
邏輯回歸的正則化
我們可以規範logistic回歸以類似的方式,我們對線性回歸。作為一個結果,我們可以避免過擬合。下面的圖像顯示了正則化函數,用粉紅色的線顯示出來,是不太可能過度擬合非正則的藍線表示功能:
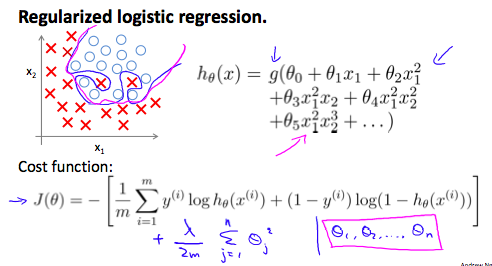
成本函數
![]()
我們可以使這個方程的最後添加一個項:
![]()
第二個和,![]() 意思是明確排除二次項。
意思是明確排除二次項。

邏輯回歸的正則化
相關推薦
吳恩達機器學習 - 邏輯迴歸的正則化 吳恩達機器學習 - 邏輯迴歸的正則化
原 吳恩達機器學習 - 邏輯迴歸的正則化 2018年06月19日 15:07:25 離殤灬孤狼 閱讀數:181 更多
線性迴歸和邏輯迴歸的正則化regularization
線性迴歸 介紹 為了防止過度擬合,正則化是一種不錯的思路。能夠使得獲得的邊界函式更加平滑。更好的模擬現實資料,而非訓練樣本。 方法 可以說,regularization是新增懲罰,使得引數接近於零,
Stanford機器學習---第三週.邏輯迴歸、正則化
第三週 邏輯迴歸與正則化 學完前三週簡要做個總結,梳理下知識框架: 第一講 邏輯迴歸Logistic Regression 1.分類問題Classification Problem for e
Stanford機器學習 第三週:邏輯迴歸與正則化
一、邏輯迴歸 1.1 分類問題 判斷一封電子郵件是否是垃圾郵件;判斷一次金融交易是否是欺詐;判斷腫瘤是惡性的還是良性的等屬於分類問題。 Eg:預測病人的腫瘤是惡性(malignant)還是良性(benign),用線性迴歸的方法擬合一條直線如圖 當hθ大於等於0.5時,預測 y
機器學習入門系列三(關鍵詞:邏輯迴歸,正則化)
一、邏輯迴歸 1.邏輯迴歸 什麼是邏輯迴歸問題,通俗地講就是監督下的分類問題。通過前面的學習,我們已經掌握如何解決線性(非線性)迴歸的問題。那面對分類問題我們是否也可以用線性迴歸呢?簡單起見,我們先討論二元分類,首先讓我們來看一個例子,腫瘤的大小與是否是惡性的關係,其中紅色的×表示腫瘤大小,對應的y軸
邏輯回歸的正則化
正則 .com logistic 可能 cnblogs 技術 技術分享 img 規範 我們可以規範logistic回歸以類似的方式,我們對線性回歸。作為一個結果,我們可以避免過擬合。下面的圖像顯示了正則化函數,用粉紅色的線顯示出來,是不太可能過度擬合非正則的藍線表示功能:
機器學習之路: python線性回歸 過擬合 L1與L2正則化
擬合 python sco bsp orm AS score 未知數 spa git:https://github.com/linyi0604/MachineLearning 正則化: 提高模型在未知數據上的泛化能力 避免參數過擬合正則化常用的方法: 在目
線性回歸 及 正則化 公式推導
tail 損失函數 csdn .net net nbsp art 公式推導 模型 基礎公式: ?BA/?A = BT ?ATB/?A = B ?ATBA/?A = 2BA 模型函數: hθ(x) = xθ 無正則化損失函數: J(θ) = 1/2(Xθ-Y)2
機器學習C6筆記:正則化文本回歸(交叉驗證,正則化,lasso)
非線性模型 廣義加性模型 Generalized Additive Model (GAM)同過使用ggplot2程式包中的geom_smooth函式,使用預設的smooth函式,就可以擬合GAM模型: set.seed(1) x <- se
吳恩達機器學習筆記21-正則化線性回歸(Regularized Linear Regression)
減少 ear 額外 利用 line pan 兩種 方程 res 對於線性回歸的求解,我們之前推導了兩種學習算法:一種基於梯度下降,一種基於正規方程。 正則化線性回歸的代價函數為: 如果我們要使用梯度下降法令這個代價函數最小化,因為我們未對theta0進行正則化,
邏輯回歸--數據獨熱編碼+數據結果可視化
ati values group 歸一化 fix sco value space AD #-*- coding: utf-8 -*- ‘‘‘ 在數據處理和特征工程中,經常會遇到類型數據,如性別分為[男,女](暫不考慮其他。。。。),手機運營商分為[移動,聯通,電信]等,我
資料預處理——標準化、歸一化、正則化
三者都是對資料進行預處理的方式,目的都是為了讓資料便於計算或者獲得更加泛化的結果,但是不改變問題的本質。 標準化(Standardization) 歸一化(normalization) 正則化(regularization) 歸一化 我們在對資料進行分析的時候,往往會遇到單個數據的各個維度量綱不同的
深度學習基礎--正則化與norm--區域性響應歸一化層(Local Response Normalization, LRN)
區域性響應歸一化層(Local Response Normalization, LRN) 區域性響應歸一化層完成一種“臨近抑制”操作,對區域性輸入區域進行歸一化。 該層實際上證明已經沒啥用了,一般也不用了。 參考資料:見郵件 公式與計算 該層需要的引數包括:
批歸一化(Batch Normalization)、L1正則化和L2正則化
from: https://www.cnblogs.com/skyfsm/p/8453498.html https://www.cnblogs.com/skyfsm/p/8456968.html BN是由Google於2015年提出,這是一個深度神經網路訓練的技巧,它不僅可以加快了
吳恩達機器學習邏輯迴歸python實現(未正則化)[對應ex2-ex2data2.txt資料集]
寫在前面: 1.筆記重點是python程式碼實現,不敘述如何推導。參考本篇筆記前,要有邏輯迴歸的基礎(熟悉代價函式、梯度下降、矩陣運算和python等知識),沒有基礎的同學可通過網易雲課堂上吳恩達老師的機器學習課程學習。網上也有一些對吳恩達老師課後作業的python實現,大多數都是用
【轉】關於使用sklearn進行資料預處理 —— 歸一化/標準化/正則化
一、標準化(Z-Score),或者去除均值和方差縮放 公式為:(X-mean)/std 計算時對每個屬性/每列分別進行。 將資料按期屬性(按列進行)減去其均值,並處以其方差。得到的結果是,對於每個屬性/每列來說所有資料都聚集在0附近,方差為1。 實現時,有兩種不同的方式:
歸一化----標準化---正則化----Python的實現
1、(0,1)標準化: from sklearn.preprocessing import MinMaxScaler 這是最簡單也是最容易想到的方法,通過遍歷feature vector裡的每一個列資料,將Max和Min的記錄下來,並通過Max-Min作為基數(即Min=
機器學習中之規範化,中心化,標準化,歸一化,正則化,正規化
一、歸一化,標準化和中心化 歸一化 (Normalization)、標準化 (Standardization)和中心化/零均值化 (Zero-centered) 標準化 資料的標準化(normalization)是將資料按比例縮放(scale),使之落入一個小的特定區間。在某些比較和評價
正則化和歸一化
正則化,歸一化(標準化和正規化):對資料進行預處理的兩種方式,目的是讓資料更便於計算和獲得更加泛化的結果,但並不改變問題的本質。 正則化:要求一個邏輯迴歸問題,假設一個函式,覆蓋所有可能:y=wx,其中w為引數向量,x為已知樣本的向量,用yi表示第i個樣本的真實值,用f
Machine Learning--week3 邏輯迴歸函式(分類)、決策邊界、邏輯迴歸代價函式、多分類與(邏輯迴歸和線性迴歸的)正則化
Classification It's not a good idea to use linear regression for classification problem. We can use logistic regression algorism, which is a classificati