
Bobo老師機器學習筆記第五課-多元線性迴歸
思維導圖學習筆記
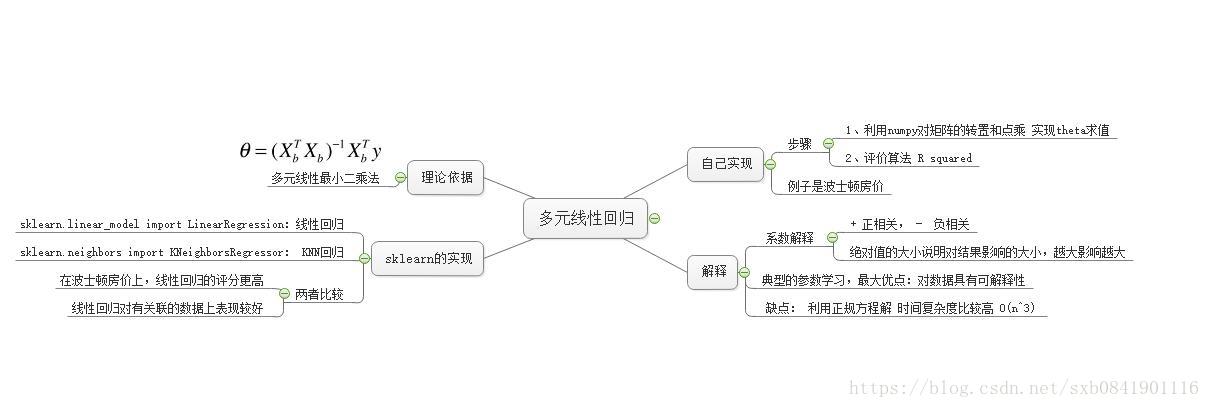
自己參考BoBo老師課程講解實現:
# -*- coding: utf-8 -*- import numpy as np from metrics import r2_score class LinearRegression(object): def __int__(self): self.coef_ = None # 表示係數 self.intercept_ = None # 表示截距 self._theta = None # 過程計算值,不需要暴露給外面 def fit(self, X_train, y_train): """根據訓練資料集X_train, y_train訓練Linear Regression模型""" assert X_train is not None and y_train is not None, "訓練集X和Y不能為空" assert X_train.shape[0] == y_train.shape[0], "訓練集X和Y的樣本數要相等" # np.linalg.inv(X) 表示求X的逆矩陣 # 不能忘了X要增加一列,第一列資料為0 ones = np.ones(shape=(len(X_train), 1)) X_train = np.hstack((ones, X_train)) self._theta = np.linalg.inv(X_train.T.dot(X_train)).dot(X_train.T).dot(y_train) self.intercept_ = self._theta[0] self.coef_ = self._theta[1:] def _predict(self, X): return X.dot(self.coef_.T) + self.intercept_ def predict1(self, X_test): """給定待預測資料集X_test,返回表示X_test的結果向量""" assert X_test.shape[1] == self.coef_.shape[0], '測試集X的特徵值個數不對' return np.array([self._predict(X) for X in X_test]) def predict(self, X_test): """給定待預測資料集X_test,返回表示X_test的結果向量""" assert X_test.shape[1] == self.coef_.shape[0], '測試集X的特徵值個數不對' ones = np.ones(shape=(len(X_test), 1)) X_test = np.hstack((ones, X_test)) return X_test.dot(self._theta) def scores(self, X_test, y_test): """根據測試資料集 X_test 和 y_test 確定當前模型的準確度""" assert X_test.shape[0] == y_test.shape[0], '測試集X和Y的個數不相等' return r2_score(y_test, self.predict1(X_test))
測試指令碼:
# -*- encoding: utf-8 -*- from sklearn.datasets import load_boston from model_selection import train_test_split from linearregression import LinearRegression boston = load_boston() X = boston.data y = boston.target X = X[y < 50] y = y[y < 50] X_train, X_test, y_train, y_test = train_test_split(X, y, seed=666) lrg = LinearRegression() lrg.fit(X_train, y_train) # 為什麼求出來的theta.shape== (13L,) print lrg.coef_ print lrg.intercept_ print (lrg.scores(X_test, y_test))
執行結果:
[-1.18919477e-01 3.63991462e-02 -3.56494193e-02 5.66737830e-02
-1.16195486e+01 3.42022185e+00 -2.31470282e-02 -1.19509560e+00
2.59339091e-01 -1.40112724e-02 -8.36521175e-01 7.92283639e-03
-3.81966137e-01]
34.16143549624022
0.8129802602658537
實現總結:
1、上面的準確率是81.29%
2、在實現過程中,fit方法裡面,忘了在X_train訓練集中新增1的列向量,導致計算出來的係數矩陣引數不對
3、在pridect中,有兩種實現方法,可以直接利用中間計算出來的theta值,也可以用X_test.dot(係數矩陣) + 截距舉證
4、 np.hstack這個方法,引數值一個tuple,同時要注意相互之間的順序,越是前面的矩陣則在合併後矩陣越靠前
5、在numpy中實現一個矩陣的逆矩陣用到的方法是np.linalg.inv方法
sklearn中的迴歸實現
# -*- encoding: utf-8 -*-
from sklearn.datasets import load_boston
from sklearn.neighbors import KNeighborsRegressor
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split, GridSearchCV
def test_regression():
boston = load_boston()
X = boston.data
y = boston.target
X = X[y < 50]
y = y[y < 50]
X_train, X_test, y_train, y_test = train_test_split(X, y)
# sklearn中的利用LinearRegression
lrg = LinearRegression()
lrg.fit(X_train, y_train)
print ('LinearRegression:', lrg.score(X_test, y_test))
# 利用KNN迴歸
knnrg = KNeighborsRegressor()
# 利用網格搜尋找到最好的KNN引數
param_grid = [
{
'weights': ['uniform'],
'n_neighbors': [i for i in range(1, 11)]
},
{
'weights': ['distance'],
'n_neighbors': [i for i in range(1, 11)],
'p': [i for i in range(1, 6)]
}
]
grid_search = GridSearchCV(knnrg, param_grid, n_jobs=-1, verbose=1)
grid_search.fit(X_train, y_train)
print 'GridSearchCV:', grid_search.best_estimator_.score(X_test, y_test)
print 'GridSearchCV Best Params:', grid_search.best_params_
if __name__ == '__main__':
test_regression()
執行結果:
LinearRegression: 0.7068690903842936
Fitting 3 folds for each of 60 candidates, totalling 180 fits
[Parallel(n_jobs=-1)]: Done 180 out of 180 | elapsed: 1.3s finished
GridSearchCV: 0.6994655719704079
GridSearchCV Best Params: {'n_neighbors': 10, 'weights': 'distance', 'p': 1}
sklearn中可以看到出來,線性迴歸還是要比KNN迴歸要好。此外也要注意,在使用網格搜尋的時候,不能有grid_search.score()方法,而是用grid_search.best_estimator_.score方法,因為兩個實現不一樣。
要是你在西安,感興趣一起學習AIOPS,歡迎加入QQ群 860794445