
Query-Oriented Multi-Document Summarization via Unsupervised Deep Learning
Liu Y, Zhong S H, Li W. Query-oriented multi-document summarization via unsupervised deep learning[C]//
Twenty-Sixth AAAI Conference on Artificial Intelligence. AAAI Press, 2012:1699-1705.
##Abstract
- Achieve the largest coverage of the documents content.
目的是達到最大的文件內容覆蓋 - Concentrate distributed information to hidden units layer by layer.
通過一層一層的隱藏單元,聚集分散的資訊 - The whole deep architecture is fine tuned by minimizing the information loss of reconstruction validation.
最小化重構確認時的資訊丟失
##Relatework - It is very difficult to bridge the gap between
the semantic meanings of the documents and the
basic textual units
建立語義資訊和基本文字單元連線的橋樑很困難 - propose a novel framework by referencing the architecture of the human neocortex and the procedure of
intelligent perceptionvia deep learning
參照人類大腦皮層的結構和智慧感知過程
###已有模型
support vector machine (SVM)
支援向量機-CSDN
支援向量機-部落格園
deep belief network (DBN),
深度信念網路
這是第一篇把深度網路應用到面向查詢的MDS
###文章內容
query-oriented concepts extraction, reconstruction validation for global adjustment,
and summary generation via dynamic programming
##Model
###Deep Learning for Query-oriented Multidocuments Summarization
- Dozens of cortical layers are involved in generating even the simplest lexical-semantic processing.
對每一個簡單的詞彙語義加工都要經過數十皮質層 - Deep learning has two attractive characters
- 多重隱層的非線性結構使深度模型能把複雜的問題表示得很簡明,這個特性很好的適應摘要的特性,在可允許的長度
儘量包含更多的資訊。 - 由於大多數深部模型中的成對隱層重構學習,即使在無監督的情況下,分散式資訊也可以逐層逐層地集中。
這個特性會在大的資料集中受益更多
- 深度學習可適用大多數領域
eg. image classification,image generation,audio event classification
Deep Architecture
- The feature vector fd=[fd1,fd2,…,fdv,…,fdV]
dm,tf value of word in teh vocabulary - For the hidden layer, Restricted Boltzmann Machines (RBMs) are used as building blocks
out put S=[s1,s2,s3,…,sT]
受限玻爾茲曼機學習筆記-很完整
RBM是一種雙層遞迴神經網路,其中隨機二進位制輸入和輸出使用對稱加權連線來連線。 RBM被用作深層模型的構建塊,因為自下而上的連線可以用來從低層特徵推斷更緊湊的高層表示,並且自上而下的連線可以用來驗證所生成的緊湊表示的有效性。 除了輸入層以外,深層架構的引數空間是隨機初始化的。 第一個RBM的初始引數也由查詢詞決定 - In the concept extraction stage, three hidden layers H1 , H2 , and H3 are used to abstract the documents using greedy layer-wise extraction algorithm.使用貪心分層提取演算法
- Implement:
- H1 used to filter out the words appearing accidentally
H2 is supposed to discover the key words
H3 is used to candidate sentence extraction - Reconstruction validation part intends to reconstruct the data distribution by fine-tuning the whole deep architecture
globally
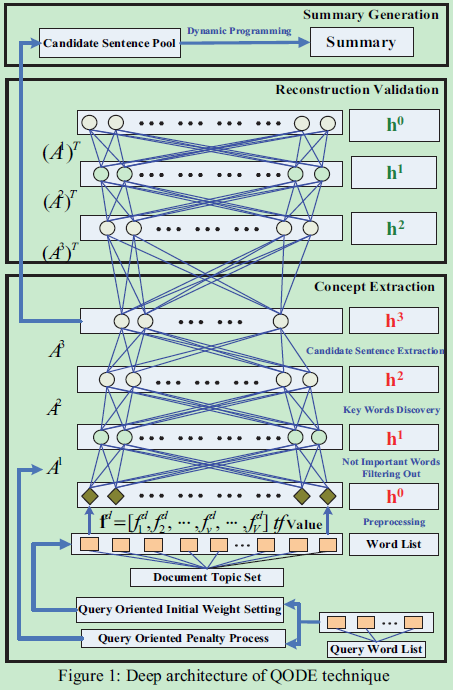
Query-oriented Concept Extraction
-
為了整合文件摘要的查詢資訊,我們有兩個不同的過程,包括:查詢面向初始權重設定和查詢導向懲罰
處理。經典的神經網路,初始化都是從u(0,0.01)高斯分佈中隨機得到的。 -
與此不同的是,我們強化了查詢的影響力。在隨機初始化設定後,如果第i個H0中的節點單詞vi屬於查詢。
-
在懲罰過程中,查詢詞的重構錯誤比其他懲罰更多
-AF importance matrix
-
DP is utilized to maximize the query oriented importance of generated summary with the constraint of summary length.
###Reconstruction Validation for Global Adjustment
-Using greedy layer-by-layer algorithm to learn a deep model for concept extraction. 該演算法有良好的全域性搜尋能力
-Using backpropagation through the whole deep model to finetune the parameters [A,b,c] for optimal reconstruction在這個過程中使用反向傳播來調整引數,該演算法有良好的區域性最優解的搜尋能力
###Summary Generation via Dynamic Programming -
DP is utilized to maximize the importance of the summary with the length constraint
狀態轉移方程:
##Conclusion
提出了一種新的面向查詢的多文件摘要深度學習模型。該框架繼承了深層學習中優秀的抽取能力,有效地推匯出了重要概念。根據實證驗證在三個標準資料集,結果不僅表明區分QODE提取能力,也清楚地表明我們提供的類似人類的自然語言處理的多文件摘要的意圖。



