
KNN 演算法-理論篇-如何給電影進行分類
阿新 • • 發佈:2020-12-02
> **公號:碼農充電站pro**
> **主頁:**
**KNN 演算法**的全稱是**K-Nearest Neighbor**,中文為**K 近鄰**演算法,它是基於**距離**的一種演算法,簡單有效。
**KNN 演算法**即可用於分類問題,也可用於迴歸問題。
### 1,準備電影資料
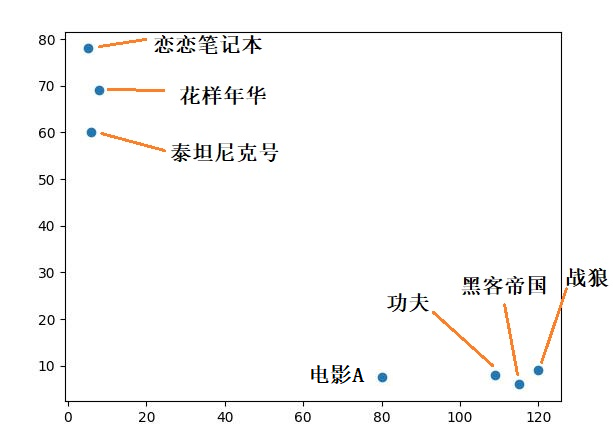
假如我們統計了一些**電影資料,包括電影名稱,打鬥次數,接吻次數,電影型別**,如下:
| 電影名稱 | 打鬥次數 | 接吻次數 | 電影型別 |
|--|--|--|--|
| 黑客帝國 | 115 | 6 | 動作片 |
| 功夫 | 109 | 8 | 動作片 |
| 戰狼 | 120 | 9 | 動作片 |
| 戀戀筆記本 | 5 | 78 | 愛情片 |
| 泰坦尼克號 | 6 | 60 | 愛情片 |
| 花樣年華 | 8 | 69 | 愛情片 |
可以看到,電影分成了兩類,分別是動作片和愛情片。
### 2,用KNN 演算法處理分類問題
如果現在有一部新的電影A,它的打鬥和接吻次數分別是80 和7,那如何用KNN 演算法對齊進行分類呢?
我們可以將打鬥次數作為**X 軸**,接吻次數作為**Y 軸**,將上述電影資料畫在一個座標系中,如下:
>