
Precision、Recall、Hamming loss、AP、MAP概念區分
Precision,準確率/查準率。Recall,召回率/查全率。這兩個指標分別以兩個角度衡量分類系統的準確率。
例如,有一個池塘,裏面共有1000條魚,含100條鯽魚。機器學習分類系統將這1000條魚全部分類為“不是鯽魚”,那麽準確率也有90%(顯然這樣的分類系統是失敗的),然而查全率為0%,因為沒有鯽魚樣本被分對。這個例子顯示出一個成功的分類系統必須同時考慮Precision和Recall,尤其是面對一個不平衡分類問題。
下圖為混淆矩陣,摘自wiki百科:
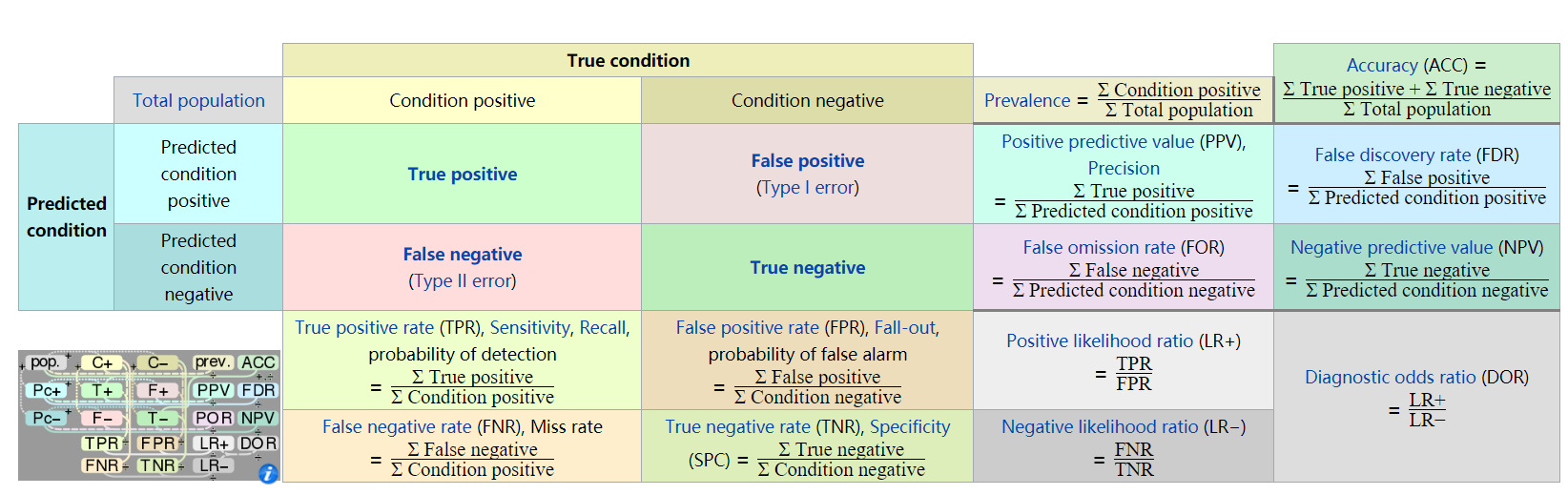
根據上圖,Precision和Recall的計算公式分別為:
\[Precision{\rm{ = }}\frac{{{\rm{TP}}}}{{{\rm{TP + FP}}}}\]
\[Recall{\rm{ = }}\frac{{{\rm{TP}}}}{{{\rm{TP + FN}}}}\]
Precision、Recall、Hamming loss、AP、MAP概念區分
相關推薦
Precision、Recall、Hamming loss、AP、MAP概念區分
blank 衡量 分類問題 images 然而 nbsp ges 一個 rac Precision,準確率/查準率。Recall,召回率/查全率。這兩個指標分別以兩個角度衡量分類系統的準確率。 例如,有一個池塘,裏面共有1000條魚,含100條鯽魚。機器學習分類系統將這
評估指標:ROC,AUC,Precision、Recall、F1-score
rect errors cor http mis dict edi 技術 評價 一、ROC,AUC ROC(Receiver Operating Characteristic)曲線和AUC常被用來評價一個二值分類器(binary classifier)的優劣 。 ROC曲
AUC、Precision、Recall、F-measure、Accuracy
機器學習常見評價指標:AUC、Precision、Recall、F-measure、Accuracy 主要內容 AUC的計算 Precision、Recall、F-measure、Accuracy的計算
分類問題的幾個評價指標(Precision、Recall、F1-Score、Micro-F1、Macro-F1
轉自 https://blog.csdn.net/sinat_28576553/article/details/80258619 四個基本概念TP、True Positive 真陽性:預測為正,實際也為正 FP、False Positive 假
吳恩達機器學習(九)Precision、Recall、F-score、TPR、FPR、TNR、FNR、AUC、Accuracy
目錄 0. 前言 學習完吳恩達老師機器學習課程的機器學習系統設計,簡單的做個筆記。文中部分描述屬於個人消化後的理解,僅供參考。 如果這篇文章對你有一點小小的幫助,請給個關注喔~我會非常開心的~ 0. 前言 針對二分類的結果,對模型進行評估,通常有以下
評測指標Accuracy、Precision、Recall、F1以及AUC值、ROC曲線
準確率、精確率、召回率、F1值、ROC/AUC整理筆記 預測壞 實際壞 —— TP 預測壞 實際好 —— FP 預測好 實際壞 —— FN 預測好 實際好 —— TN 對轉載博文進行總結,主要方便對這些評測標準理解: 1
機器學習評估指標:Precision、recall、F-measure、Accuracy、ROC曲線和AUC
在使用機器學習演算法的過程中,我們需要對建立的模型進行評估來辨別模型的優劣,下文中主要介紹我在學習中經常遇見的幾種評估指標。以下指標都是對分類問題的評估指標。 將標有正負例的資料集餵給模型後,一般能夠得到下面四種情況: True Positive(TP),模型
機器學習常見評價指標:AUC、Precision、Recall、F-measure、Accuracy
1、AUC的計算 AUC是一個模型評價指標,用於二分類模型的評價。AUC是“Area under Curve(曲線下的面積)”的英文縮寫,而這條“Curve(曲線)”就是ROC曲線。 為什麼要用AUC作為二分類模型的評價指標呢?為什麼不直接通過計算準確率來對模型進
機器學習:準確率(Precision)、召回率(Recall)、F值(F-Measure)、ROC曲線、PR曲線
介紹: 準確率(Precision)、召回率(Recall)、F值(F-Measure)是資料探勘、機器學習 和推薦系統中的評測指標。 下圖是不同機器學習演算法的評價指標: 本文的物件是二元分類器! 在 介紹評價指標必須瞭解“混淆矩陣” 混淆矩陣 True Posi
精確率(準確率、查準率、precision)、召回率(查全率、recall)、RoC曲線、AUC面積、PR曲線
精確率(Precision)的定義如下: P=TPTP+FP 召回率(Recall)的定義如下: R=TPTP+FN 特異性(specificity)的定義如下: S=FPFP+TN 有時也用一個F1值來綜合評估精確率和召回率,它是精確率和召回
準確率(Precision查準率)召回率(Recall查全率)和F-Meansure、mAP
某池塘有1400條鯉魚,300只蝦,300只鱉。現在以捕鯉魚為目的。撒一大網,逮著了700條鯉魚,200只蝦,100只鱉。那麼,這些指標分別如下: 正確率 = 700 / (700 + 200 + 100) = 70% 召回率 = 700 / 1400 = 50% F值 = 70% * 50% * 2 /
YOLO-V3計算單類ap、mAP、recall
1 批處理測試圖輸出檢測結果文字 ./darknet detector valid cfg/voc_birds.data cfg/yolov3-voc-birds.cfg backup/yolov3-voc-birds.backup -out "" 以上程式碼是使用的yo
Precision、Recall、F-measure、ROC曲線、AUC理解
首先,在試圖弄懂AUC和ROC曲線之前,一定,一定要徹底理解混淆矩陣的定義!!! 混淆矩陣中有著Positive、Negative、True、False的概念,其意義如下: 稱預測類別為1的為Positive(陽性),預測類別為0的為Negative(陰性)。 預測正確
目標檢測效能評價指標mAP、Precision、Recall、IoU
一、mAP 1. TP,FP,FN,TN (1)TP(True positives):正確劃分正例個數;正->正; (2)FP(False positives):錯誤劃分正例個數;負->正; (3)FN(False negatives):錯誤劃分負例個數;
機器學習常用效能度量中的Accuracy、Precision、Recall、ROC、F score等都是些什麼東西?
一篇文章就搞懂啦,這個必須收藏! 我們以圖片分類來舉例,當然換成文字、語音等也是一樣的。 Positive 正樣本。比如你要識別一組圖片是不是貓,那麼你預測某張圖片是貓,這張圖片就被預測成了正樣本。 Negative 負樣本。比如你要識別一組圖片是不是貓,那麼你預測某張圖片不是貓,這張圖片就被預測成了負
Alink漫談(八) : 二分類評估 AUC、K-S、PRC、Precision、Recall、LiftChart 如何實現
# Alink漫談(八) : 二分類評估 AUC、K-S、PRC、Precision、Recall、LiftChart 如何實現 [TOC] ## 0x00 摘要 Alink 是阿里巴巴基於實時計算引擎 Flink 研發的新一代機器學習演算法平臺,是業界首個同時支援批式演算法、流式演算法的機器學習平
分類模型的F1-score、Precision和Recall 計算過程
# 分類模型的F1分值、Precision和Recall 計算過程 ## 引入 通常,我們在評價classifier的效能時使用的是accuracy 考慮在多類分類的背景下 accuracy = (分類正確的樣本個數) / (分類的所有樣本個數) 這樣做其實看上去也挺不錯的,不過可能會出現一個很嚴重
【安全牛學習筆記】EVIL TWIN AP、ROGUE AP
信息安全 security+ EVIL TWIN AP / ROGUE AP 3vilTwinAttacker git clon
機器學習 損失函數(Loss/Error Function)、代價函數(Cost Function)和目標函數(Objective function)
objective nbsp 單個 bject 定義 body 個人 cti 屬於 損失函數(Loss/Error Function): 計算單個訓練集的誤差 代價函數(Cost Function): 計算整個訓練集所有損失之和的平均值 至於目標函數(Objectiv
ap、map值計算
csdn ucc map 大於 匹配 坐標 輸出 rac 面積 ap:所有圖片某一個類 map:所有圖片所有類的ap的平均 以一個score為閾值,大於score的所有框是假定正確輸出的所有預測,將這些框和gt匹配(iou大於某一個閾值認為匹配成功),得到當前sco