
Multi-Layer Neural Network
Multi-Layer Neural Network
http://blog.csdn.net/surgewong
接觸機器學習有一段時間了,但是對於神經網路一直感覺比較“神祕”,再加之深度學習的概念炒得這麼熱,都不好意思說自己不懂神經網路了。本文主要是為了記錄自己對神經網路的理解以及一些心得,由於是一個新手,其中的一些理解不免有些錯誤,望各位能夠指正。本文主要參考 UFLDL Tutorial的同名教程【1】,在理解過程中主要參考了部落格,反向傳播BP演算法【2】。正如【2】所說【1】中變數的上下標比較多,理解起來可能有些不便,記得耐心看下去哦。
一、初識神經網路
給出一個監督學習的問題,輸入一系列的帶標籤的形如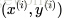
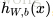
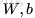
先了解一下單個神經元(neuron)的網路。其實邏輯迴歸(Logistic Regression )(不熟悉的同學可以參考【3】),就是一個單神經元網路。
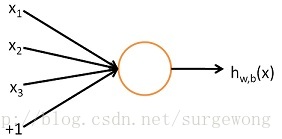
上面的“網路”結構,輸入3個變數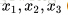
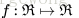
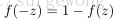
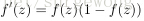
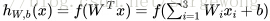
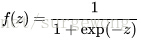
剛接觸神經網路不久,對一些習以為常的概念感覺有點疑惑,在這裡記下自己對其的理解。上面用到公式 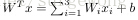
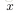
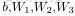
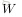
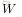
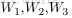
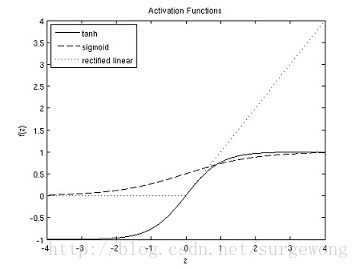
sigmoid函式是最常用的激勵函式,除此之外還有雙曲正切函式(hyperbolic tangent),不過雙曲正切函式將值對映到(-1,1),相比sigmoid就相當於將類別分為-1和1,可以認為是sigmoid函式的一種“拉伸”。雙曲正切函式的特性有: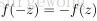
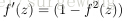
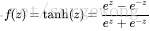
最近的研究發現還有一種新的激勵函式,修正後的線性函式(rectified linear function),在小於0的部分,激勵函式輸出0,大於0的部分,輸出為 原來的值。與sigmoid函式和雙曲正切函式相比,該函式沒有限定其值域,並且該函式在0點出,不可導。
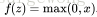
下面給出的是sigmoid,tanh,修改後的線性函式的圖:
二、神經網路模型(Neural Network model)
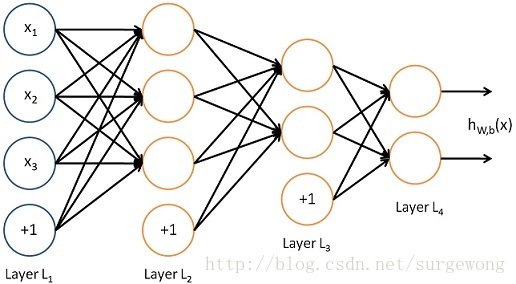
下面考慮一個簡單地三層的網路結構,相比單個神經元網路結構而言只是增加了一箇中間隱層(hidden layer)。隱層(hidden)是相對於輸入(Input layer)和輸出層(Output layer)而言的,輸入層是指輸入的資料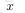
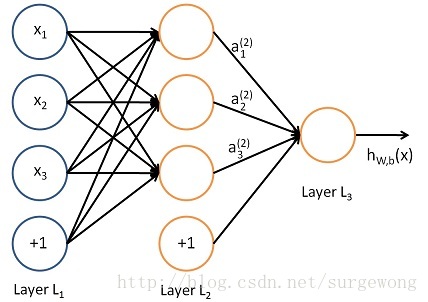
上圖的網路結構中+1表示一個偏置(bias),也就是上面講的截距(intercept),這個雖然是網路中的一個節點,但是在說網路結構的時候,通常不將其計算在內。上圖中的網路結構可以描述成,三個輸入節點,三個隱藏節點,一個輸出節點。
為了描述這個網路結構,令網路層數為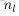
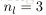
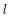
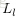
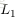
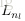
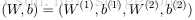
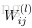
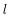
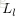
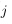
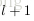
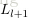
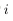
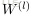
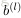
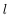
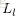
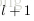
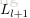
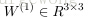
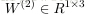
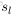
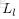
令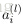
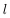
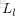
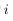
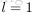
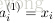
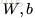
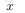
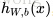
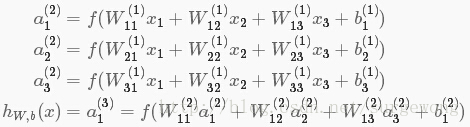
上面的公式是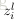
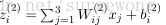
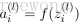
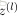
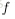
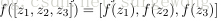
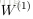
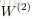
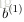
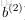
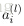
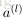
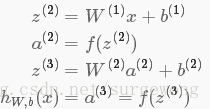
接下來就可以通過矩陣和向量的操作得到網路的輸出結果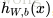
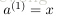
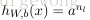
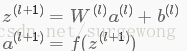
上面我們給出最後的結果是1維,輸出多維的結果其實是一樣的,都有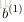
三、後向傳播演算法(Back Propagation Algorithm)
上面介紹了前向傳播(forward propagation)的過程,也就是給定網路引數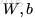
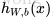
網路引數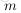
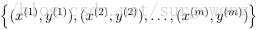
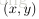
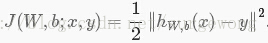
對於
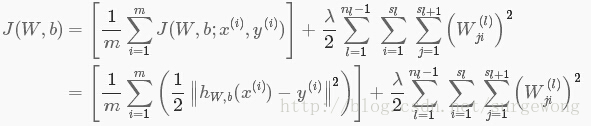
這裡引入了一個正則項,主要是為了防止過擬合,從上面的公式可以看出,正則項中沒有偏置項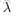
在訓練過程,主要目的就是最小化自變數為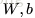
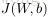
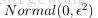
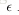
使用梯度下降法更新
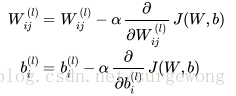
公式中的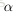
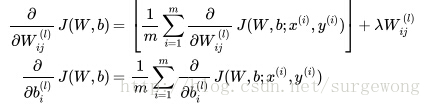
進一步問題簡化了:在單個樣本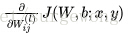
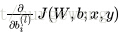
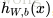
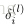
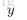
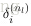
1. 使用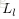
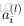
2. 對於輸出層(層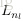
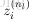
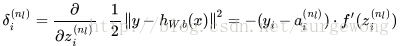
3. 對於隱層,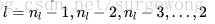
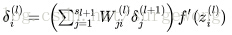
4. 計算得到每層的每個節點的
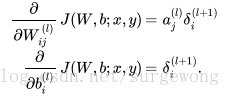
怎麼理解上述中的兩個公式呢?還記得
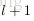
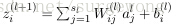
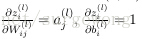
上面得到的結果是單個分量的形式,下面將其表達成矩陣和向量形式。將激勵函式的導數應用於向量的每個元素,類似的有: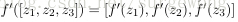

1. 使用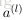
2. 對於輸出層(層
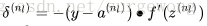
3. 對於隱層,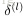
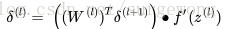
4. 計算得到每層的 誤差向量,就可以計算每層引數
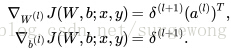
四、演算法實現
首先定義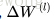
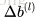
1. 初始化網路,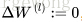

2. 對於
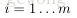
使用後向傳播演算法計算
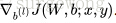
更新
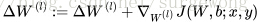
更新
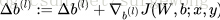
4. 最後跟新
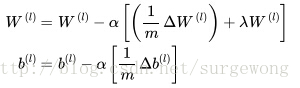
本文基本上算是對【1】的翻譯和註釋,現在基本上算是整理清楚了網路的結構,可以進行下一步的學習了。下面附上UFLDL教程下,matlab的實現程式碼。由於是MNIST手寫數字是一個多分類問題,最後一層使用的損失函式和Softmax的類似,與上文中的二次損失函式不同,在程式碼supervised_dnn_cost.m的實現部分需要注意。另外程式碼可以參考【5】。
function [ cost, grad, pred_prob] = supervised_dnn_cost( theta, ei, data, labels, pred_only)
%SPNETCOSTSLAVE Slave cost function for simple phone net
% Does all the work of cost / gradient computation
% Returns cost broken into cross-entropy, weight norm, and prox reg
% components (ceCost, wCost, pCost)
%% default values
po = false;
if exist('pred_only','var')
po = pred_only;
end;
%% reshape into network
stack = params2stack(theta, ei);
numHidden = numel(ei.layer_sizes) - 1;
hAct = cell(numHidden+1, 1);
gradStack = cell(numHidden+1, 1);
% stack 記錄著網路的引數W1,b1;W2,b2(這是隱層數為1的結果,多層的情況類似)
% numHidden 隱層的數目
% hAct 網路每一層的輸入與輸出結果(輸入層除外)(為了更清楚地瞭解神經網路的執行過程,下面的計算過程,每層的中間結果都儲存在這個節點中)
% gradStack 訓練網路的梯度
%% forward prop
for l = 1:numHidden+1
if(l == 1)
hAct{l}.z = stack{l}.W*data; % 第一個隱層,將訓練資料集作為其資料
else
hAct{l}.z = stack{l}.W*hAct{l-1}.a; % 第l層的輸入,是第l-1層的輸出,
end
hAct{l}.z = bsxfun(@plus,hAct{l}.z,stack{l}.b); % 第l層的節點的輸入加上偏置
hAct{l}.a = sigmoid(hAct{l}.z); % 應用啟用函式
end
% 預測概率為softmax方式,可能由於框架的原因,使用二次損失函式計算出來的效果不是很好
total_e = exp(hAct{numHidden+1}.z);
pred_prob = bsxfun(@rdivide,total_e,sum(total_e,1));
hAct{numHidden+1}.a = pred_prob;
%% return here if only predictions desired.
if po
cost = -1; ceCost = -1; wCost = -1; numCorrect = -1;
grad = [];
return;
end;
%% compute cost
% 使用softmax方法,計算J(W,b),最後一個層的輸出結果就是hw,b(x) = hAct{numHidden+1}.a
label_index = sub2ind(size(hAct{numHidden+1}.a),labels',1:size(hAct{numHidden+1}.a,2));
ceCost = -sum(log(hAct{numHidden+1}.a(label_index))); % softmax 的方式計算損失函式,不帶正則項
%% compute gradients using backpropagation
% 計算每層輸出的誤差(對輸入z的偏導)
% sigmoid的導函式 f'(z) = f(z)(1-(f(z)))
% a = f(z)
tabels = zeros(size(hAct{numHidden+1}.a));
tabels(label_index) = 1;
for l = numHidden+1:-1:1
if(l == numHidden+1)
hAct{l}.delta = -(tabels - hAct{l}.a); % 輸出層使用softmax的損失函式,所以和二次項損失函式不同,其他的都是一樣的
else
hAct{l}.delta = (stack{l+1}.W'* hAct{l+1}.delta) .* (hAct{l}.a .*(1- hAct{l}.a));
end
if(l == 1)
gradStack{l}.W = hAct{l}.delta*data';
gradStack{l}.b = sum(hAct{l}.delta,2);
else
gradStack{l}.W = hAct{l}.delta*hAct{l-1}.a';
gradStack{l}.b = sum(hAct{l}.delta,2);
end
end
%% compute weight penalty cost and gradient for non-bias terms
wCost = 0;
for l = 1:numHidden
wCost = wCost+ sum(sum(stack{l}.W.^2)); % 網路引數W 的累計和,正則項損失
end
cost = ceCost + .5 * ei.lambda * wCost; % 帶正則項的損失
% Computing the gradient of the weight decay.
for l = numHidden+1: -1 : 1
gradStack{l}.W = gradStack{l}.W + ei.lambda * stack{l}.W;
end
%% reshape gradients into vector
[grad] = stack2params(gradStack);
end
【1】UFLDL:Multi-Layer Neural Network
【2】CSDN:反向傳播BP演算法
【3】UFLDL:Logistic Regression
【4】Wikipedia:activation function
【5】CSDN:ufldl學習筆記與程式設計作業:Multi-Layer Neural Network