
學習中的梯度下降Ⅱ-學習率
調試梯度下降。用x軸上的叠代數繪制一個圖。現在測量成本函數,J(θ)隨叠代次數下降。如果J(θ)不斷增加,那麽你可能需要減少α。
自動收斂試驗。如果該聲明收斂(θ)小於E在一次叠代中減少,其中E是一些小的值,如10?3。然而,在實踐中很難選擇這個閾值。
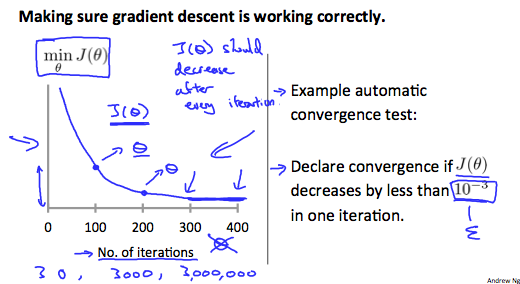
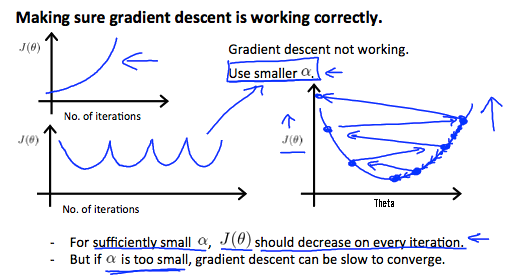
它已被證明,如果學習率α足夠小,那麽J(θ)每次叠代都減小。
總結:
如果α太小,收斂速度慢
如果α太大:?可能不會在每次叠代不收斂,從而降低。
學習中的梯度下降Ⅱ-學習率
相關推薦
機器學習中梯度下降法和牛頓法的比較
在機器學習的優化問題中,梯度下降法和牛頓法是常用的兩種凸函式求極值的方法,他們都是為了求得目標函式的近似解。在邏輯斯蒂迴歸模型的引數求解中,一般用改良的梯度下降法,也可以用牛頓法。由於兩種方法有些相似,我特地拿來簡單地對比一下。下面的內容需要讀者之前熟悉兩種演算
機器學習中梯度下降法原理及用其解決線性迴歸問題的C語言實現
本文講梯度下降(Gradient Descent)前先看看利用梯度下降法進行監督學習(例如分類、迴歸等)的一般步驟: 1, 定義損失函式(Loss Function) 2, 資訊流forward propagation,直到輸出端 3, 誤差訊號back propagation。採用“鏈式法則”,求損失函式關
學習中的梯度下降Ⅱ-學習率
減少 自動 cnblogs 需要 學習 ges com 技術 聲明 調試梯度下降。用x軸上的叠代數繪制一個圖。現在測量成本函數,J(θ)隨叠代次數下降。如果J(θ)不斷增加,那麽你可能需要減少α。 自動收斂試驗。如果該聲明收斂(θ)小於E在一次叠代中減少,其中E是一些小
機器學習之梯度下降法
梯度 學習 模型 最快 參數 nbsp 函數 bsp 每一個 在吳恩達的機器學習課程中,講了一個模型,如何求得一個參數令錯誤函數值的最小,這裏運用梯度下降法來求得參數。 首先任意選取一個θ 令這個θ變化,怎麽變化呢,怎麽讓函數值變化的快,變化的小怎麽變化,那麽函數值怎麽才能
【吳恩達機器學習】學習筆記——梯度下降
得到 向導 bubuko gpo 思路 pos 方向導數 ... image 梯度下降算法能夠幫助我們快速得到代價函數的最小值 算法思路: 以某一參數為起始點 尋找下一個參數使得代價函數的值減小,直到得到局部最小值 梯度下降算法: 重復下式直至收斂,其中α為學習速
機器學習:梯度下降gradient descent
視屏地址:https://www.bilibili.com/video/av10590361/?p=6 引數優化方法:梯度下降法 learning rate learning rate : 選擇rate大小 1、自動調learning ra
機器學習筆記——梯度下降(Gradient Descent)
梯度下降演算法(Gradient Descent) 在所有的機器學習演算法中,並不是每一個演算法都能像之前的線性迴歸演算法一樣直接通過數學推導就可以得到一個具體的計算公式,而再更多的時候我們是通過基於搜尋的方式來求得最優解的,這也是梯度下降法所存在的意義。 不是一個機器學習演
吳恩達機器學習筆記——梯度下降法
1:假設函式的引數更新要做到同時更新,即先將求得的引數放在統一的temp中,然後同時賦值給對應的引數w0,w1,w2,w3..... 2:特徵縮放和收斂速度問題 倘若,特徵向量中一些特徵值相差太大,就會導致代價函式特徵引數的函式曲線很密集,以至於需要多次迭代才能達到最小值。 學習率:決定
機器學習之--梯度下降演算法
貌似機器學習最繞不過去的演算法,是梯度下降演算法。這裡專門捋一下。 1. 什麼是梯度 有知乎大神已經解釋的很不錯,這裡轉載並稍作修改,加上自己的看法。先給出連結,畢竟轉載要說明出處嘛。為什麼梯度反方向是函式值區域性下降最快的方向? 因為高等數學都忘光了,先從導數/偏倒數/方向
【機器學習】梯度下降法詳解
一、導數 導數 就是曲線的斜率,是曲線變化快慢的一個反應。 二階導數 是斜率變化的反應,表現曲線的 凹凸性 y
機器學習3- 梯度下降(Gradient Descent)
1、梯度下降用於求解無約束優化問題,對於凸問題可以有效求解最優解 2、梯度下降演算法很簡單就不一一列,其迭代公式: 3、梯度下降分類(BGD,SGD,MBGD) 3.1 批量梯度下降法(Batch Gradient Descent) 批量梯度下降法,是梯度
影象與機器學習-1-梯度下降法與ubuntu
現值研一,進入了飛行器控制實驗室,在我迷茫不知學什麼的時候,這時候劉洋師兄帶著影象識別與跟蹤這個課題來到了我們面前,師兄傾其所有交給我們學習的方法和步驟與資料,第一節課,師兄給我們講解了影象識別與跟蹤以及機器學習或深度學習的應用和前景以及基本框架和概念。可以說帶領我進入了影象與機器學習的第一步。
有關機器學習的梯度下降演算法
梯度下降演算法是一個一階最優化演算法,通常也稱為最速下降演算法。 要使用梯度下降演算法尋找區域性最小值,必須向函式上當前點對應梯度的反方向進行迭代搜尋。相反地向函式正方向迭代搜尋,則會接近函式的區域性最大值,這個過程被稱為梯度上升法。 梯度下降演算法基於以下的觀
機器學習筆記——梯度下降(Gradient D)
梯度下降演算法(Gradient Descent) 在所有的機器學習演算法中,並不是每一個演算法都能像之前的線性迴歸演算法一樣直接通過數學推導就可以得到一個具體的計算公式,而再更多的時候我們是通過基於搜尋的方式來求得最優解的,這也是梯度下降法所存在的意義。 不
從零開始機器學習002-梯度下降演算法
老師的課程 1.從零開始進行機器學習 2.機器學習數學基礎(根據學生需求不斷更新) 3.機器學習Python基礎 4.最適合程式設計師的方式學習TensorFlow 上節課講完線性迴歸的數學推導,我們這節課說下如何用機器學習的思想把最合適的權重引數求解出來呢?這
人工智障學習筆記——梯度下降(2)優化演算法
四、優化 4-1 Momentum 如果我們把梯度下降法當作小球從山坡到山谷的一個過程,那麼在小球滾動時是帶有一定的初速度,在下落過程,小球積累的動能越來越大,小球的速度也會越滾越大,更快的奔向谷底,受此啟發就有了動量法 Momentum。 動量的引入是為了加速SG
機器學習--監督學習之梯度下降法
最近在看stanford 吳恩達老師的機器學習課程,附上網易公開課的地址http://open.163.com/special/opencourse/machinelearning.html 突然心血
機器學習(7)--梯度下降法(GradientDescent)的簡單實現
曾經在 機器學習(1)--神經網路初探 詳細介紹了神經網路基本的演算法,在該文中有一句weights[i] += 0.2 * layer.T.dot(delta) #0.2學習效率,應該是一個小於0.5的數,同時在 tensorflow例項(2)--機器學習初試
機器學習之梯度下降演算法Gradient Descent
梯度下降演算法: 機器學習實現關鍵在於對引數的磨合,其中最關鍵的兩個數:代價函式J(θ),代價函式對θ的求導∂J/∂θj。 如果知道這兩個數,就能對引數進行磨合了:其中 α 為每步調整的幅度。 其中代價函式公式J(θ): 代價函式對θ的求導∂J/∂θj:
【機器學習】梯度下降演算法分析與簡述
梯度下降演算法分析與簡述 梯度下降(gradient descent)是一種最優化演算法,基於爬山法的搜尋策略,其原理簡單易懂,廣泛應用於機器學習和各種神經網路模型中。在吳恩達的神經網路課程中,梯度下降演算法是最先拿來教學的基礎演算法。 梯度下降演算法的