
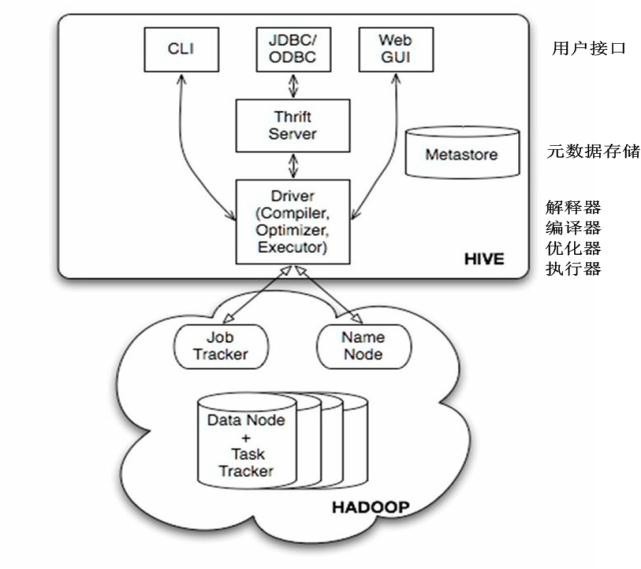
Hive入門小結


hive中可以運行hadoop命令:
create external table mytable2(
id int,
name string)
row format delimited fields terminated by ‘\t‘ location ‘/user/hive/warehouse/mytable2‘;
create table mytable3(
id int,
name string)
partitioned by(sex string) row format delimited fields terminated by ‘\t‘stored as textfile;
靜態分區插入數據
load data local inpath ‘/root/hivedata/boy.txt‘ overwrite into table mytable3 partition(sex=‘boy‘);
增加分區:
alter table mytable3 add partition (sex=‘unknown‘) location ‘/user/hive/warehouse/mytable3/sex=unknown‘;
刪除分區:alter table mytable3 drop if exists partition(sex=‘unknown‘);
分區表默認為靜態分區,可轉換為自動套分區
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
給分區表灌入數據: insert into table mytable3 partition (sex) select id,name,‘boy‘ from student_mdf; 查詢表分區:show partitions mytable3; 查詢分區表數據:select * from mytable3; 查詢表結構:desc mytable3; DML: 重命名表:alter table student rename to student_mdf 增加列:alter table student_mdf add columns (sex string); 修改列名:alter table student_mdf change sex gender string; 替換列結構:alter table student_mdf replace columns (id string, name string); 裝載數據:(本地數據)load data local inpath ‘/home/lym/zs.txt‘ overwrite into student_mdf; (HDFS數據)load data inpath ‘/zs.txt‘ into table student_mdf; 插入一條數據:insert into table student_mdf values(‘1‘,‘zhangsan‘); 創建表接收查詢結果:create table mytable5 as select id, name from mytable3; 導出數據:(導出到本地)insert overwrite local directory ‘/root/hivedata/mytable5.txt‘ select * from mytable5; (導出到HDFS) insert overwrite directory ‘hdfs://master:9000/user/hive/warehouse/mytable5_load‘ select * from mytable5; 數據查詢: select * from mytable3; 查詢全表 select uid,uname from student; 查詢學生表中的學生姓名與學號字段 select uname,count(*) from student group by uname; 統計學生表中每個名字的個數 常用的功能還有 having、order by、sort by、distribute by、cluster by;等等 關聯查詢中有 內連接:將符合兩邊連接條件的數據查詢出來 select * from t_a a inner join t_b b on a.id=b.id; 左外連接:以左表數據為匹配標準,右邊若匹配不上則數據顯示null select * from t_a a left join t_b b on a.id=b.id; 右外連接:與左外連接相反 select * from t_a a right join t_b b on a.id=b.id; 左半連接:左半連接會返回左邊表的記錄,前提是其記錄對於右邊表滿足on語句中的判定條件。 select * from t_a a left semi join t_b b on a.id=b.id; 全連接(full outer join): select * from t_a a full join t_b b on a.id=b.id; in/exists關鍵字(1.2.1之後新特性):效果等同於left semi join select * from t_a a where a.id in (select id from t_b); select * from t_a a where exists (select * from t_b b where a.id = b.id); shell操作Hive指令: -e:從命令行執行指定的HQL:
-f:執行HQL腳本 -v:輸出執行的HQL語句到控制臺
內置函數
用戶向 Sqoop 發起一個命令之後,這個命令會轉換為一個基於 Map Task 的 MapReduce 作業。Map Task 會訪問數據庫的元數據信息,通過並行的 Map Task 將數據庫的數據讀取出來,然後導入 Hadoop 中。 將 Hadoop 中的數據,導入傳統的關系型數據庫中。它的核心思想就是通過基於 Map Task (只有 map)的 MapReduce 作業,實現數據的並發拷貝和傳輸,這樣可以大大提高效率 數據導入:首先用戶輸入一個 Sqoop import 命令,Sqoop 會從關系型數據庫中獲取元數據信息,比如要操作數據庫表的 schema是什麽樣子,這個表有哪些字段,這些字段都是什麽數據類型等。它獲取這些信息之後,會將輸入命令轉化為基於 Map 的 MapReduce作業。這樣 MapReduce作業中有很多 Map 任務,每個 Map 任務從數據庫中讀取一片數據,這樣多個 Map 任務實現並發的拷貝,把整個數據快速的拷貝到 HDFS 上 數據導出:首先用戶輸入一個 Sqoop export 命令,它會獲取關系型數據庫的 schema,建立 Hadoop 字段與數據庫表字段的映射關系。 然後會將輸入命令轉化為基於 Map 的 MapReduce作業,這樣 MapReduce作業中有很多 Map 任務,它們並行的從 HDFS 讀取數據,並將整個數據拷貝到數據庫中 sqoop查詢語句 進入sqoop安裝主目錄:cd /home/lanou/sqoop-1.4.5.bin__hadoop-2.0.4-alpha 將HDFS上的數據導入到MySQL中:bin/sqoop export --connect jdbc:mysql://192.168.2.136:3306/test --username hadoop --password hadoop --table name_cnt --export-dir ‘/user/hive/warehouse/mydb.db/name_cnt‘ --fields-terminated-by ‘\t‘ 將MySQL中的數據導入到HDFS上: bin/sqoop import --connect jdbc:mysql://192.168.2.136:3306/test --username hadoop --password hadoop --table name_cnt -m 1
sqoop:表示sqoop命令
export:表示導出
--connect jdbc:mysql://192.168.2.136:3306/test :表示告訴jdbc,連接mysql的url。
--username hadoop: 連接mysql的用戶名
--password hadoop: 連接mysql的密碼,我這裏省略了
--table name_cnt: 從mysql要導出數據的表名稱
--export-dir ‘/user/hive/warehouse/mydb.db/name_cnt‘ hive中被導出的文件
--fields-terminated-by ‘\t‘: 指定輸出文件中的行的字段分隔符
Hive入門小結