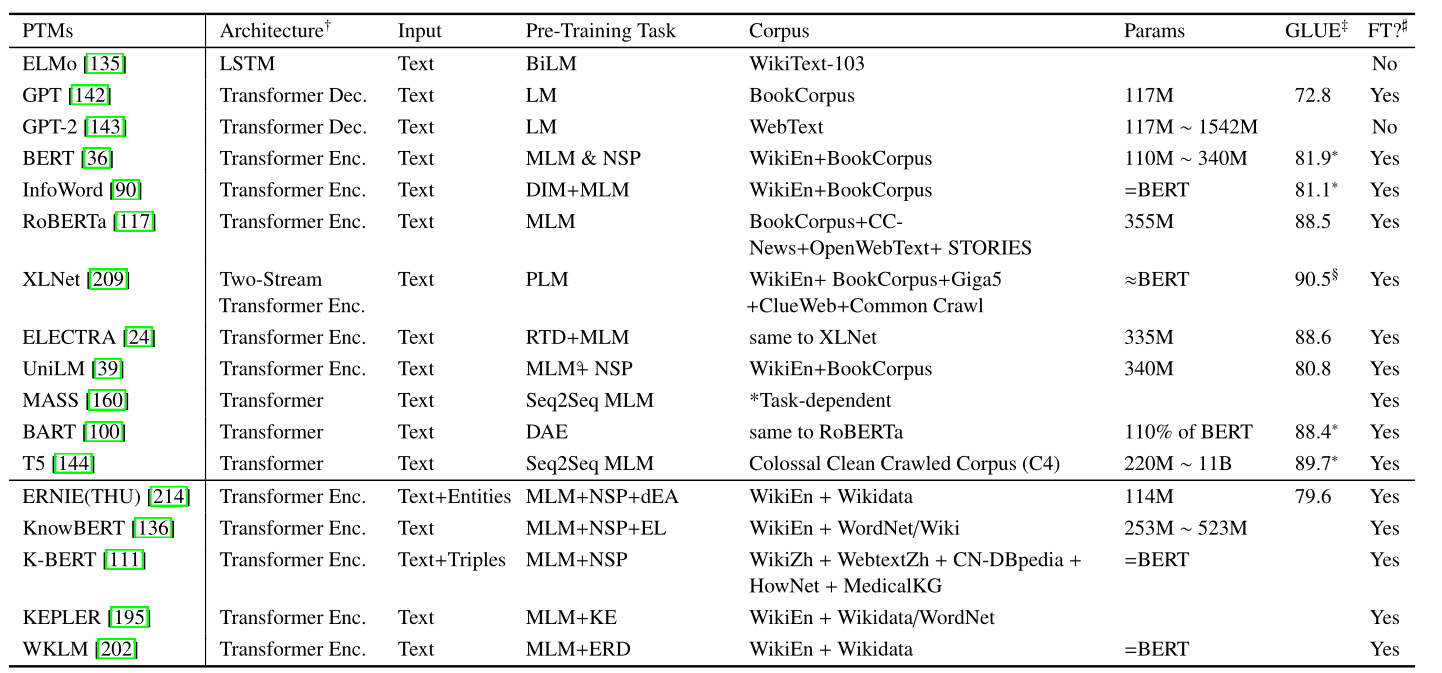
- 預訓練任務
- 監督學習 —— 學習一個函式,該函式基於由輸入輸出對組成的訓練資料將輸入對映到輸出。
- 無監督 —— 從未標記的資料中發現一些內在的知識,如LM。
- 自監督 —— 監督學習和非監督學習的結合,學習正規化和監督學習完全一樣,只是訓練資料的標籤是自動生成的。關鍵思想是從其他部分以某種形式預測輸入的任何部分。如MLM。
- 擴充套件:特定場景下的預訓練模型,包括知識豐富的預訓練模型、多語言或特定語言的預訓練模型、多模型預訓練模型、特定領域的預訓練模型等
#### 模型分析
##### 非上下文詞嵌入
- **思想** —— 通過神經網路語言模型學習的單詞表示能夠捕捉語言中的語言規律,單詞之間的關係可以通過特定關係的向量偏移來表徵。例如,$vec(“China”) − vec(“Beijing”) ≈ vec(“Japan”) −vec(“Tokyo”)$ ,另外,經過神經語言模型訓練得到的詞向量還具有組合性,$vec(“Germany”) + vec(“capital”) ≈ vec(“Berlin”)$。
- **缺點** —— 這種分散式單詞表示擅長預測分類屬性(例如,狗是一種動物),但不能真正學習屬性(例如,天是藍的)。而且,考慮到多義詞需要結合上下文語境進行詞義的判斷,而這種與上下文無關的分散式詞表示往往無法代表詞的正確意思。
##### 上下文詞嵌入
- **思想** —— 在做語言模型任務時,把上下文語境文字融合進詞表示向量,使得詞表示向量能夠蘊含除詞本義之外的上下文語義知識資訊和語言學資訊。
- 語言學資訊 —— 研究人員從BERT中提取依賴樹和支援樹,證明了BERT對語法結構進行編碼的能力。
- 語言特徵似乎表現在單獨的語義和句法子空間中
- 注意矩陣包含語法表徵
- BERT非常精細地區分詞義。
- 語義知識資訊 —— 除了語言知識,預訓練模型還可以儲存訓練資料中呈現的世界知識。探索世界知識的一個簡單方法是用“填空”完形填空語句來查詢BERT,例如,“但丁誕生於[MASK]”。研究人員通過從幾個知識來源手動建立單標記完形填空語句(查詢)來構建LAMA(語言模型分析)任務。他們的實驗表明BERT包含的世界知識比傳統的資訊抽取方法更有競爭力。
### 預訓練模型拓展
#### 基於知識增強
- **思想** —— 將外部知識納入預訓練模型
- **代表模型**
- LIBERT —— 通過額外的語言限制任務整合語言知識
- SentiLR —— 整合每個詞的情感極性,將MLM擴充套件為具有標籤感知能力的MLM(LA-MLM)
- SenseBERT —— 經過預先訓練,不僅可以預測掩碼標記,還可以預測它們在WordNet中的超集。
- ERNIE —— 將預先在知識圖上訓練的實體嵌入與文字中相應的實體提及相結合,以增強文字表示。
- KnowBERT —— 將BERT與實體連結模型結合起來,以端到端的方式整合實體表示。
- K-BERT —— 允許在對下游任務進行微調的過程中注入事實知識。
- 知識-文字融合模型 —— 機器閱讀理解中獲取相關語言和事實知識。
#### 基於多語言和特定語言
- 多語言
- 跨語言理解
- 跨語言生成
- 特定語言
#### 基於多模態
這些多模態模型中的絕大多數是為一般的視覺和語言特徵編碼而設計的。這些模型是在大量跨模態資料的基礎上進行預訓練的(如帶有口語詞的視訊或帶有字幕的影象),並結合擴充套件的預訓練任務來充分利用多模態特徵。
##### 視訊-文字(Video-Text)
視訊分別由基於CNN的編碼器和現成的語音識別技術進行預處理。使用一個單獨的Transformer編碼器在處理過的資料上進行訓練,學習視訊字幕等下游任務的視覺語言表示。代表模型有,VideoBERT和CBT。
##### 影象-文字(Image-Text)
引入影象-文字對,旨在微調下游任務,如視覺問題回答(**VQA**)和視覺常識推理(**VCR**)。
**分類:**
- 採用兩個獨立的編碼器來獨立地表示影象和文字, 例如ViLBERT和LXMERT。
- 使用single-stream unified Transformer,雖然這些模型體系結構不同,但是在這些方法中引入了類似的預訓練任務,例如MLM和影象-文字匹配。例如,VisualBERT,B2T2,VLBERT, Unicoder-VL和UNITER。
##### 音訊-文字(Audio-Text)
SpeechBERT模型試圖用一個Transformer編碼器編碼音訊和文字以建立一個端到端的語音問答(SQA)模型。
#### 基於特定領域與任務
大多數預訓練模型都是在維基百科等通用領域語料庫上進行預訓練的,這限制了它們在特定領域或任務上的應用。
- **訓練特定領域預訓練模型**
- 生物醫學 —— BioBERT
- 科學 —— SciBERT
- 臨床醫學 —— ClinicalBERT
- **利用通用領域預訓練模型適應具體任務**
- 情感分析 —— 感知情感標籤的MLM
- 文字摘要 —— 間歇句生成
- 不流暢檢測 —— 噪聲詞檢測
#### 模型壓縮
- **動機** —— 預訓練模型引數量過於龐大,很難在現實應用和資源受限的裝置上進行部署,因此,如何壓縮模型也成為了研究的一個熱點。
- **模型壓縮方法** —— 一種減小模型尺寸和提高計算效率的潛在方法
- **模型修剪** —— 去除不重要的引數,具體來說,就是去除部分神經網路(如權值、神經元、層、通道、注意頭),從而達到減小模型規模、加快推理時間的效果。修剪選擇和修剪時機的把握有待研究。
- 連線權重量化 —— 用較少的位元表示引數,將精度較高的引數壓縮到較低的精度。
- **引數共享** —— 對於那些相似的模型單元,共享它們的引數。這種方法廣泛應用於CNNs、RNNs和Transformer。例如,ALBERT使用跨層引數共享和因子化嵌入引數化來減少模型的引數。雖然引數數量大大減少,但是ALBERT的訓練和推理時間甚至比標準的BERT還要長。通常,引數共享不會提高推理階段的計算效率。
- **知識提取** —— 在原模型的基礎上,根據原模型的中間結果學習一個更小的模型
- 模組替換 —— 用更緊湊的模組替換原模型具有相似功能的模組。例如使用**Theseus-Compress**,壓縮模型的同時保持98%的模型效能,速度是原來的1.4倍。
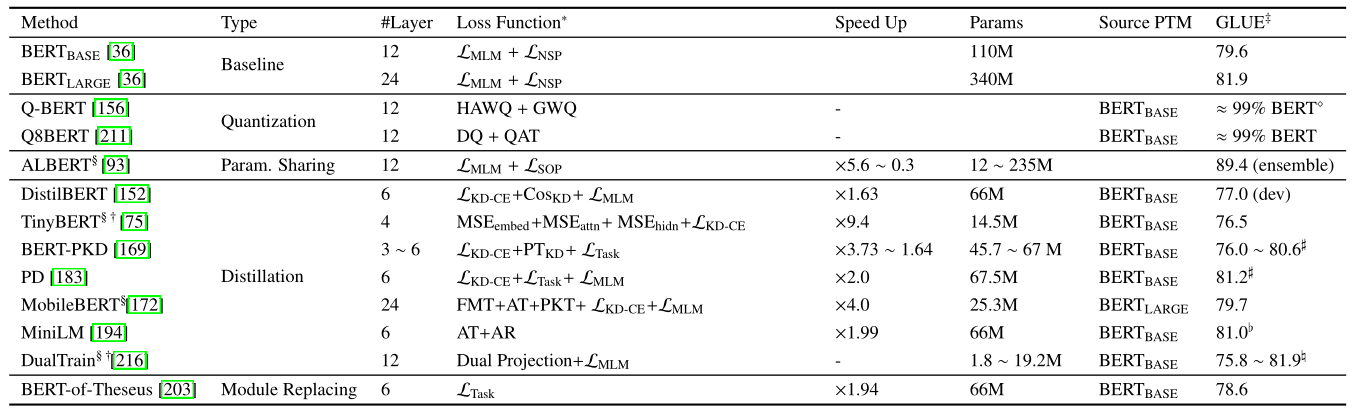
### 預訓練模型應用於下游任務
#### 遷移學習
遷移學習是將知識從源任務(或領域)調整到目標任務(或領域)。
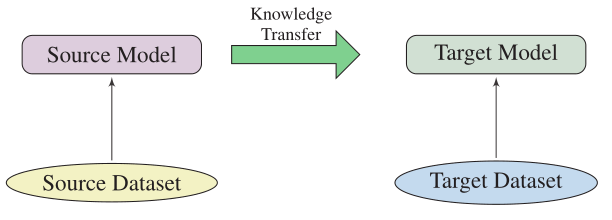
#### 如何遷移
- 選擇合適的預訓練任務、模型架構和語料庫
- 不同的預訓練任務有各自的偏向,對不同的任務有不同的效果。例如,NSP任務使預訓練模型學習了兩句話之間的關係。因此,訓練後的預訓練模型可以受益於問答和自然語言推理(NLI)等下游任務。
- BERT雖然能很好地解決自然語言推理任務,但是很難用於生成式的任務。
- 下游任務的資料分佈應該接近預訓練模型。
- 選擇合適的層
- 給定一個預先訓練的深度模型,不同的層應該捕獲不同種類的資訊,例如詞性標註、解析、長期依賴、語義角色、共指。對於基於RNN的模型,研究表明,多層LSTM編碼器的不同層學習到的表示有益於不同的任務。
- 有三種方法可以選擇表示:
- 只選擇預先訓練的靜態嵌入表示,而模型的其餘部分仍然需要為新的目標任務從頭開始訓練。這些部分無法獲取更高級別的資訊,而這些資訊可能更有用。
- 頂層表示。最簡單有效的方法是將頂層的表示饋入特定任務模型。
- 所有層。更靈活的方法是自動選擇最佳層:
$$
\mathbf{r}_{t}=\gamma \sum_{l=1}^{L} \alpha_{l} \mathbf{h}_{t}^{(l)}
$$
其中,$ \alpha $ 表示 $l$ 層的軟最大歸一化權重,$ \gamma $是縮放預訓練模型輸出的向量的標量。混合表示 $ r_{t} $ 被輸入到特定任務模型中。
#### 微調策略
- **兩階段微調** —— 在第一階段,預訓練模型被轉換成一個由中間任務或語料庫微調的模型。在第二階段,轉移的模型被微調到目標任務。
- **多工微調** —— 多工學習框架下的微調BERT,多工學習和預訓練是互補的技術。
- **使用額外的自適應模組進行微調** —— 微調的主要缺點是引數效率低,每個下游任務都有自己的微調引數。因此,更好的解決方案是在原始引數固定的情況下,往預訓練模型中注入一些可微調的自適應模組。
### 預訓練模型資源
- **預訓練模型的開源實現**
- [word2vec](https://github.com/tmikolov/word2vec)
- [GloVe]( https://nlp.stanford.edu/projects/glove)
- [FastText](https://github.com/facebookresearch/fastText)
- [Transformer](https://github.com/huggingface/transformers)
- [Fairseq](https://github.com/pytorch/fairseq)
- [Flair](https://github.com/flairNLP/flair)
- [AllenNLP](https://github.com/allenai/allennlp)
- [fastNLP](https://github.com/fastnlp/fastNLP)
- [UniLMs](https://github.com/microsoft/unilm)
- [Chinese-BERT](https://github.com/ymcui/Chinese-BERT-wwm)
- [BERT](https://github.com/google-research/bert)
- [RoBERTa](https://github.com/pytorch/fairseq/tree/master/examples/roberta)
- [XLNet](https://github.com/zihangdai/xlnet/)
- [ALBERT](https://github.com/google-research/ALBERT)
- [T5](https://github.com/google-research/text-to-text-transfer-transformer)
- [ERNIE](https://github.com/PaddlePaddle/ERNIE)
- [CTRL](https://github.com/salesforce/ctrl)
- [BertViz](https://github.com/jessevig/bertviz)
- [exBERT](https://github.com/bhoov/exbert)
- [TextBrewer](https://github.com/airaria/TextBrewer)
- [DeepPavlov](https://github.com/deepmipt/DeepPavlov)
- 語料庫
- [OpenWebText](https://github.com/jcpeterson/openwebtext)
- [Common Crawl](http://commoncrawl.org/)
- [WikiEn](https://dumps.wikimedia.org/enwiki/)
### 未來方向
- 預訓練模型還未到達上限 —— 模型可以通過更多的訓練步驟和更大的語料庫來進一步改進。
- 預訓練模型架構優化 —— 為預訓練模型尋找更有效的模型架構對於獲取更大範圍的上下文資訊非常重要。深度架構的設計具有挑戰性,可能會尋求一些自動化方法的幫助,比如神經架構搜尋。
- 面向任務的預訓練和模型壓縮
- 實現超越微調的知識轉移
- 提高預訓練模型的可解釋性和可靠性
### 參考資料
[1] Qiu X, Sun T, Xu Y, et al. Pre-trained models for natural language processing: A survey[J]. arXiv preprint arXiv:2003.08271, 2020.
[2] Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
[3] Radford A, Narasimhan K, Salimans T, et al. Improving language understanding by generative pre-training[J]. 2018.
[4] Yang Z, Dai Z, Yang Y, et al. Xlnet: Generalized autoregressive pretraining for language understanding[C]//Advances in neural information processing systems. 2019: 5753-5763.
[5] [從Word Embedding到Bert模型—自然語言處理中的預訓練技術發展史 by 張俊林](https://zhuanlan.zhihu.com/p/49