
使用sklearn進行K_Means聚類算法
阿新 • • 發佈:2018-05-08
叠代 sta AR distance RM spa verbose TP word
(3)n_init設為10意味著進行10次隨機初始化,選擇效果最好的一種來作為模型;
(4) init=’k-means++’ 會由程序自動尋找合適的n_clusters;
(5)tol:float形,默認值= 1e-4,與inertia結合來確定收斂條件;
(6)n_jobs:指定計算所用的進程數;
(7)verbose 參數設定打印求解過程的程度,值越大,細節打印越多;
(8)copy_x:布爾型,默認值=True。當我們precomputing distances時,將數據中心化會得到更準確的結果。如果把此參數值設為True,則原始數據不會被改變。如果是False,則會直接在原始數據
屬性:

(1)cluster_centers_:向量,[n_clusters, n_features]
Coordinates of cluster centers (每個簇中心的坐標??);
(2)Labels_:每個點的分類;
(3)inertia_:float,每個點到其簇的質心的距離之和。
比如我的某次代碼得到結果:

2、對於非監督機器學習,輸入的數據是樣本的特征,clf.fit(X)就可以把數據輸入到分類器裏。
3、用分類器對未知數據進行分類,需要使用的是分類器的predict方法。
首先附上官網說明
[http://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html#examples-using-sklearn-cluster-kmeans]
再附上一篇翻譯文檔
http://blog.csdn.net/xiaoyi_zhang/article/details/52269242
再給一個百度上找的例子(侵權刪):
# -*- coding: utf-8 -*-
from sklearn.cluster import KMeans
from sklearn.externals import joblib
import numpy
final = open(‘c:/test/final.dat‘ , ‘r‘)
data = [line.strip().split(‘\t‘) for line in final]
feature = [[float(x) for x in row[3:]] for row in data]
#調用kmeans類
clf = KMeans(n_clusters=9)
s = clf.fit(feature)
print s
#9個中心
print clf.cluster_centers_
#每個樣本所屬的簇
print clf.labels_
#用來評估簇的個數是否合適,距離越小說明簇分的越好,選取臨界點的簇個數
print clf.inertia_
#進行預測
print clf.predict(feature)
#保存模型
joblib.dump(clf , ‘c:/km.pkl‘)
#載入保存的模型
clf = joblib.load(‘c:/km.pkl‘)
‘‘‘
#用來評估簇的個數是否合適,距離越小說明簇分的越好,選取臨界點的簇個數
for i in range(5,30,1):
clf = KMeans(n_clusters=i)
s = clf.fit(feature)
print i , clf.inertia_
‘‘‘ - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
初學者講解如下:
參考http://www.cnblogs.com/meelo/p/4272677.html
sklearn對於所有的機器學習算法有一個一致的接口,一般需要以下幾個步驟來進行學習:
1、初始化分類器,根據不同的算法,需要給出不同的參數,一般所有的參數都有一個默認值。 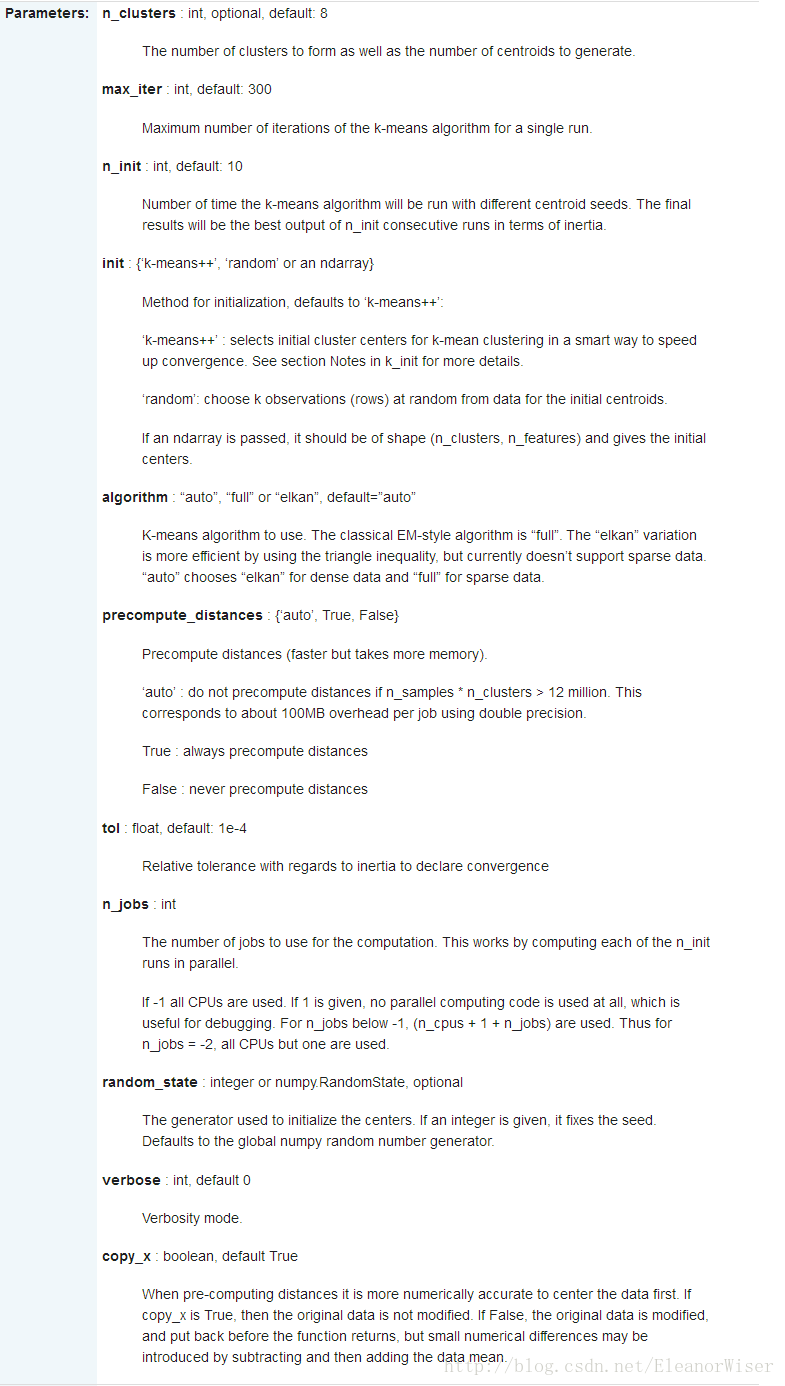
(1)對於K均值聚類,我們需要給定類別的個數n_cluster,默認值為8;
(3)n_init設為10意味著進行10次隨機初始化,選擇效果最好的一種來作為模型;
(4) init=’k-means++’ 會由程序自動尋找合適的n_clusters;
(5)tol:float形,默認值= 1e-4,與inertia結合來確定收斂條件;
(6)n_jobs:指定計算所用的進程數;
(7)verbose 參數設定打印求解過程的程度,值越大,細節打印越多;
(8)copy_x:布爾型,默認值=True。當我們precomputing distances時,將數據中心化會得到更準確的結果。如果把此參數值設為True,則原始數據不會被改變。如果是False,則會直接在原始數據
屬性:
(1)cluster_centers_:向量,[n_clusters, n_features]
Coordinates of cluster centers (每個簇中心的坐標??);
(2)Labels_:每個點的分類;
(3)inertia_:float,每個點到其簇的質心的距離之和。
比如我的某次代碼得到結果:
2、對於非監督機器學習,輸入的數據是樣本的特征,clf.fit(X)就可以把數據輸入到分類器裏。
3、用分類器對未知數據進行分類,需要使用的是分類器的predict方法。
使用sklearn進行K_Means聚類算法