
Precision、Recall、F-measure、ROC曲線、AUC理解
首先,在試圖弄懂AUC和ROC曲線之前,一定,一定要徹底理解混淆矩陣的定義!!!
混淆矩陣中有著Positive、Negative、True、False的概念,其意義如下:
- 稱預測類別為1的為Positive(陽性),預測類別為0的為Negative(陰性)。
- 預測正確的為True(真),預測錯誤的為False(偽)。
對上述概念進行組合,就產生了如下的混淆矩陣:
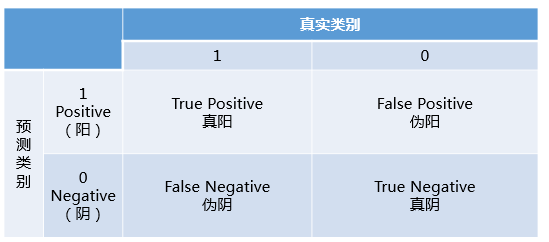
然後,由此引出True Positive Rate(真陽率)、False Positive(偽陽率)兩個概念:
- Precision = TP/TP+FP,預測為真的當中,實際為真的比例(越大越好,1為理想狀態)
- Recall = TPRate,所有真實類別為1的樣本中,預測類別為1的比例,即召回率(召回了多少正樣本比例);
仔細看這兩個公式,發現其實TPRate就是TP除以TP所在的列,FPRate就是FP除以FP所在的列,二者意義如下:
- TPRate的意義是所有真實類別為1的樣本中,預測類別為1的比例。
- FPRate的意義是所有真是類別為0的樣本中,預測類別為1的比例。
- precision的含義是:
如果上述概念都弄懂了,那麼ROC曲線和AUC就so easy了:
按照定義,AUC即ROC曲線下的面積,而ROC曲線的橫軸是FPRate,縱軸是TPRate,當二者相等時,即y=x,如下圖,表示的意義是:
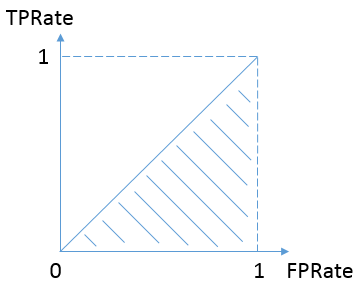
對於不論真實類別是1還是0的樣本,分類器預測為1的概率是相等的。換句話說,和拋硬幣並沒有什麼區別,一個拋硬幣的分類器是我們能想象的最差的情況,因此一般來說我們認為AUC的最小值為0.5(當然也存在預測相反這種極端的情況,AUC小於0.5)。而我們希望分類器達到的效果是:對於真實類別為1的樣本,分類器預測為1的概率(即TPRate),要大於真實類別為0而預測類別為1的概率(即FPRate),這樣的ROC曲線是在y=x之上的,因此大部分的ROC曲線長成下面這個樣子:
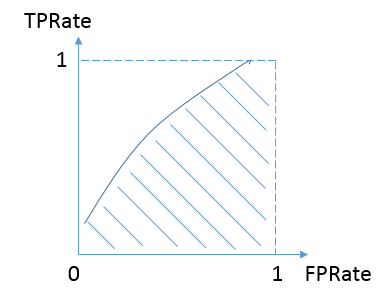
最理想的情況下,沒有真實類別為1而錯分為0的樣本,TPRate一直為1,於是AUC為1,這便是AUC的極大值。
說了這麼多還是不夠直觀,不妨舉個簡單的例子。
首先對於硬分類器(例如SVM,NB),預測類別為離散標籤,對於8個樣本的預測情況如下:

得到混淆矩陣如下:
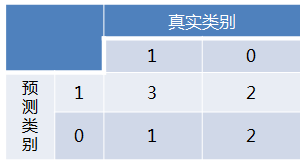
進而算得TPRate=3/4,FPRate=2/4,得到ROC曲線:
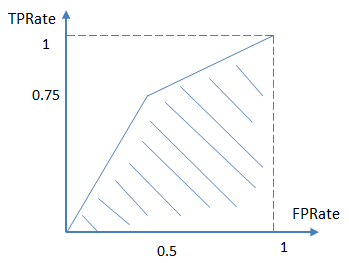
最終得到AUC為0.625。
對於LR等預測類別為概率的分類器,依然用上述例子,假設預測結果如下:

這時,需要設定閾值來得到混淆矩陣,不同的閾值會影響得到的TPRate,FPRate,如果閾值取0.5,小於0.5的為0,否則為1,那麼我們就得到了與之前一樣的混淆矩陣。其他的閾值就不再囉嗦了。依次使用所有預測值作為閾值,得到一系列TPRate,FPRate,描點,求面積,即可得到AUC。
最後說說AUC的優勢,AUC的計算方法同時考慮了分類器對於正例和負例的分類能力,在樣本不平衡的情況下,依然能夠對分類器作出合理的評價。
例如在反欺詐場景,設非欺詐類樣本為正例,負例佔比很少(假設0.1%),如果使用準確率評估,把所有的樣本預測為正例便可以獲得99.9%的準確率。
但是如果使用AUC,把所有樣本預測為正例,TPRate和FPRate同時為1,AUC僅為0.5,成功規避了樣本不均勻帶來的問題。
ROC曲線的Python實現例項
#!/usr/bin/env python
# -*- coding:UTF-8 -*-
import numpy as np
from sklearn.metrics import roc_curve
import matplotlib.pyplot as plt
y = np.array([0,0,1,1])
pred = np.array([0.1,0.4,0.35,0.8])
fpr, tpr, thresholds = roc_curve(y, pred, pos_label=1)
print "fpr:",fpr
print "tpr:",tpr
print "thresholds:",thresholds
#畫對角線
plt.plot([0, 1], [0, 1], '--', color=(0.6, 0.6, 0.6), label='Luck')
#畫ROC曲線
plt.plot(fpr,tpr,lw=1,label = "ROC curve")
plt.show()
from sklearn.metrics import auc
print "auc:",auc(fpr, tpr)
#result
fpr: [ 0. 0.5 0.5 1. ]
tpr: [ 0.5 0.5 1. 1. ]
thresholds: [ 0.8 0.4 0.35 0.1 ]
auc: 0.75
計算過程解析:
測試樣本有真實標籤和預測概率:
| 真實標籤label | 0 | 0 | 1 | 1 |
| 預測概率p | 0.1 | 0.4 | 0.35 | 0.8 |
按預測概率從小到大或從大到小排序,依次選取概率值為閾值。
| 真實標籤label | 1 | 0 | 1 | 0 |
| 預測概率p | 0.8 | 0.4 | 0.35 | 0.1 |
sklearn是按照概率值從大到小排序來計算FTPR和TPR的,本文下面也按照這種排序方式,以便於理解。
當選擇0.8為分隔閾值時,當p>=0.8時,認為該樣本為正樣本,否則為負樣本,結果如下:
| 真實標籤label | 1 | 0 | 1 | 0 |
| 預測標籤: | 1 | 0 | 0 | 0 |
| 預測概率p | 0.8 | 0.4 | 0.35 | 0.1 |
根據混淆矩陣得到
則TP = 1,FN = 1, FP = 0,TN = 2;則計算得到FPR =FP/FP+TN= 0/0+2=0,TPR = TP/TP+FN=1/1+1=0.5.
當選擇0.4為分隔閾值時,當p>=0.4時,認為該樣本為正樣本,否則為負樣本,結果如下:
| 真實標籤label | 1 | 0 | 1 | 0 |
| 預測標籤: | 1 | 1 | 0 | 0 |
| 預測概率p | 0.8 | 0.4 | 0.35 | 0.1 |
則TP = 1,FN = 1, FP = 1,TN = 1;則計算得到FPR =FP/FP+TN= 1/1+1=0.5,TPR = TP/TP+FN=1/1+1=0.5.
當選擇0.35為分隔閾值時,當p>=0.35時,認為該樣本為正樣本,否則為負樣本,結果如下:
| 真實標籤label | 1 | 0 | 1 | 0 |
| 預測標籤: | 1 | 1 | 1 | 0 |
| 預測概率p | 0.8 | 0.4 | 0.35 | 0.1 |
則TP = 2,FN = 0, FP = 1,TN = 1;則計算得到FPR =FP/FP+TN= 1/1+1=0.5,TPR = TP/TP+FN=2/2+0=1.
當選擇0.1為分隔閾值時,當p>=0.1時,認為該樣本為正樣本,否則為負樣本,結果如下:
| 真實標籤label | 1 | 0 | 1 | 0 |
| 預測標籤: | 1 | 1 | 1 | 1 |
| 預測概率p | 0.8 | 0.4 | 0.35 | 0.1 |
則TP = 2,FN = 0, FP = 2,TN = 0;則計算得到FPR =FP/FP+TN= 2/2+0=1,TPR = TP/TP+FN=2/2+0=1.
參考:https://www.zhihu.com/question/39840928/answer/241440370
相關推薦
機器學習評估指標:Precision、recall、F-measure、Accuracy、ROC曲線和AUC
在使用機器學習演算法的過程中,我們需要對建立的模型進行評估來辨別模型的優劣,下文中主要介紹我在學習中經常遇見的幾種評估指標。以下指標都是對分類問題的評估指標。 將標有正負例的資料集餵給模型後,一般能夠得到下面四種情況: True Positive(TP),模型
機器學習:準確率(Precision)、召回率(Recall)、F值(F-Measure)、ROC曲線、PR曲線
介紹: 準確率(Precision)、召回率(Recall)、F值(F-Measure)是資料探勘、機器學習 和推薦系統中的評測指標。 下圖是不同機器學習演算法的評價指標: 本文的物件是二元分類器! 在 介紹評價指標必須瞭解“混淆矩陣” 混淆矩陣 True Posi
Precision、Recall、F-measure、ROC曲線、AUC理解
首先,在試圖弄懂AUC和ROC曲線之前,一定,一定要徹底理解混淆矩陣的定義!!! 混淆矩陣中有著Positive、Negative、True、False的概念,其意義如下: 稱預測類別為1的為Positive(陽性),預測類別為0的為Negative(陰性)。 預測正確
機器學習:準確率(Precision)、召回率(Recall)、F值(F-Measure)、ROC曲線、PR曲線
增注:雖然當時看這篇文章的時候感覺很不錯,但是還是寫在前面,想要了解關於機器學習度量的幾個尺度,建議大家直接看周志華老師的西瓜書的第2章:模型評估與選擇,寫的是真的很好!! 摘要: 資料探勘、機器學習和推薦系統中的評測指標—準確率(Precision)、召回率
精確率(準確率、查準率、precision)、召回率(查全率、recall)、RoC曲線、AUC面積、PR曲線
精確率(Precision)的定義如下: P=TPTP+FP 召回率(Recall)的定義如下: R=TPTP+FN 特異性(specificity)的定義如下: S=FPFP+TN 有時也用一個F1值來綜合評估精確率和召回率,它是精確率和召回
真假正負例、混淆矩陣、ROC曲線、召回率、準確率、F值、AP
[轉自:https://blog.csdn.net/yimingsilence/article/details/53769861] 一、假正例和假負例 假正例(False Positive):預測為1,實際為0的樣本 假負例(False N
xgene:之ROC曲線、ctDNA、small-RNA seq、甲基化seq、單細胞DNA, mRNA
會有 模板 pat 活動 fff 1.5 科學家 因子 染色 靈敏度高 == 假陰性率低,即漏檢率低,即有病人卻沒有發現出來的概率低。 用於判斷:有一部分人患有一種疾病,某種檢驗方法可以在人群中檢出多少個病人來。 特異性高 == 假陽性率低,即錯把健康判定為病人的概率低
機器學習效能度量指標:ROC曲線、查準率、查全率、F1
錯誤率 在常見的具體機器學習演算法模型中,一般都使用錯誤率來優化loss function來保證模型達到最優。 \[錯誤率=\frac{分類錯誤的樣本}{樣本總數}\] \[error_rate=\frac{1}{m} \sum_{i=1}^{m} I(f(x_{i})\neq y_{i})\] 但是錯誤
【深度學習-機器學習】分類度量指標 : 正確率、召回率、靈敏度、特異度,ROC曲線、AUC等
在分類任務中,人們總是喜歡基於錯誤率來衡量分類器任務的成功程度。錯誤率指的是在所有測試樣例中錯分的樣例比例。實際上,這樣的度量錯誤掩蓋了樣例如何被分錯的事實。在機器學習中,有一個普遍適用的稱為混淆矩陣(confusion matrix)的工具,它可以幫助人們更好地瞭解
機器學習中模型的效能度量方式:混淆矩陣,F1-Score、ROC曲線、AUC曲線。
一、混淆矩陣 混淆矩陣也稱誤差矩陣,是表示精度評價的一種標準格式,混淆矩陣的每一列代表了預測類別,每一列的總數表示預測為該類別的資料的數目;每一行代表了資料的真實歸屬類別 ,每一行的資料總數表示該類別的資料例項的數目。每一列中的數值表示真實資料被預測為該類的數目。
分類器評價指標 ROC,AUC,precision,recall,F-score
ROC (Receiver Operating Characteristic) 曲線和 AUC (Area Under the Curve) 值常被用來評價一個二值分類器 (binary classifi
【機器學習】分類效能度量指標 : ROC曲線、AUC值、正確率、召回率、敏感度、特異度
在分類任務中,人們總是喜歡基於錯誤率來衡量分類器任務的成功程度。錯誤率指的是在所有測試樣例中錯分的樣例比例。實際上,這樣的度量錯誤掩蓋了樣例如何被分錯的事實。在機器學習中,有一個普遍適用的稱為混淆矩陣(confusion matrix)的工具,它可以幫助人們
機器學習模型評估混淆矩陣、ROC曲線和AUC以及PR曲線
在機器學習中,當我們基於某個業務建立模型並訓練後,接下來我們需要評判模型好壞的時候需要基於混淆矩陣,ROC和AUC等來進行輔助判斷。 混淆矩陣也叫精度矩陣,是用來表示精度評價,為N *N的矩陣,用來判別分類好壞的指標。 混淆矩陣中有以下幾個概念: TP(T
[總結]ROC曲線、AUC、準確度、召回率
ROC曲線、AUC、準確度、召回率… 混淆矩陣 Label : 1 Label : 0 Estimation: 1 TP(True Positive) Est
對混淆矩陣、F1-Score、ROC曲線、AUC和KS曲線的理解
(一)混淆矩陣 混淆矩陣是除了ROC曲線和AUC之外的另一個判斷分類好壞程度的方法。下面給出二分類的混淆矩陣Predicted as PositivePredicted as NegativeLabeled as Positive True Positive(TP)Fals
斯坦福大學公開課機器學習:machine learning system design | trading off precision and recall(F score公式的提出:學習算法中如何平衡(取舍)查準率和召回率的數值)
ron 需要 color 不可 關系 machine 同時 機器學習 pos 一般來說,召回率和查準率的關系如下:1、如果需要很高的置信度的話,查準率會很高,相應的召回率很低;2、如果需要避免假陰性的話,召回率會很高,查準率會很低。下圖右邊顯示的是召回率和查準率在一個學習算
從roc曲線到auc
1.為什麼我們要用roc曲線進行評價 用傳統的識別率來評價模型的話會有下面的缺陷: 在類不平衡的情況下, 如正樣本90個,負樣本10個,直接把所有樣本分類為正樣本,得到識別率為90% 而如果正樣本識別對75個,負樣本識別對5個,得到的識別率為80%。 但是這樣的識別率評價指標導致高分
ROC曲線及AUC
ROC曲線 意義 ROC曲線指受試者工作特徵曲線 / 接收器操作特性曲線(receiver operating characteristic curve),是反映敏感性和特異性連續變數的綜合指標,是用構圖法揭示敏感性和特異性的相互關係,它通過將連續變數設定出多個不同的臨界值,從而計算出一系列
分類模型的評價指標--混淆矩陣,F1-score,ROC曲線,AUC,KS曲線
1. 混淆矩陣---確定截斷點後,評價學習器效能 TP(實際為正預測為正),FP(實際為負但預測為正),FN(實際為正但預測為負),TN(實際為負預測為負) 通過混淆矩陣我們可以給出各指標的值: 查全率(召回率,Recall):樣本中的正例有多少被預測準確了,衡量的
ROC曲線和AUC
本博文所有理論都是基於二分類,多分類問題其實與二分類問題想通。 1,首先區分什麼是正類什麼是負類。 考慮一個二分問題,如果一類定為正類(positive),那麼另一類就是負類(negative)。 注意和正樣本和負樣本概念不同,參考博文:https://blog.c