
日常分享:關於時間複雜度和空間複雜度的一些優化心得分享(C#)
前言
今天分享一下日常工作中遇到的效能問題和解決方案,比較零碎,後續會持續更新(執行環境為.net core 3.1)
本次分享的案例都是由實際生產而來,經過簡化後作為舉例
Part 1(作為簡單資料載體時class和struct的效能對比)
關於class和struct的區別,根據經驗,在實際開發的絕大多數場景,都會使用class作為資料型別,但是如果是作為簡單資料的超大集合的型別,並且不涉及到拷貝、傳參等其他操作的時候,可以考慮使用struct,因為相對於引用型別的class分配在堆上,作為值型別的struct是分配在棧上的,這樣就擁有了更快的建立速度和節約了指標的空間,列舉了3000萬個元素的集合分別以class和struct作為型別,做如下測試(測試工具為vs自帶的 Diagnostic Tools):
class Program {
static void Main (string[] args) {
var structs = new List<StructTest> ();
var stopwatch1 = new Stopwatch ();
stopwatch1.Start ();
for (int i = 0; i < 30000000; i++) {
structs.Add (new StructTest { Id = i, Value = i });
}
stopwatch1.Stop ();
var structsTotalMemory = GC.GetTotalMemory (true);
Console.WriteLine ($"使用結構體時消耗記憶體:{structsTotalMemory}位元組,耗時:{stopwatch1.ElapsedMilliseconds}毫秒");
Console.ReadLine ();
}
public struct StructTest {
public int Id { get; set; }
public int Value { get; set; }
}
}

class Program {
static void Main (string[] args) {
var classes = new List<ClassTest> ();
var stopwatch2 = new Stopwatch ();
stopwatch2.Start ();
for (int i = 0; i < 30000000; i++) {
classes.Add (new ClassTest { Id = i, Value = i });
}
stopwatch2.Stop ();
var classesTotalMemory = GC.GetTotalMemory (true);
Console.WriteLine ($"使用類時消耗記憶體:{classesTotalMemory}位元組,耗時:{ stopwatch2.ElapsedMilliseconds}毫秒");
Console.ReadLine ();
}
public struct StructTest {
public int Id { get; set; }
public int Value { get; set; }
}
}

通過計算,struct的空間消耗包含了:每個結構體包含兩個存放在棧上的整型,每個整型佔4個位元組,每個結構體佔8位元組,乘以3000萬個元素共計佔用240,000,000位元組, 跟實際測量值大體吻合;
而class的空間消耗較為複雜,包含了:每個類包含兩個存在堆上的整型,每個整型佔4位元組,兩個存在棧上的指標,因為是64位計算機所以每個指標佔8位元組,再加上類自身的指標8位元組,每個類佔24位元組(4+4+8+8+8),乘以3000萬個元素共計佔用960,000,000位元組,跟實際測量值大體吻合。時間消耗方面class因為存在記憶體分配,耗時5秒左右,遠大於struct的1.5秒。
基於此次測試,
更多關於class和struct的關係和區別請移步微軟官方文件 https://docs.microsoft.com/en-us/dotnet/standard/design-guidelines/choosing-between-class-and-struct
Part 2(集合巢狀遍歷的優化)
關於巢狀集合遍歷,我們以兩層集合巢狀遍歷,每個集合存放10000個亂序的整型,然後統計同時存在兩個集合的元素個數,從上到下分別以常規巢狀迴圈,使用HashSet型別,參考PostgreSQL的MergeJoin思路舉例:
class Program {
static void Main (string[] args) {
var l1s = new List<int> ();
var l2s = new List<int> ();
var rd = new Random ();
for (int i = 0; i < 10000; i++) {
l1s.Add (rd.Next (1, 10000));
l2s.Add (rd.Next (1, 10000));
}
var sw = new Stopwatch ();
sw.Start ();
var r = new HashSet<int> ();
foreach (var l1 in l1s) {
foreach (var l2 in l2s) {
if (l1 == l2) {
r.Add (l1);
}
}
}
sw.Stop ();
Console.WriteLine ($"共找到{r.Count}個元素同時存在於l1s和l2s,共計耗時{sw.ElapsedMilliseconds}毫秒");
Console.ReadLine ();
}

class Program {
static void Main (string[] args) {
var l1s = new HashSet<int> ();
var l2s = new HashSet<int> ();
var rd = new Random ();
while (l1s.Count < 10000)
l1s.Add (rd.Next (1, 100000));
while (l2s.Count < 10000)
l2s.Add (rd.Next (1, 100000));
var sw = new Stopwatch ();
sw.Start ();
var r = new List<int> ();
foreach (var l1 in l1s) {
if (l2s.Contains (l1)) {
r.Add (l1);
}
}
sw.Stop ();
Console.WriteLine ($"共找到{r.Count}個元素同時存在於l1s和l2s,共計耗時{sw.ElapsedMilliseconds}毫秒");
Console.ReadLine ();
}
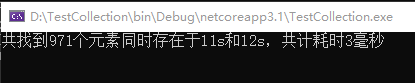
class Program {
static void Main (string[] args) {
var l1s = new List<int> ();
var l2s = new List<int> ();
var rd = new Random ();
for (int i = 0; i < 10000; i++) {
l1s.Add (rd.Next (1, 10000));
l2s.Add (rd.Next (1, 10000));
}
var sw = new Stopwatch ();
sw.Start ();
var r = new List<int> ();
l1s = l1s.OrderBy (x => x).ToList ();
l2s = l2s.OrderBy (x => x).ToList ();
var l1index = 0;
var l2index = 0;
for (int i = 0; i < 10000; i++) {
var l1v = l1s[l1index];
var l2v = l2s[l2index];
if (l1v == l2v) {
r.Add (l1v);
l1index++;
l2index++;
}
if (l1v > l2v && l2index < 10000)
l2index++;
if (l1v < l2v && l1index < 10000)
l1index++;
if (l1index == 9999 && l2index == 9999)
break;
}
sw.Stop ();
Console.WriteLine ($"共找到{r.Count}個元素同時存在於l1和l2s,共計耗時{sw.ElapsedMilliseconds}毫秒");
Console.ReadLine ();
}

由結果可見,常規巢狀遍歷耗時1秒,時間複雜度為O(n2);使用HashSet耗時3毫秒,HashSet底層使用了雜湊表,通過迴圈外層集合,對內層集合直接進行hash查詢,時間複雜度為O(n); 參考PostgreSQL的MergeJoin思路實現耗時19毫秒,方法為先對集合進行排序,再標記當前位移,利用陣列可以下標直接取值的特性取值後對比,時間複雜度為O(n)。由此可見,對於資料量較大的集合,巢狀迴圈要尤為重視起來。
更多關於merge join的設計思路請移步PostgreSQL的官方文件 https://www.postgresql.org/docs/12/planner-optimizer.html
要注意的是,無論是使用雜湊表還是排序,都會引入額外的損耗,畢竟在計算機的世界裡,要麼以時間換空間,要麼以空間換時間,如果想同時優化時間或空間可以辦到嗎?在某些場景上也是有可能的,可以參考我之前的博文,通過記憶體對映檔案結合今天講的內容,結合具體業務場景嘗試一下。
如有任何問題,歡迎大家隨時指正,分享和試錯也是個學習的過程,謝謝大家~
&n