
Hive入門小結轉發
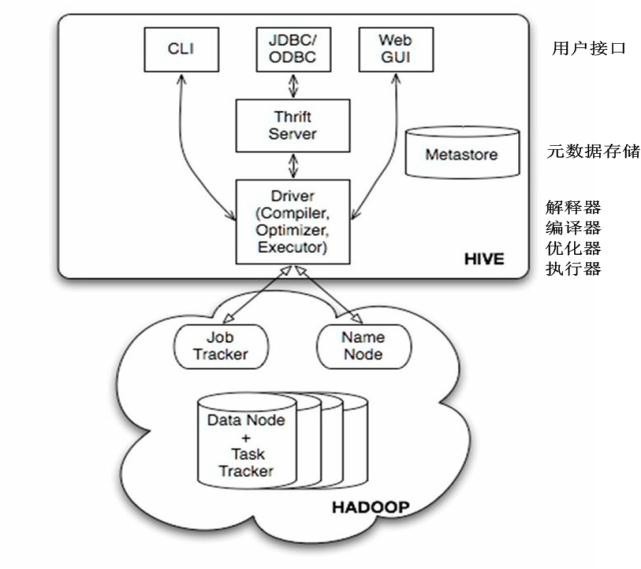 Hive提供了三種使用者介面:CLI、HWI和客戶端。客戶端是使用JDBC驅動通過thrift,遠端操作Hive。HWI即提供Web介面遠端訪問Hive。但是最常見的使用方式還是使用CLI方式。(在linux終端操作Hive)Hive有三種安裝方式:1、內嵌模式(元資料保村在內嵌的derby種,允許一個會話連結,嘗試多個會話連結時會報錯,不適合開發環境) 2、本地模式(本地安裝mysql 替代derby儲存元資料) 3、遠端模式(遠端安裝mysql 替代derby儲存元資料)安裝Hive:(本地模式)首先Hive的安裝是在Hadoop叢集正常安裝的基礎上,並且叢集啟動 安裝Hive之前我們要先安裝mysql, 檢視是否安裝過mysql:rpm -qa|grep mysql* 檢視有沒有安裝包:yum list mysql* 安裝mysql客戶端:yum install -y mysql 安裝伺服器端:yum install -y mysql-server yum install -y mysql-devel 啟動資料庫 service mysqld start或者/etc/init.d/mysqld start 建立hadoop使用者並賦予許可權: mysql>grant all on *.* to
Hive提供了三種使用者介面:CLI、HWI和客戶端。客戶端是使用JDBC驅動通過thrift,遠端操作Hive。HWI即提供Web介面遠端訪問Hive。但是最常見的使用方式還是使用CLI方式。(在linux終端操作Hive)Hive有三種安裝方式:1、內嵌模式(元資料保村在內嵌的derby種,允許一個會話連結,嘗試多個會話連結時會報錯,不適合開發環境) 2、本地模式(本地安裝mysql 替代derby儲存元資料) 3、遠端模式(遠端安裝mysql 替代derby儲存元資料)安裝Hive:(本地模式)首先Hive的安裝是在Hadoop叢集正常安裝的基礎上,並且叢集啟動 安裝Hive之前我們要先安裝mysql, 檢視是否安裝過mysql:rpm -qa|grep mysql* 檢視有沒有安裝包:yum list mysql* 安裝mysql客戶端:yum install -y mysql 安裝伺服器端:yum install -y mysql-server yum install -y mysql-devel 啟動資料庫 service mysqld start或者/etc/init.d/mysqld start 建立hadoop使用者並賦予許可權: mysql>grant all on *.* to 

 hive中的資料型別:原子資料型別:TINYINT SMALLINT INT BIGINT FLOAT DOUBLE BOOLEAN STRING 複雜資料型別:STRUCT MAP ARRAY hive的使用:建表語句:DDL:建立內部表:create table mytable(id int, name string) row format delimited fields terminated by '\t' stored as textfile;常見外部表:關鍵字 external
hive中的資料型別:原子資料型別:TINYINT SMALLINT INT BIGINT FLOAT DOUBLE BOOLEAN STRING 複雜資料型別:STRUCT MAP ARRAY hive的使用:建表語句:DDL:建立內部表:create table mytable(id int, name string) row format delimited fields terminated by '\t' stored as textfile;常見外部表:關鍵字 externalcreate external table mytable2(
id int,
name string)
row format delimited fields terminated by '\t' location '/user/hive/warehouse/mytable2';
create table mytable3(
id int,
name string)
partitioned by(sex string) row format delimited fields terminated by '\t'stored as textfile;
靜態分割槽插入資料
load data local inpath '/root/hivedata/boy.txt' overwrite into table mytable3 partition(sex='boy');
增加分割槽:
alter table mytable3 add partition (sex='unknown') location '/user/hive/warehouse/mytable3/sex=unknown';
刪除分割槽:alter table mytable3 drop if exists partition(sex='unknown');
分割槽表預設為靜態分割槽,可轉換為自動套分割槽
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
給分割槽表灌入資料:insert into table mytable3 partition (sex) select id,name,'boy' from student_mdf;查詢表分割槽:show partitions mytable3;查詢分割槽表資料:select * from mytable3;查詢表結構:desc mytable3;DML:重命名錶:alter table student rename to student_mdf增加列:alter table student_mdf add columns (sex string);修改列名:alter table student_mdf change sex gender string;替換列結構:alter table student_mdf replace columns (id string, name string);裝載資料:(本地資料)load data local inpath '/home/lym/zs.txt' overwrite into student_mdf; (HDFS資料)load data inpath '/zs.txt' into table student_mdf;插入一條資料:insert into table student_mdf values('1','zhangsan');建立表接收查詢結果:create table mytable5 as select id, name from mytable3;匯出資料:(匯出到本地)insert overwrite local directory '/root/hivedata/mytable5.txt' select * from mytable5; (匯出到HDFS)insert overwrite directory 'hdfs://master:9000/user/hive/warehouse/mytable5_load' select * from mytable5;資料查詢: select * from mytable3; 查詢全表select uid,uname from student; 查詢學生表中的學生姓名與學號欄位select uname,count(*) from student group by uname; 統計學生表中每個名字的個數常用的功能還有 having、order by、sort by、distribute by、cluster by;等等關聯查詢中有內連線:將符合兩邊連線條件的資料查詢出來select * from t_a a inner join t_b b on a.id=b.id;左外連線:以左表資料為匹配標準,右邊若匹配不上則資料顯示nullselect * from t_a a left join t_b b on a.id=b.id;右外連線:與左外連線相反select * from t_a a right join t_b b on a.id=b.id;左半連線:左半連線會返回左邊表的記錄,前提是其記錄對於右邊表滿足on語句中的判定條件。select * from t_a a left semi join t_b b on a.id=b.id;全連線(full outer join):select * from t_a a full join t_b b on a.id=b.id;in/exists關鍵字(1.2.1之後新特性):效果等同於left semi joinselect * from t_a a where a.id in (select id from t_b);select * from t_a a where exists (select * from t_b b where a.id = b.id);shell操作Hive指令:-e:從命令列執行指定的HQL: -f:執行HQL指令碼-v:輸出執行的HQL語句到控制檯
-f:執行HQL指令碼-v:輸出執行的HQL語句到控制檯 
內建函式
使用者向 Sqoop 發起一個命令之後,這個命令會轉換為一個基於 Map Task 的 MapReduce 作業。Map Task 會訪問資料庫的元資料資訊,通過並行的 Map Task 將資料庫的資料讀取出來,然後匯入 Hadoop 中。 將 Hadoop 中的資料,匯入傳統的關係型資料庫中。它的核心思想就是通過基於 Map Task (只有 map)的 MapReduce 作業,實現資料的併發拷貝和傳輸,這樣可以大大提高效率資料匯入:首先使用者輸入一個 Sqoop import 命令,Sqoop 會從關係型資料庫中獲取元資料資訊,比如要操作資料庫表的 schema是什麼樣子,這個表有哪些欄位,這些欄位都是什麼資料型別等。它獲取這些資訊之後,會將輸入命令轉化為基於 Map 的 MapReduce作業。這樣 MapReduce作業中有很多 Map 任務,每個 Map 任務從資料庫中讀取一片資料,這樣多個 Map 任務實現併發的拷貝,把整個資料快速的拷貝到 HDFS 上資料匯出:首先使用者輸入一個 Sqoop export 命令,它會獲取關係型資料庫的 schema,建立 Hadoop 欄位與資料庫表字段的對映關係。 然後會將輸入命令轉化為基於 Map 的 MapReduce作業,這樣 MapReduce作業中有很多 Map 任務,它們並行的從 HDFS 讀取資料,並將整個資料拷貝到資料庫中sqoop查詢語句進入sqoop安裝主目錄:cd /home/lanou/sqoop-1.4.5.bin__hadoop-2.0.4-alpha將HDFS上的資料匯入到MySQL中:bin/sqoop export --connect jdbc:mysql://192.168.2.136:3306/test --username hadoop --password hadoop --table name_cnt --export-dir '/user/hive/warehouse/mydb.db/name_cnt' --fields-terminated-by '\t'將MySQL中的資料匯入到HDFS上:bin/sqoop import --connect jdbc:mysql://192.168.2.136:3306/test --username hadoop --password hadoop --table name_cnt -m 1
sqoop:表示sqoop命令
export:表示匯出
--connect jdbc:mysql://192.168.2.136:3306/test :表示告訴jdbc,連線mysql的url。
--username hadoop: 連線mysql的使用者名稱
--password hadoop: 連線mysql的密碼
--table name_cnt: 從mysql要匯出資料的表名稱
--export-dir '/user/hive/warehouse/mydb.db/name_cnt' hive中被匯出的檔案
--fields-terminated-by '\t': 指定輸出檔案中的行的欄位分隔符
 Azkaban使用MySQL去做一些狀態的儲存Azkaban Web服務:Azkaban使用Jetty作為Web伺服器,用作控制器以及提供Web介面AzkabanWebServer對資料庫的使用:專案管理:對專案許可權和上傳檔案的管理;執行流程狀態:對正在執行的程式進行跟蹤;檢視任務執行結果以及歷史日誌;排程程式:保持預定的工作狀態。Azkaban執行伺服器,執行提交的工作流AzkabanExecutorServer 對資料庫的使用:獲取專案:從資料庫中檢索專案檔案;執行工作流或Jobs:從資料庫獲取要執行的任務流;Logs:儲存作業的輸出日誌,並將其流入資料庫;不同的依賴進行交流:如果一個流在不同的執行器上執行,它將從資料庫中獲取狀態安裝Azkaban:1.要先配置mysql。 1.1修改mysql的編碼,vim /etc/my.cnf
Azkaban使用MySQL去做一些狀態的儲存Azkaban Web服務:Azkaban使用Jetty作為Web伺服器,用作控制器以及提供Web介面AzkabanWebServer對資料庫的使用:專案管理:對專案許可權和上傳檔案的管理;執行流程狀態:對正在執行的程式進行跟蹤;檢視任務執行結果以及歷史日誌;排程程式:保持預定的工作狀態。Azkaban執行伺服器,執行提交的工作流AzkabanExecutorServer 對資料庫的使用:獲取專案:從資料庫中檢索專案檔案;執行工作流或Jobs:從資料庫獲取要執行的任務流;Logs:儲存作業的輸出日誌,並將其流入資料庫;不同的依賴進行交流:如果一個流在不同的執行器上執行,它將從資料庫中獲取狀態安裝Azkaban:1.要先配置mysql。 1.1修改mysql的編碼,vim /etc/my.cnf

1.2重啟mysql,service mysqld restart 然後進入mysql,建立azkaban資料庫並授權,重新整理許可權。與建立hive資料庫相同。
2.配置Azkaban Web Server
2.1解壓Azkaban壓縮包 unzip azkaban-web-2.5.0.zip
2.2上傳mysql驅動包
cp mysql-connector-java-5.1.43/mysql-connector-java-5.1.43-bin.jar azkaban-web-2.5.0/extlib/
2.3修改配置檔案
修改azkaban.properties檔案 cd azkaban-web-2.5.0/conf/ vim azkaban.properties
#預設時區改為亞洲/上海 預設為美國
default.timezone.id=Asia/Shanghai
#資料庫連線IP
mysql.host=master
修改檔案許可權: chmod 755 /home/lanou/azkaban/azkaban-web-2.5.0/bin/*
配置jetty ssl:keytool -keystore keystore -alias jetty -genkey -keyalg RSA
Enter keystore password: password
What is your first and last name? 您的名字與姓氏是什麼?
[Unknown]: jetty.mortbay.org
What is the name of your organizational unit?您的組織單位名稱是什麼?
[Unknown]: Jetty
What is the name of your organization?您的組織名稱是什麼?
[Unknown]: Mort Bay Consulting Pty. Ltd.
What is the name of your City or Locality?您所在的城市或區域名稱是什麼?
[Unknown]:
What is the name of your State or Province?您所在的州或省份名稱是什麼?
[Unknown]:
What is the two-letter country code for this unit?該單位的兩字母國家程式碼是什麼
[Unknown]:
Is CN=jetty.mortbay.org, OU=Jetty, O=Mort Bay Consulting Pty. Ltd.,
L=Unknown, ST=Unknown, C=Unknown correct?正確嗎?
[no]: yes
Enter key password for <jetty>
(RETURN if same as keystore password): password
這裡的密碼要與 azkaban-web-2.5.0/conf/azkaban.properties 中設定的密碼相同,否則會報錯Keystore was tampered with, or password was incorrect。
1.job:
type=command
command=hadoop fs -mkdir /test
command.1=hadoop fs -put /home/lym /hadoop-2.7.1/README.txt /test
2.job:
type=command
command=hadoop jar /home/lym/hadoop-2.7.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount /test /test-out
dependencies=1
實現上傳/README.txt並且用wordcount計算
把需要執行的job放在同一個檔案下面打成.zip格式的包,注意 Azkaban目前只支援.zip格式
頁面操作:首先是登陸azkaban;建立一個工程;上傳job;執行job;檢視job執行情況
綠色代表成功,藍色是執行,紅色是失敗。可以檢視job執行時間,依賴和日誌,點選details可以檢視各個job執行情況
Flume Flume是Cloudera提供的日誌收集系統,具有分散式、高可靠、高可用性等特點,對海量日誌採集、聚合和傳輸,Flume支援在日誌系統中制定各類資料傳送,同時,Flume提供對資料進行簡單處理,並寫到各種數接受方的能力。其設計的原理也是基於將資料流,如日誌資料從各種網站伺服器上彙集起來儲存到HDFS,HBase等集中儲存器中。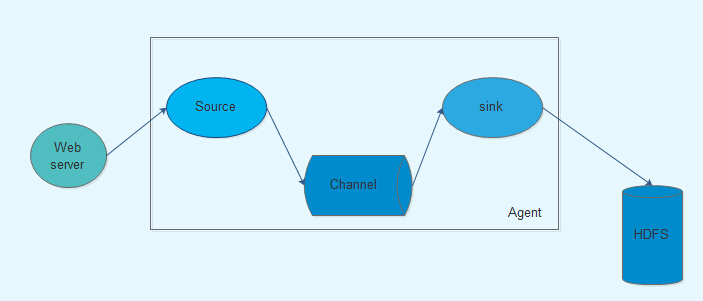
Flume的核心是把資料從資料來源收集過來,在送到目的地,為了保證輸送一定成功,在送到目的地之前,會先快取資料,待資料真正到達目的地後,刪除自己快取的資料
Flume傳輸的資料基本單位是Event,如果是文字檔案,通常是一行記錄,這也是事務的基本單位。Event從Source,流向Channel,再到Sink,本身為一個byte陣列,並可攜帶headers資訊。Event代表著一個數據流的最小完整單元,從外部資料來源來,向外部的目的地去
Flume執行的核心是Agent。它是一個完整的資料收集工具,含有三個核心元件,分別是source、channel、sink。通過這些元件,Event可以從一個地方流向另外一個地方
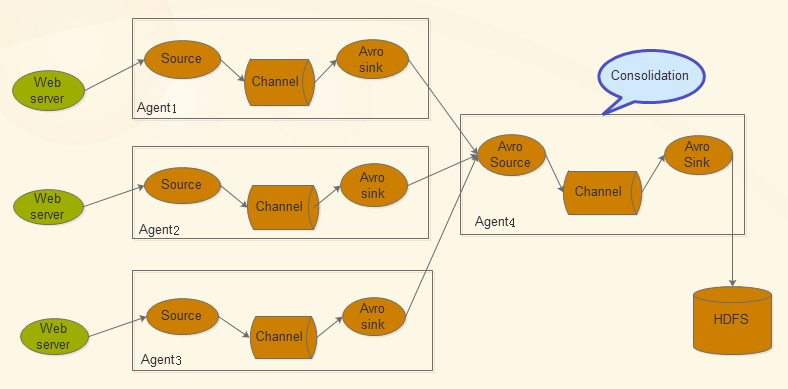
核心元件:source channel sink
source:source負責接收event或通過特殊機制產生event,並將events批量的放到一個或多個channel;source必須至少和一個channel關聯
channel:channel位於source和sink之間,用於快取進來的event;當Sink成功的將event傳送到下一跳的channel或最終目的時候,event從Channel移除
sink:Sink負責將event傳輸到下一跳或最終目的;sink在設定儲存資料時,可以向檔案系統、資料庫、Hadoop存資料,在日誌資料較少時,可以將資料儲存在檔案系中,並且設定一定的時間間隔儲存資料。在日誌資料較多時,可以將相應的日誌資料儲存到hadoop中,便於日後進行相應的資料分析;必須作用於一個確切的channel
安裝部署:
1.下載 http://mirror.bit.edu.cn/apache/flume/1.6.0/
2.解壓 tar -xvf apache-flume-1.6.0-bin.tar.gz tar -xvf apache-flume-1.6.0-src.tar.gz
3.將原始碼合併至安裝目錄apache-flume-1.6.0-bin下:
cp -r apache-flume-1.6.0-src apache-flume-1.6.0-bin/
3.配置環境變數 vim ~/.bash_profile
export FLUME_HOME=/home/lan/apache-flume-1.6.0-bin/
export PATH=$PATH:$FLUME_HOME/bin
4.測試flume-ng是否安裝成功:flume-ng version
測試flume-ng功能:將收集到的日誌輸出到hdfs上為
新建一個flume代理agent1的配置檔案example.conf:
cd apache-flume-1.6.0-bin/conf/ vim example.conf
#agent1
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = c1
#source1
agent1.sources.source1.type = spooldir
agent1.sources.source1.spoolDir = /home/lan/agent1log
agent1.sources.source1.channels = c1
agent1.sources.source1.fileHeader = false
#sink1
agent1.sinks.sink1.type = hdfs
agent1.sinks.sink1.hdfs.path = hdfs://master:9000/agentlog
agent1.sinks.sink1.hdfs.fileType = DataStream
agent1.sinks.sink1.hdfs.writeFormat = TEXT
agent1.sinks.sink1.hdfs.rollInteval = 4
agent1.sinks.sink1.channel = c1
#channel1
agent1.channels.c1.type = file
agent1.channels.c1.checkpointDir = /home/lan/agent1_tmp1
agent1.channels.c1.dataDirs = /home/lan/agent1_tmpdata
#agent1.channels.channel1.capacity = 10000
#agent1.channels.channel.transactionCapacity = 1000
新建agent1log :mkdir agent1log
啟動flume-ng:
cd apache-flume-1.6.0-bin
flume-ng agent -n agent1 -c conf -f /home/lan/apache-flume-1.6.0-bin/conf/example.conf -Dflume.root.logger=DEBUG,console
另啟一個terminal,在監測目錄下建立新的檔案test2.txt
cd ~/agent1log
vim test2.txt
檢視sink1的輸出,發現目標路徑下有一個以FlumeData開始,產生檔案的時間戳為字尾的檔案,說明flume能監測到目標目錄變化,將產生變化的部分實時地收集到sink的輸出中。