
redis跳躍表
跳躍表是一種可以對有序連結串列進行近似二分查詢的資料結構,redis在兩個地方用到了跳躍表,一個是實現有序集合,另一個是在叢集節點中用作內部資料結構。首先看什麼是跳躍表,redis中的跳躍表只是為了支援自己的一些操作,而對普通的跳躍表做了一些改動,但整體思想都差不多。
網上有很多關於跳躍表的部落格,本文對自己學習過程中看到的參考資料和學習的過程做一個歸納整理。
1、普通跳躍表
為什麼要用到跳躍表:http://blog.jobbole.com/111731/
跳躍表原理、操作:https://www.cnblogs.com/George1994/p/7635731.html
普通跳躍表的一個C++實現:https://www.cnblogs.com/learnhow/p/6749648.html
2、redis裡的跳躍表
以下內容轉自部落格:https://blog.csdn.net/universe_ant/article/details/51134020,該部落格詳細記錄了《redis設計與實現》書中的內容,如下:
跳躍表(skiplist)是一種有序資料結構,它通過在每個節點中維持多個指向其他節點的指標,從而達到快速訪問節點的目的。
跳躍表支援平均O(logN)、最壞O(N)複雜度的節點查詢,還可以通過順序性操作來批量處理節點。
在大部分情況下,跳躍表的效率可以和平衡樹相媲美,並且因為跳躍表的實現比平衡樹要來得更為簡單,所以有不少程式都使用跳躍表來代替平衡樹。
Redis使用跳躍表作為有序集合鍵的底層實現之一,如果一個有序集合包含的元素數量比較多,又或者有序集合中元素的成員(member)是比較長的字串時,Redis就會使用跳躍表來作為有序集合鍵的底層實現。
和連結串列、字典等資料結構被廣泛地應用在Redis內部不同,Redis只在兩個地方用到了跳躍表,一個是實現有序集合鍵,另一個是在叢集節點中用作內部資料結構,除此之外,跳躍表在Redis裡面沒有其他用途。
跳躍表的實現
Redis的跳躍表由redis.h/zskiplistNode和redis.h/zskiplist兩個結構定義,其中zskiplistNode結構用於表示跳躍表節點,而zskiplist結構則用於儲存跳躍表節點的相關資訊,比如節點的數量,以及指向表頭節點和表尾節點的指標等等。

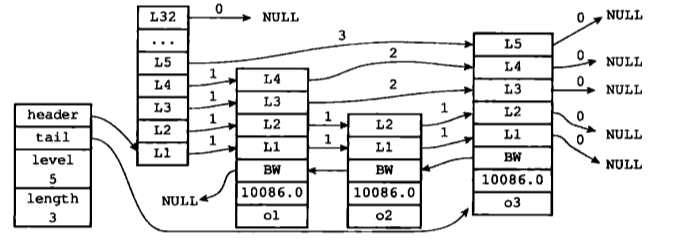
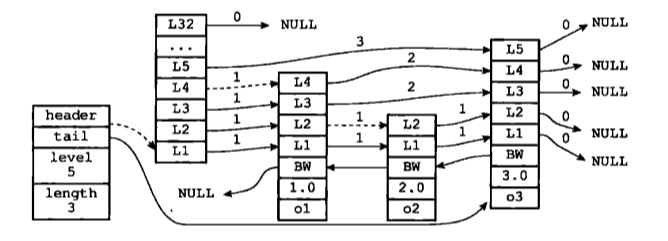
上圖展示了一個跳躍表示例,位於圖片最左邊的是zskiplist結構,該結構包含以下屬性:
- header:指向跳躍表的表頭節點
- tail:指向跳躍表的表尾節點
- level:記錄目前跳躍表內,層數最大的那個節點的層數(表頭節點的層數不計算在內)
- length:記錄跳躍表的長度,也即是,跳躍表目前包含節點的數量(表頭節點不計算在內)
位於zskiplist結構右方的是四個zskiplistNode結構,該結構包含以下屬性:
- 層(level):節點中用L1、L2、L3等字樣標記節點的各個層,L1代表第一層,L2代表第二層,依次類推。每個層都帶有兩個屬性:前進指標和跨度。前進指標用於訪問位於表尾方向的其他節點,而跨度則記錄了前進指標所指向節點和當前節點的距離。在上面的圖片中,連線上帶有數字的箭頭就代表前進指標,而那個數字就是跨度。當程式從表頭向表尾進行遍歷時,訪問會沿著層的前進指標進行。
- 後退(backward)指標:節點中用BW字樣標記節點的後退指標,它指向位於當前節點的前一個節點。後退指標在程式從表尾向表頭遍歷時使用。
- 分值(score):各個節點中的1.0、2.0和3.0是節點所儲存的分值。在跳躍表中,節點按各自所儲存的分值從小到大排列。
- 成員物件(obj):各個節點中的o1、o2和o3是節點所儲存的成員物件。
注意表頭節點和其他節點的構造是一樣的:表頭節點也有後退指標、分值和成員物件,不過表頭節點的這些屬性都不會被用到,所以圖中省略了這些部分,只顯示了表頭節點的各個層。
跳躍表節點
跳躍表節點的實現由redis.h/zskiplistNode結構定義:
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
robj *obj; /*成員物件*/
double score; /*分值*/
struct zskiplistNode *backward; /*後退指標*/
struct zskiplistLevel { /*層*/
struct zskiplistNode *forward; /*前進指標*/
unsigned int span; /*跨度*/
} level[];
} zskiplistNode;- 1、分值和成員
節點的分值(score屬性)是一個double型別的浮點數,跳躍表中的所有節點都按分值從小到大來排序。
節點的成員物件(obj屬性)是一個指標,它指向一個字串物件,而字串物件則儲存著一個SDS值。
在同一個跳躍表中,各個節點儲存的成員物件必須是唯一的,但是多個節點儲存的分值卻可以是相同的:分至相同的節點將按照成員物件在字典中的大小來進行排序,成員物件較小的節點會排在前面(靠近表頭的方向),而成員物件較大的節點則會排在後面(靠近表尾的方向)。
舉個例子,在下圖中所示的跳躍表中,三個跳躍表節點都儲存了相同的分值10086.0,但儲存成員物件o1的節點卻排在儲存成員物件o2和o3的節點的前面,而儲存成員物件o2的節點又排在儲存成員物件o3的節點之前,由此可見,o1、o2、o3三個成員物件在字典中的排序為o1<=o2<=o3。
2、後退指標
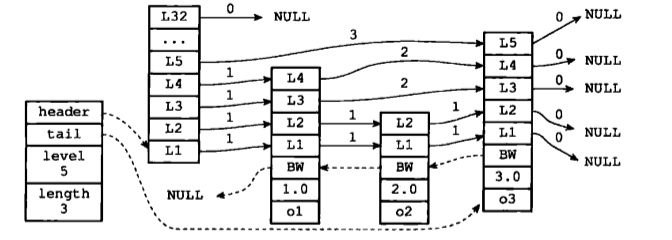
節點的後退指標(backward屬性)用於從表尾向表頭方向訪問節點:跟可以一次跳過多個節點的前進指標不同,因為每個節點只有一個後退指標,所以每次只能後退至前一個節點。
下圖用虛線展示瞭如何從表尾向表頭遍歷跳躍表中的所有節點:程式首先通過跳躍表的tail指標訪問表尾節點,然後通過後退指標訪問倒數第二個節點,之後再沿著後退指標訪問倒數第三個節點,再之後遇到指向NULL的後退指標,於是訪問結束。
3、層
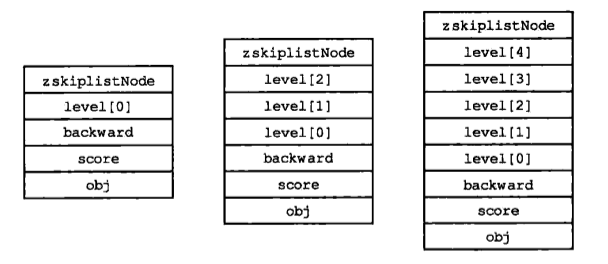
跳躍表節點的level陣列可以包含多個元素,每個元素都包含一個指向其他節點的指標,程式可以通過這些層來加快訪問其他節點的速度,一般來說,層的數量越多,訪問其他節點的速度就越快。
每次建立一個新跳躍表節點的時候,程式根據冪次定律(power law,越大的數出現的概率越小)隨機生成一個介於1和32之間的值作為level陣列的大小,這個大小就是層的“高度”。
下圖分別展示了三個高度為1層、3層和5層的節點,因為C語言的陣列索引總是從0開始的,所以節點的第一層是level[0],而第二層是level[1],依次類推。
4、前進指標
每個層都有一個指向表尾方向的前進指標(level[i].forward屬性),用於從表頭向表尾方向訪問節點。下圖用虛線表示出了程式從表頭向表尾方向,遍歷跳躍表中所有節點的路徑:
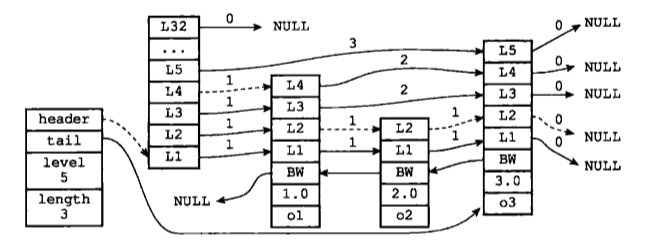
1) 迭代程式首先訪問跳躍表的第一個節點(表頭),然後從第四層的前進指標移動到表中的第二個節點。
2) 在第二個節點時,程式沿著第二層的前進指標移動到表中的第三個節點。
3) 在第三個節點時,程式同樣沿著第二層的前進指標移動到表中的第四個節點。
4) 當程式再次沿著第四個節點的前進指標移動時,它碰到一個NULL,程式知道這時已經到達了跳躍表的表尾,於是結束這次遍歷。
5、跨度
層的跨度(level[i].span屬性)用於記錄兩個節點之間的距離:
- 兩個節點之間的跨度越大,它們相距得就越遠。
- 指向NULL的所有前進指標的跨度都為0,因為它們沒有連向任何節點。
初看上去,很容易以為跨度和遍歷操作有關,但實際上並不是這樣的,遍歷操作只使用前進指標就可以完成了,跨度實際上是用來計算排位(rank)的:在查詢某個節點的過程中,將沿途訪問過的所有層的跨度累計起來,得到的結果就是目標節點在跳躍表中的排位。
舉個例子,下圖用虛線標記了在跳躍表中查詢分值為3.0、成員物件為o3的節點時,沿途經歷的層:查詢的過程只經過了一個層,並且層的跨度為3,所以目標節點在跳躍表中的排位為3。
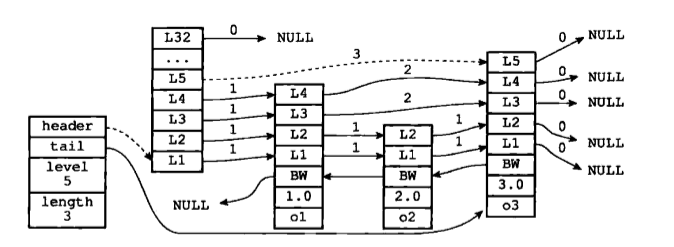
再舉個例子,下圖用虛線標記了在跳躍表中查詢分值為2.0、成員物件為o2的節點時,沿途經歷的層:在查詢節點的過程中,程式經過了兩個跨度為1的節點,因此可以計算出,目標節點在跳躍表中的排位為2。
跳躍表
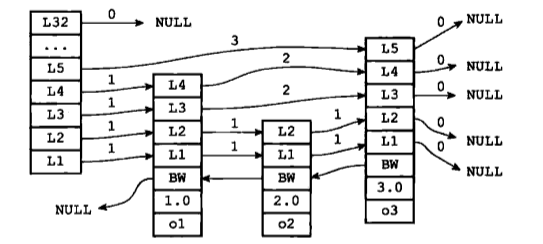
僅靠多個跳躍表節點就可以組成一個跳躍表,如下圖所示:
但通過使用一個zskiplist結構來持有這些節點,程式可以更方便地對整個跳躍表進行處理,比如快速訪問跳躍表的表頭節點和表尾節點,或者快速地獲取跳躍表節點的數量(也即是跳躍表的長度)等資訊,如下圖所示:
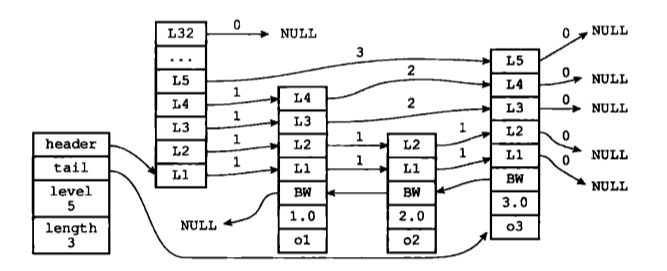
zskiplist結構的定義如下:
typedef struct zskiplist {
struct zskiplistNode *header, *tail; //header指向跳躍表的表頭節點,tail指向跳躍表的表尾節點
unsigned long length; //記錄跳躍表的長度,也即是,跳躍表目前包含節點的數量(表頭節點不計算在內)
int level; //記錄目前跳躍表內,層數最大的那個節點的層數(表頭節點的層數不計算在內)
} zskiplist;這樣獲取表頭、表尾節點,表長,以及表中最高層數的複雜度均為O(1)。
加油!原始碼之前無祕密,靜下心來好好看看原始碼!!