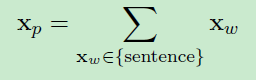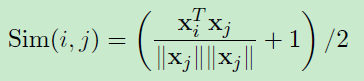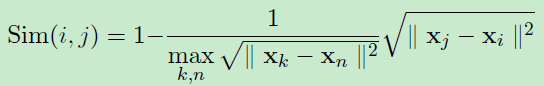Extractive Summarization using Continuous Vector Space Models
阿新 • • 發佈:2018-11-07
Kågebäck M, Mogren O, Tahmasebi N, et al. Extractive Summarization using Continuous Vector Space Models[C]// Cvsc at Eacl. 2014.
##Abstract
- Using continuous vector representations for semantically aware representations of sentences as a basis for measuring similarity.
連續向量表示法在句子語義感知表徵中的應用
實驗證明該框架的表現很好
##Introduction - word embedding
知乎對word embedding的總結
CSDN對詞嵌入的簡述 - Submodular Optimization
模型優化
收益遞減性質,來源於直覺,即把一個句子加到一小句子(即摘要)中比把一個句子加到一個更大的一個集合上做出的貢獻更大。 - This objective function can be formulated
as follows:
where S is the summary, L(S) is the coverage of the input text, R(S) is a diversity reward function. The lamada is a trade-off coefficient that allows us to define the importance of coverage versus diversity of the summary.——NP-hard - if the objective function is submodular there is a fast scalable algorithm that returns an approximation with a guarantee.
- The weights Sim(i, j) used in the L function
where tfw,i and tfw,j are the number of occurrences of w in sentence i and j, and idfw is the inverse document frequency (idf ) of w.
句子的相似性是通過tf-idf 高度重疊的詞來計算的,但下面這種情況會被認為沒有相似性:
“The US President” and “Barack Obama”
本文提出we will investigate the use of continuous vector representationsfor measuring similarity between sentences
##Background on Deep Learning - Feed Forward Neural Network(FFNN)
FFNN四輸入神經元,一個隱藏層,和1個輸出神經元。這種架構是適合一些資料X∈R4(四維空間)的分類,但根據輸入的數量和複雜性,隱藏層的尺寸應相應縮小。
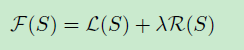
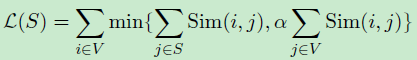
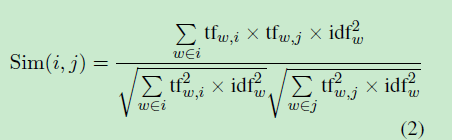
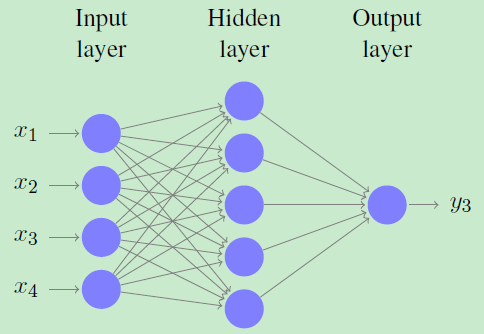
神經元是分層結構的,只允許連線到後續層。該演算法與用非線性項進行logistic迴歸相似。
- 線性迴歸,邏輯迴歸等
迴歸問題介紹(詳細)
線性迴歸淺談 - An auto-encoder (AE), is a type of FFNN with a topology
designed for dimensionality reduction(是一種拓撲設計的降維FFNN)
圖中顯示了一個自動編碼器,它將四維資料壓縮成二維程式碼。這是通過使用一個稱為編碼層的瓶頸層來實現的。
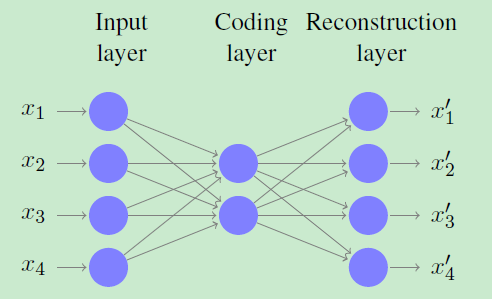
The input and the output layers in an AE are identical(輸入層和輸出層是一樣的)
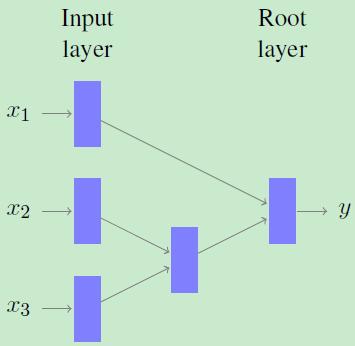
- Recursive Neural Network遞迴神經網路
RNN is a type of feed forward neural network that can process data through an arbitrary binary tree structure
遞迴神經網路結構使可變長度輸入資料成為可能。通過對所有層使用相同的維數,任意二叉樹結構可以遞迴處理。
輸入資料被放置在樹的葉節點中,並使用此樹的結構將遞迴引導到根節點。在樹上的每個非終結節點遞迴計算壓縮表示,在每個節點上使用相同的權重矩陣。更確切地說,可以使用以下公式:
##Word Embeddings
Continuous distributed vector representation of
words, also referred to as word embeddings
一個詞的嵌入是一個連續的向量表示,它捕獲單詞的語義和句法資訊。可用來揭示單詞之間的相似性
計算word embedding方法:
- Collobert &Weston CW vector
- Continuous Skip-gram 提出的方法: Word2Vec
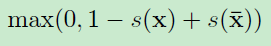
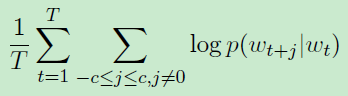
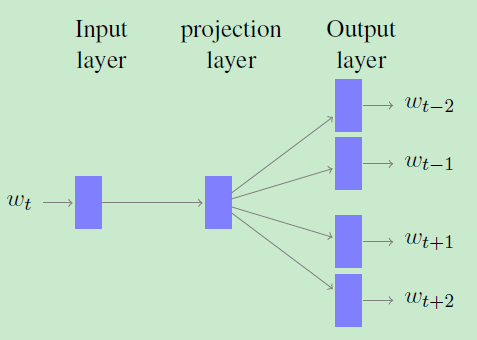
##Phrase Embeddings
where xp is a phrase embedding, and xw is a word embedding. We use this method for computing phrase embeddings as a baseline in our experiments
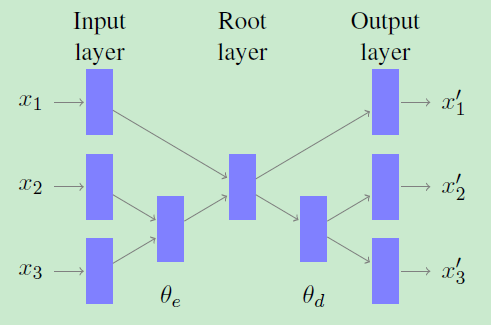
-Unfolding Recursive Auto-encoder
unfolding RAE的結構,在一個三字詞([x1,x2,x3])上。 使用權重矩陣seta(e)對壓縮表示進行編碼,而使用seta(d)對錶示進行解碼並重構句子
##Measuring Similarity
短語嵌入為句子提供了語義意識表示。 為了總結,我們需要測量兩個表示之間的相似性,並將利用以下兩個向量相似性度量。 第一個相似性度量是餘弦相似度,轉換為[0,1]
其中x表示短語嵌入。第二個相似性是基於歐幾里得距離的補充,並計算為:
##Conclusion
本文的研究結果表明在詞彙和片語嵌入方面有很大的應用潛力。 我們相信,通過使用嵌入,我們轉向更多的語義意識彙總系統。