
神經網路的損失函式
損失函式可以分成兩大類:分類和迴歸。這裡我們對這兩類進行了細分和講解。
迴歸損失:
- L1loss(L1損失)
L1損失,也稱平均絕對誤差(MAE),簡單說就是計算輸出值與真實值之間誤差的絕對值大小。這種度量方法在不考慮方向的情況下衡量誤差大小。和MSE的不同之處在於,MAE需要線性規劃這樣複雜的工具來計算梯度,同時,MAE對異常值更加穩健,因為它不使用平分。 由於L1 loss在零點不平滑,所以用的比較少。 - SmoothL1Loss
L1loss的平滑版。如果絕對元素誤差低於1則使用平方項的標準,否則L1項。 它對異常值的敏感度低於MSELoss,並且在某些情況下可以防止爆炸梯度。
- MSELoss(L2損失)
L2損失,也稱均方誤差,度量的是預測值和實際觀測值間差的平分的均值。它只考慮誤差的平均大小,不考慮其方向。但由於經過平分,與真實值偏離較多的預測值會受到更為嚴重的懲罰。同時MSE的數學特性很好,這使得計算梯度變得更容易。 - MBELoss
平均偏差誤差,它和L1損失很相似,唯一區別就是這個函式沒有絕對值,它可以用來確定模型存在正偏差還是負偏差。

注意:L1、L2損失函式與L1、L2正則化是兩個不同的東西。
L1損失函式與L2損失函式的對比分析:
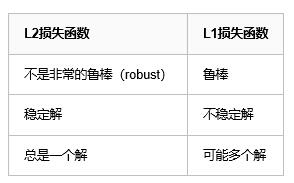
魯棒性(robustness):
因為與最小平方相比,最小絕對值偏差方法的魯棒性更好,因此,它在許多場合都有應用。最小絕對值偏差之所以是魯棒的,是因為它能處理資料中的異常值。這或許在那些異常值可能被安全地和有效地忽略的研究中很有用。如果需要考慮任一或全部的異常值,那麼最小絕對值偏差是更好的選擇。
從直觀上說,因為L2範數將誤差平方化(如果誤差大於1,則誤差會放大很多),模型的誤差會比L1範數來得大( e vs e^2 ),因此模型會對這個樣本更加敏感,這就需要調整模型來最小化誤差。如果這個樣本是一個異常值,模型就需要調整以適應單個的異常值,這會犧牲許多其它正常的樣本,因為這些正常樣本的誤差比這單個的異常值的誤差小。
穩定性:
最小絕對值偏差方法的不穩定性意味著,對於資料集的一個小的水平方向的波動,迴歸線也許會跳躍很大。在一些資料結構(data configurations)上,該方法有許多連續解;但是,對資料集的一個微小移動,就會跳過某個資料結構在一定區域內的許多連續解。在跳過這個區域內的解後,最小絕對值偏差線可能會比之前的線有更大的傾斜。相反地,最小平方法的解是穩定的,因為對於一個數據點的任何微小波動,迴歸線總是隻會發生輕微移動;也就說,迴歸引數是資料集的連續函式。
分類損失
- CrossEntropyLoss
交叉熵損失,常在分類問題中使用,隨著預測概率偏離實際標籤,交叉熵會逐漸增加。
它將nn.LogSoftmax()和nn.NLLLoss()組合在一個單獨的類中。所以使用它並不需要在網路中加入softmax。在多分類任務中,它非常有用。它具有可選引數權重,為1D Tensor,為每個類分配權重。 當您擁有不平衡的訓練集時,這尤其有用。 - NLLLoss
負對數似然損失函式。在前面加上LogSoftMax就等價於CrossEntropyLoss。 在多分類任務中很有用。如果提供,則可選引數權重應為1D Tensor,為每個類分配權重。 當您擁有不平衡的訓練集時,這尤其有用。
後面這些還不是很清楚什麼時候使用,以後再補充。
6、PoissonNLLLoss
target是泊松脈衝分佈的負對數似然損失函式。
7、KLDivLoss
KL散度,KL散度是連續分佈的有用距離度量,並且在對(離散取樣的)連續輸出分佈的空間執行直接回歸時通常是有用的。
8、BCELoss
二分類用的交叉熵,用的時候需要在該層前面加上 Sigmoid 函式。
9、BCEWithLogitsLoss
BCELoss的改進。這種損失將Sigmoid層和BCELoss組合在一個單獨的類中。 這個版本在數值上比使用普通的Sigmoid後跟BCELoss更穩定,因為通過將操作組合成一個層,我們利用log-sum-exp技巧來實現數值穩定性。
10、MarginRankingLoss
評價相似度的損失。
11、HingeEmbeddingLoss
在給定輸入張量x和包含值(1或-1)的標籤張量y的情況下測量損失。 這通常用於測量兩個輸入是相似還是不相似,例如, 使用L1成對距離作為x,並且通常用於學習非線性嵌入或半監督學習。
12、MultiLabelMarginLoss
多類別(multi-class)多分類(multi-classification)的 Hinge 損失,是上 MultiMarginLoss 在多類別上的拓展。
13、SoftMarginLoss
多標籤二分類問題。
14、MultiLabelSoftMarginLoss
上面的多分類版本。
15、CosineEmbeddingLoss
餘弦相似度的損失,目的是讓兩個向量儘量相近
16、MultiMarginLoss
多分類(multi-class)的 Hinge 損失,
17、TripletMarginLoss