
tensorflow常用函式之tf.nn.softmax
關於softmax的詳細說明,請看Softmax。
通過Softmax迴歸,將logistic的預測二分類的概率的問題推廣到了n分類的概率的問題。通過公式
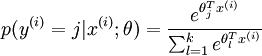
可以看出當月分類的個數變為2時,Softmax迴歸又退化為logistic迴歸問題。
下面的幾行程式碼說明一下用法
import tensorflow as tf A = [1.0,2.0,3.0,4.0,5.0,6.0] with tf.Session() as sess: print sess.run(tf.nn.softmax(A))
結果
[ 0.00426978 0.01160646 0.03154963 0.08576079 0.23312201 0.63369131]
轉自TensorF學習網 :https://my.oschina.net/u/780234/blog/1588827
相關推薦
tensorflow常用函式之tf.nn.softmax
關於softmax的詳細說明,請看Softmax。 通過Softmax迴歸,將logistic的預測二分類的概率的問題推廣到了n分類的概率的問題。通過公式 可以看出當月分類的個數變為2時,Softmax迴歸又退化為logistic迴歸問題。
TensorFlow函式之tf.nn.relu()
tf.nn.relu()函式是將大於0的數保持不變,小於0的數置為0,函式如圖1所示。 ReLU函式是常用的神經網路啟用函式之一。 圖1 ReLU函式影象 下邊為ReLU例子: import tenso
TensorFlow函式之tf.nn.conv2d()(附程式碼詳解)
tf.nn.conv2d是TensorFlow裡面實現卷積的函式,是搭建卷積神經網路比較核心的一個方法。 函式格式: tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu = Noen, name = Non
Tensorflow學習筆記之tf.nn.relu
Tensorflow學習筆記之tf.nn.relu 關於Tensorflow的學習筆記大部分為其他部落格或者書籍轉載,只為督促自己學習。 線性整流函式(Rectified Linear Unit,ReLU),又稱修正線性單元。其定義如下圖,在橫座標的右側,ReLU函式為線性函式。在橫座標
tf.nn.conv2d函式、padding型別SAME和VALID、tf.nn.max_pool函式、tf.nn.dropout函式、tf.nn.softmax函式、tf.reduce_sum函式
tf.nn.conv2d函式: 該函式是TensorFlow裡面實現卷積的函式。 函式形式: tf.nn.conv2d (input, filter, strides, padding, use_cudnn_on_gpu=None, data_format=None,
tensorflow-啟用函式及tf.nn.dropout
參考《Tensorflow技術解析與實戰》 啟用函式 啟用函式(activation function)將神經元計算wTx+b的結果經過非線性表達對映到下一層。 需要可微,啟用函式不會改變輸入
tensorflow之常用函式(tf.Constant)
轉載:http://blog.sina.com.cn/s/blog_e504f4340102yd4k.html tensorflow中我們會看到這樣一段程式碼: import tensorflow as tf a = tf.constant([1.0, 2
TensorFlow之tf.nn.dropout():防止模型訓練過程中的過擬合問題
AC -- 輸出 array 全連接 spa () 激活 odin 一:適用範圍: tf.nn.dropout是TensorFlow裏面為了防止或減輕過擬合而使用的函數,它一般用在全連接層 二:原理: dropout就是在不同的訓練過程中隨機扔掉一部分神經元。也就是
tensorflow之tf.nn.l2_normalize與l2_loss的計算
1.tf.nn.l2_normalize tf.nn.l2_normalize(x, dim, epsilon=1e-12, name=None) 上式: x為輸入的向量; dim為l2範化的維數,dim取值為0或0或1; eps
TensorFlow函式之tf.constant()
tf.constant()可以實現生成一個常量數值。 tf.constant()格式為: tf.constant(value,dtype,shape,name) 引數說明: value:常量值 dtype:資料型別 shape:表示生成常量數的維度 nam
TensorFlow函式之tf.random_normal()
tf.trandom_normal()函式是生成正太分佈隨機值 此函式有別於tf.truncated_normal()正太函式,請參考本部落格關於tf.truncated_normal()函式的介紹 (TensorFlow函式之tf.truncated_normal()) tf.ra
TensorFlow函式之tf.truncated_normal()
tf.truncated_normal()函式是一種“截斷”方式生成正太分佈隨機值,“截斷”意思指生成的隨機數值與均值的差不能大於兩倍中誤差,否則會重新生成。 此函式有別於tf.random_normal()正太函式,請參考本部落格關於tf.random_normal()函式的介紹 (Ten
TensorFlow函式之tf.clip_by_value()
tf.clip_by_value()函式可以將一個張量中的數值限制在一個範圍之內。 下邊通過簡單的例子說明次函式的用法: import tensorflow as tf v = tf.constant([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]]) print(tf.
tensorflow-tf.nn.softmax,tf.nn.sparse_softmax_cr
#!/usr/bin/env python2 # -*- coding: utf-8 -*- """ Created on Tue Oct 2 08:43:02 2018 @author: myhaspl @email:[email protected] tf.nn.softmax tf.nn.
TensorFlow函式之 tf.contrib.layers.flatten()
tf.contrib.layers.flatten(A)函式使得P保留第一個維度,把第一個維度包含的每一子張量展開成一個行向量,返回張量是一個二維的,返回的shape為[第一維度,子張量乘積)。 一般用於卷積神經網路全連線層前的預處理,因為全連線層需要將輸入資料變為一個向量,向量大小為[batc
TensorFlow函式之tf.train.exponential_decay()
tf.train.exponential_decay實現指數衰減率。通過這個函式,可以先使用較大的學習率來快速得到一個比較優的解,然後隨著迭代的繼續逐步減小學習率,使得模型在訓練後期更加穩定。 tf.train.exponential_decay格式: tf.train.
TensorFlow函式之tf.train.ExponentialMovingAverage()
tf.train.ExponentialMovingAverage來實現滑動平均模型。 格式: tf.train.ExponentialMovingAverage(decay,num_step) 引數說明: 第一個引數:decay,衰減率,一般設定接近1的數。 第二
深度學習常用啟用函式之— Sigmoid & ReLU & Softmax
1. 啟用函式 Rectified Linear Unit(ReLU) - 用於隱層神經元輸出Sigmoid - 用於隱層神經元輸出Softmax - 用於多分類神經網路輸出Linear - 用於迴
Tensorflow學習筆記之tf.layers.conv2d
Tensorflow學習筆記 關於Tensorflow的學習筆記大部分為其他部落格或者書籍轉載,只為督促自己學習。 conv2d(inputs, filters, kernel_size, strides=(1, 1), padding='valid', d
tf.argmax() tf.equal() tf.nn.softmax() eval tf.random_normal tf.reduce_mean tf.reduce_sum
先講幾個 函式 然後用程式碼測試一下 tf.reduce_sum input_tensor沿著給定的尺寸縮小axis。除非keepdims是真的,否則每個條目的張量等級減少1 axis。如果keepdims為真,則縮小尺寸將保留長度為1。 如果axis為None,則減小所有尺寸,並返