
神經網路優化:指數衰減計算平均值(滑動平均)
Polyak平均會平均優化演算法在引數空間訪問中的幾個點。如果t次迭代梯度下降訪問了點,那麼Polyak平均演算法的輸出是
。
當應用Polyak平均於非凸問題時,通常會使用指數衰減計算平均值:
1. 用滑動平均估計區域性均值
滑動平均(exponential moving average),或者叫做指數加權平均(exponentially weighted moving average),可以用來估計變數的區域性均值,使得變數的更新與一段時間內的歷史取值有關。
變數在t時刻記為
,
為變數v在t時刻的取值,即在不使用滑動平均模型時
,在使用滑動平均模型後,
的更新公式如下:
(1)
上式中,。
相當於沒有使用滑動平均。
假設起始,
,之後每個時刻,依次對變數v進行賦值,不使用滑動平均和使用滑動平均結果如下:
表 1
| t | 不使用滑動平均模型,即給v直接賦值 |
使用滑動平均模型,按照公式(1)更新v |
使用滑動平均模型,按照公式(2)更新v |
| 0 | 0 | / | / |
| 1 | 10 | 1 | 10 |
| 2 | 20 | 2.9 | 13.6842 |
| 3 | 10 | 3.61 | 13.3210 |
| 4 | 0 | 3.249 | 9.4475 |
| 5 | 10 | 3.9241 | 9.5824 |
| 6 | 20 | 5.53169 | 11.8057 |
| 7 | 30 | 7.978521 | 15.2932 |
| 8 | 5 | 7.6806689 | 13.4859 |
| 9 | 0 | 6.91260201 | 11.2844 |
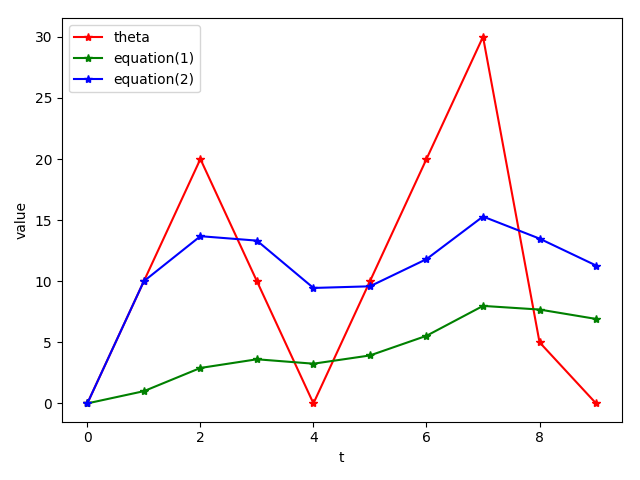
圖 1:三種變數更新方式
Andrew Ng在Course 2 Improving Deep Neural Networks中講到,t時刻變數v的滑動平均值大致等於過去個時刻θ值的平均。這個結論在滑動平均起始時相差比較大,所以有了Bias correction,將
除以
修正對均值的估計。
加入了Bias correction後,更新公式如下:
(2)
t越大,越接近1,則公式(1)和(2)得到的結果將越來越近。
當越大時,滑動平均得到的值越和θ的歷史值相關。如果
,則大致等於過去10個θ值的平均;如果
,則大致等於過去100個θ值的平均。
滑動平均的好處:
佔記憶體少,不需要儲存過去10個或者100個歷史θ值,就能夠估計其均值。(當然,滑動平均不如將歷史值全儲存下來計算均值準確,但後者佔用更多記憶體和計算成本更高)
2. TensorFlow中使用滑動平均來更新變數(引數)
滑動平均可以看作是變數的過去一段時間取值的均值,相比對變數直接賦值而言,滑動平均得到的值在影象上更加平緩光滑,抖動性更小,不會因為某次的異常取值而使得滑動平均值波動很大,如圖 1所示。
TensorFlow 提供了 tf.train.ExponentialMovingAverage 來實現滑動平均。在初始化 ExponentialMovingAverage 時,需要提供一個衰減率(decay),即公式(1)(2)中的。這個衰減率將用於控制模型的更新速度。ExponentialMovingAverage 對每一個變數(variable)會維護一個影子變數(shadow_variable),這個影子變數的初始值就是相應變數的初始值,而每次執行變數更新時,影子變數的值會更新為:
(3)
公式(3)中的 shadow_variable 就是公式(1)中的,公式(3)中的 variable 就是公式(1)中的
,公式(3)中的 decay 就是公式(1)中的
。
公式(3)中,decay 決定了影子變數的更新速度,decay 越大影子變數越趨於穩定。在實際運用中,decay一般會設成非常接近1的數(比如0.999或0.9999)。為了使得影子變數在訓練前期可以更新更快,ExponentialMovingAverage 還提供了 num_updates 引數動態設定 decay 的大小。如果在初始化 ExponentialMovingAverage 時提供了 num_updates 引數,那麼每次使用的衰減率將是:
(4)
這一點其實和Bias correction很像。
3. 滑動平均為什麼在測試過程中被使用?
滑動平均可以使模型在測試資料上更健壯(robust)。“採用隨機梯度下降演算法訓練神經網路時,使用滑動平均在很多應用中都可以在一定程度上提高最終模型在測試資料上的表現。”
對神經網路邊的權重 weights 使用滑動平均,得到對應的影子變數 shadow_weights。在訓練過程仍然使用原來不帶滑動平均的權重 weights,不然無法得到 weights 下一步更新的值,又怎麼求下一步 weights 的影子變數 shadow_weights。之後在測試過程中使用 shadow_weights 來代替 weights 作為神經網路邊的權重,這樣在測試資料上效果更好。因為 shadow_weights 的更新更加平滑,對於隨機梯度下降而言,更平滑的更新說明不會偏離最優點很遠;對於梯度下降 batch gradient decent,我感覺影子變數作用不大,因為梯度下降的方向已經是最優的了,loss 一定減小;對於 mini-batch gradient decent,可以嘗試滑動平均,畢竟 mini-batch gradient decent 對引數的更新也存在抖動。
設,一個更直觀的理解,在最後的1000次訓練過程中,模型早已經訓練完成,正處於抖動階段,而滑動平均相當於將最後的1000次抖動進行了平均,這樣得到的權重會更加robust。