
Bobo老師機器學習筆記第八課-什麼是交叉驗證?
1、測試資料的真正意義是什麼?
在上篇部落格中,我們看到測試集和訓練集在同一個模型上會表現不同的結果。我們通過學習曲線可以直觀的看到具體是過擬合還是欠擬合,從而調整引數,進行不斷驗證,直到找到一個在訓練集表現好的資料。 總結一句話,就是通過測試資料進行對模型的調優。
2、 依靠測試資料來調優模型,會不會存在模型對測試資料形成過擬合?
會存在,因為我們是圍繞測試資料集來驗證模型的。所以要介紹一種新的驗證方法,就是交叉驗證(cross validation)。
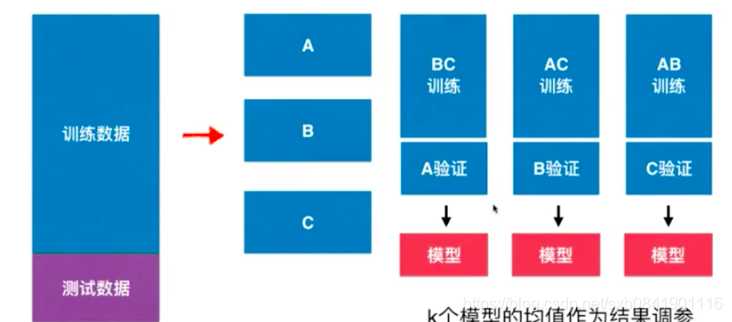
通過上圖可以檢視,交叉驗證是原來資料分為訓練資料和測試資料,然後把訓練資料分為K份(k=3,5,10)然後用其中1份作為驗證、其餘K-1份作為訓練,從而得到K個模型,然後針對K的模型均值作為調參,記下來我們看看用Sklearn中的程式碼如何實現。
# -*- coding: utf-8 -*- import numpy as np from sklearn.datasets import load_digits from sklearn.model_selection import train_test_split from sklearn.model_selection import cross_val_score from sklearn.neighbors import KNeighborsClassifier X, y = load_digits(return_X_y=True) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=666) def test_using_split(): """ 這裡直接使用網格的方式去搜索 :return: """ best_k, best_p, best_score = 0, 0, 0 for k in range(2, 11): for p in range(1, 6): knn_clf = KNeighborsClassifier(n_neighbors=k, p=p, weights='distance') knn_clf.fit(X_train, y_train) scores = knn_clf.score(X_test, y_test) if scores > best_score: best_score = scores best_k = k best_p = p print 'best_k:', best_k print 'best_p:', best_p print 'best_score:', best_score # best_k: 3 # best_p: 4 # best_score: 0.9860917941585535 def test_using_cross_validation(): """ 用交叉驗證的方法獲取最佳引數 :return: """ best_k, best_p, best_score = 0, 0, 0 for k in range(2, 11): for p in range(1, 6): knn_clf = KNeighborsClassifier(weights="distance", n_neighbors=k, p=p) scores = cross_val_score(knn_clf, X_train, y_train) score = np.mean(scores) if score > best_score: best_k, best_p, best_score = k, p, score print 'best_k:', best_k print 'best_p:', best_p print 'best_score:', best_score # best_k: 2 # best_p: 2 # best_score: 0.9823599874006478
通過兩種方法搜尋,會發現找到最佳引數是不一樣的, 用了交叉驗證方法找到KNN分類方法的最佳引數都是2,並且最高評分是0.98。 但此刻要注意,利用交叉驗證的方法,0.98不能代表模型在測試集上的分數,而真正意義是在3個交叉驗證的模型評分的平均值。
要獲取最好模型在測試集上的資料應該按照下面方式:
best_knn_clf = KNeighborsClassifier(weights="distance", n_neighbors=2, p=2) best_knn_clf.fit(X_train, y_train) print best_knn_clf.score(X_test, y_test)
把獲取到的最佳引數初始化分類器,然後用分類器再驗證測試集。
這個結果是:0.980528511821975
通過對比就會發現,這個分數其實比沒有用交叉驗證獲取的分數(0.9860917941585535)要低。 但是這裡要注意,利用交叉驗證的資料在其他測試集上有更好的效果。
最後我們稍微總結一下:
1、交叉驗證用來尋找最好的超引數,它有時在測試資料集上表現沒有其他好,但它的泛化能力強
2、cross_val_score這個方法預設的cv=3,表示把訓練集分為3份,但是可以通過設定為更高。設定越高,則找到的模型泛化能力更強,但是同樣計算複雜度會越高。