
線性模型的概率分析
拋出問題:為什麽前面的線性回歸要用最小二乘法?為什麽要用這樣的指標?
下面我們會給出一系列的概率假設,從而導出最小二乘法是一個很自然的算法:
先設 y^(i) = θTx^(i) + ε(i), 其中ε(i)叫做誤差項 error term,這個可以看作是對未建模的效應的捕獲,簡單的說就是沒有考慮到的特征,像預測房子中的這個房子有沒有花園,房子的噪音多不多什麽的,這些特征我們沒有考慮到,但它對預測結果又確實有影響。
又假設這個ε(i)服從某個概率分布 ε(i)~N(0,σ^2),——即它服從正態分布,均值為0,方差為σ^2
於是根據正正態分布的概率密度函數就有: 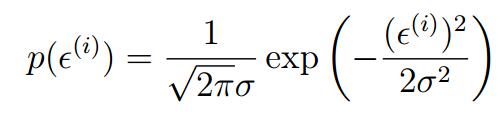
將現行回歸方程代入我們可以得到(因為這個誤差值是服從正態分布的,所以房屋的價格也服從正態分布,所以它的概率密度函數也是):
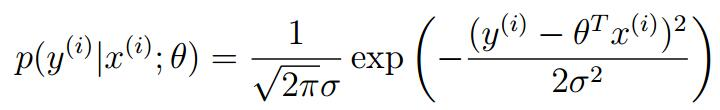
也即:
y(i) | x(i);θ ~N(θTx^(i),σ^2)
這個表示這是給一個x^(i)以θ為參數的y^(i)的分布。註意θ不能當作條件,因為它不是個隨機變量,它是個參數。
又假設這個error terms ,誤差項之間是彼此獨立的
現在定義一個θ參數的函數,似然函數L(θ) (likehood function)
L(θ) = L(θ;X,~y) = p(~y|X;θ),因為那個誤差項的獨立分布,我們可以把它寫成:
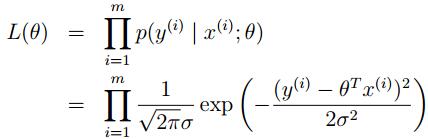 即高斯密度函數的乘積
即高斯密度函數的乘積
L(θ)似然性和概率其實差不多,只是L(θ)強調是個關於θ的函數,所以要註意這個語句的正確,是參數的似然性和數據的概率。
接下來就是選擇θ的問題了,現在我們要做的是maximize L(θ),即選擇θ使數據出現的可能性盡可能大
為了數學上的便利,現在又定義 ?(θ):
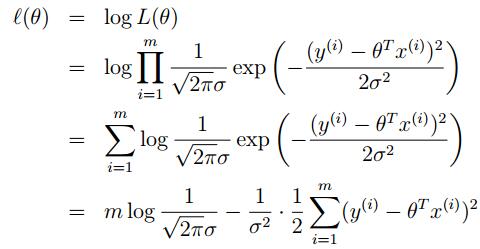
此時,要maxmize 這個L(θ)也就是要minimizing這個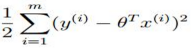 最小,看著玩意是不是很眼熟!!這就是我們之前的線性回歸函數J(θ)!
最小,看著玩意是不是很眼熟!!這就是我們之前的線性回歸函數J(θ)!
其實講了這麽多就是為了證明之前的那個普通最小二乘法的目的實際上是假設誤差項滿足高斯分布且獨立分布的情況下。
線性模型的概率分析