
影象檢索綜述
影象檢索綜述
1.前言
基於內容的影象檢索任務(CBIR)長期以來一直是計算機視覺領域重要的研究課題,自20世紀90年代早期,研究人員先後採用了影象的全域性特徵,區域性特徵,卷積特徵的方法對CBIR任務進行研究和探索,並取得了卓越的成果。自2003年開始,由於SIFT特徵在影象尺度、方向變化問題中的優異表現,十多年來基於區域性描述運算元(如SIFT描述運算元)的影象檢索方法一直被廣泛研究。最近,基於卷積神經網路(CNN)的影象表示方法吸引了社群越來越多的關注,同時這種方法也展現出了令人讚歎的效能。對SIFT一類的方法,我們根據字典本大小,將相關文獻按照字典的大/中/小規模進行組織。對CNN一類的方法,我們主要依據預訓練模型,微調模型和混合模型進行分類和討論。預訓練模型和微調模型方法採用了單通道的影象輸入方法而混合模型則採用了基於塊的特徵提取策略。在下面的章節中我們首先給出一部分在SIFT基礎上的發展狀況,剩餘的部分將重點介紹基於CNN模型的研究現狀,並結合SIFT特徵的提取,闡述CNN模型預SIFT之間的聯絡。
2.影象檢索發展歷程綜述
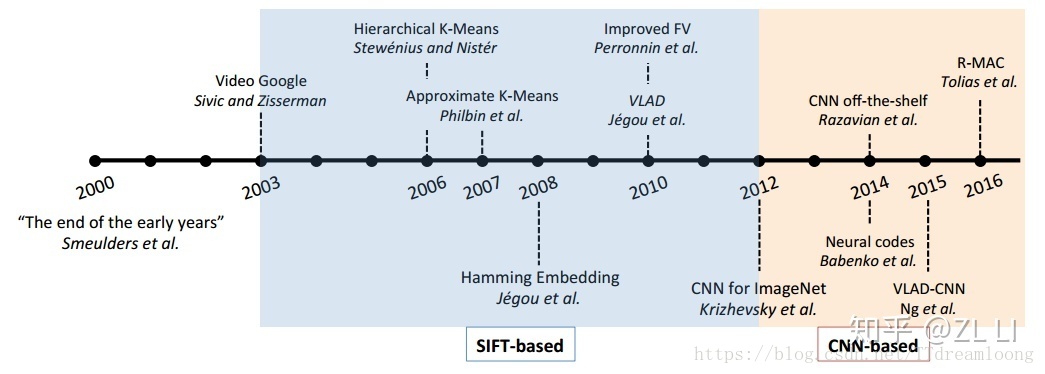
圖2.1 影象檢索時間線
介紹此部分之前,我們結合影象檢索的整體過程,分析此段時間內影象檢索的發展現狀與趨勢,如圖2.2所示。
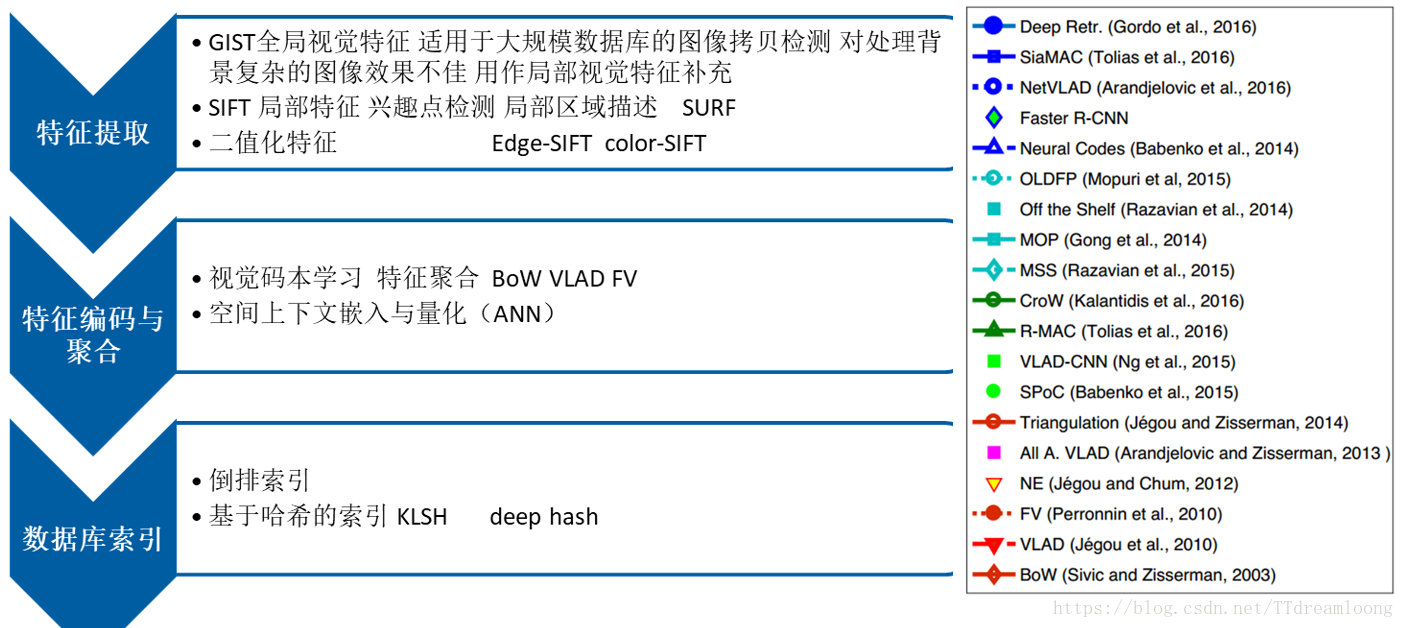
圖2.2 影象檢索過程圖
在檢索之前,首先需要我們先要提取到影象的特徵,也就是特徵提取的階段,從2003年到2012年的這段時間內,提取特徵的方法主要基於SIFT的特徵,由於SIFT特徵在影象尺度、方向變化問題中的優異表現,十多年來基於區域性描述運算元(如SIFT描述運算元)的影象檢索方法一直被廣泛研究。在這期間,研究學者主要貢獻在於提出了多種特徵編碼與聚合的方法,2003年詞袋模型(BoW)【1】進入影象檢索社群的視野,並在2004年結合了SIFT方法符被應用於影象分類任務。在後來的近10年時間裡,見證了BoW模型的優越性,它給影象檢索任務帶來了各種提升。2008年,Jégou et al.
由於預訓練CNN模型是單通模式,因此這種方法在特徵計算中非常高效。考慮到傳輸特性,它的成功在於特徵提取和編碼步驟。這種方法大多采用的是Imagenet預訓練的模型,並且提取的特徵層的深度會直接影響到檢索的效能。最直接的想法就是網路的全連線層(FC layer)提取描述符,在AlexNet中就是FC6或FC7中的描述符。FC描述符是在與輸入影象卷積的層之後生成的,具有全域性表示性,因此可以被視為全域性特徵。它在歐幾里德距離下產生較好的檢索精度,並且可以使用指數歸一化來提高檢索精度。許多最新的檢索方法專注於研究中間層的描述符,在這種方法中,低層網路的卷積核用於檢測區域性視覺模式。作為區域性檢測器,這些濾波器具有較小的感受野並密集地應用於整張影象。與全域性FC特徵相比,區域性檢測器對於諸如截斷和遮擋的影象變換更魯棒,其方式類似於區域性不變數檢測器。區域性描述符與這些中間區域性檢測器緊密耦合,換而言之,它們是輸入影象對這些卷積運算的響應。另一方面,在卷積運算後等到的啟用圖層可以看做是特徵的整合,在這篇綜述中將其稱為“列特徵”【7】。當提取列特徵時,影象由一組描述符表示。為了將這些描述符聚合為全域性表示,目前採用了兩種策略:編碼和直接池合併。
編碼。一組列特徵類似於一組SIFT特徵,因此可以直接使用標準編碼方案。常用的方法就是VLAD和FV演算法,【8】首次將列特徵用VLAD演算法編碼。這個想法後來擴充套件為CNN的微調。BoW編碼同樣也可以使用,具體可見【9】. 每個層內的列特徵被聚整合一個BoW向量,然後跨層連線. 【10】是固定長度表示的一個例外,這篇文章將列特徵用大小為25K的碼本量化,還採用了倒排索引結構來提升效率。
池化。 CNN特徵與SIFT的主要區別在於前者在每個維度上都有明確的含義,也就是對輸入影象的特定區域的濾波器響應。因此,除了上面提到的編碼方案之外,直接池化技術也可以產生具有區分度的特徵。【11】提出的最大卷積啟用(MAC),在沒有扭曲或裁剪影象的情況下,MAC用單個前向傳遞來計算全域性描述符。特別地,MAC計算每個中間特徵對映的最大值,並將所有這些值串聯在一個卷積層內。在其多區域版本中,使用積分圖演算法和最似最大運算元進行快速計算。隨後區域性的MAC描述符隨著一系列歸一化和PCA白化操作被一起合併。【12】在中間特徵對映上採用最大或平均池化。同時大家也發現最後一層卷積層(如VGGNet的pool5)在池化後達到的準確率要高於FC描述符以及其他卷積層。除了直接特徵池化,在池化之前給每個層內的特徵圖分配一些特定的權重也是有益的。Babenko et al.【13】提出“目標物件往往出現在影象中心”這樣一個先驗知識,並在總池化前對特徵圖施加一個2-D高斯掩膜。【14】改進了MAC表示法,他們將高層語義和空間上下文傳播到底層神經元,以提高這些底層啟用神經元的描述能力。Kalantidis et al.【15】使用了一個更常規的加權策略,他們同時執行特徵對映和通道加權以突出高啟用的空間響應,同時減少異常突發情況的影響。此外,還有一些研究是對卷積特徵進行區域分析。Tolias et al.【16】提出R-MAC。這種方法使用一個特定區域對給定的卷積層進行最大池化,以生成一系列的區域向量,是一種對卷積特徵進行聚合的方法。對生成的區域進行一些處理(L2歸一化、PCA白化和L2歸一化),然後使用求和池化將其聚合成一個密集表達。這種方法的一個不足是它使用的一個固定位置的網格。對此,一些方法在R-MAC的基礎之上進行了改進。Jimenez et al.【17】使用(CAMs)的方法對R-MAC進行了改進。CAMs生成一系列表示影象中各部分割槽域重要性的空間圖,該空間圖是和影象的類別資訊有關的。該方法之後使用每一個圖對卷積特徵進行加權處理,得到了一系列類向量,之後進行一些處理得到R-MAC中介紹的區域向量。同樣,Cao et al.【18】提出直接從卷積層中獲得一系列基本區域,然後使用一種可適應的重排方法。Lanskar 和 Kannala 【19】使用直接從卷積特徵獲得的顯著性方法來對R-MAC的區域重要性進行加權。此外,Simeoni et al.【20】在最近的研究中也提出一種從卷積特徵中獲得的顯著性方法,該方法對各通道進行加權求和,其中權重表示的是通道的稀疏性。他們在R-MAC的均勻取樣的基礎之上進行改進,提出一種直接從顯著性特徵圖中提取一系列矩形區域的方法。
雖然預先訓練的CNN模型已經取得了令人驚歎的檢索效能,但在指定訓練集上對CNN模型進行微調也是一個熱門話題。當採用微調的CNN模型時,影象級的描述符通常以端到端的方式生成,那麼網路將產生最終的視覺表示,而不需要額外的顯式編碼或合併步驟。
用於微調的CNN結構主要分為兩類:基於分類的網路和基於驗證的網路。基於分類的網路被訓練以將建築分類為預定義的類別。通常訓練集和查詢影象之間通常不存在類重疊。驗證網路可以使用孿生網路(siamese network)結合成對損失函式(pairwise loss)或三元損失函式(triplet loss),這種方法已經被更廣泛地用於微調網路任務中。【21】中採用了基於AlexNet的孿生網路和對比損失函式。【16】用MAC成代替全連線層。【22】用 l2 正則後的MAC層輸出計算對比損失函式。【23】在Landmark資料庫上對三元損失網路和區域提取網路進行微調,這項工作的的優越性在於物體其定位能力,它很好地在特徵學習和提取步驟中排除了影象背景。【24】在最後一個卷積層中插入一個類似VLAD編碼層,通過反向傳播進行訓練。與此同時,設計了一個新的三元損失函式來利用弱監督的Google Street View Time Machine資料。
混合式方法中使用多網路傳遞方式。許多影象塊從輸入影象中獲得並被輸入網路中進行特徵提取,隨後進行編碼/池化。由於“檢測器+描述符”的方式和基於SIFT的方法很相似,因此我們稱其為“混合式”方法。這種方法的效率通常比單通傳遞要低。
在混合方法中,特徵提取過程包括影象塊檢測和描述符生成。對第一步而言,主要有三種區域檢測器。第一種檢測器是網格化影象塊。【25】中使用了兩個尺寸滑動視窗的策略來生成影象塊。【6】中首先對資料集進行裁剪和旋轉,然後將其劃分為不同尺度的影象塊。
第二類是具有不變性的關鍵點/區域檢測器。例如高斯差分特徵點在【26】中使用。MSER區域檢測器在【27】中被使用。第三種是區域建議方法,它也同樣提供了潛在物件可能的位置資訊。Mopuri et al.【28】使用選擇性搜尋策略來提取影象塊,而邊緣區域方法在【29】中使用。在【30】中使用區域建議網路(RPN)來對目標進行定位。【27】證實了CNN一類的區域描述是有效的,並且在除模糊影象之外的影象匹配任務要優於SIFT描述符,對於給定的影象塊,混合CNN方法通常使用全連線層或池化的方法來整合CNN特徵。這些研究從多尺度的影象區域中提取4096維FC特徵或目標建議區域。另一方面,Razavian et al.【7】還在最大池化後採用中間描述符來作為區域描述符。
混合方法的編碼/索引過程類似於基於SIFT的檢索,如同在小碼本下的VLAD / FV編碼或大碼本下的倒排索引。【6】【7】【31】這些工作提取每個影象的多個區域描述符進行多對多匹配,這種方法稱為稱為“空間搜尋”。該方法提高了檢索系統對平移和尺度變化的魯棒性,但可能會遇到效率問題。另一種使用CNN最高層特徵編碼的策略是在基於SIFT編碼(如FV)的最後面建立一個CNN結構(主要由全連線層組成)。通過在自然影象上訓練一個分類模型,中間的全連線層可以被用來進行檢索任務。
3.小結
對於以上的討論,我們將影象檢索分為三類,基於混合方法的,基於預訓練模型的,基於微調模型的,總的來說檢索的方法往更輕量級,更簡單的方法過度。SIFT的方法逐漸被CNN網路取代,但是在某些方面,又可以作為CNN特徵的補充。
第一,混合方法可被視為從SIFT到基於CNN的方法的過渡方法,除了將CNN特徵提取為區域性描述符之外,它在所有方面都類似於基於SIFT的方法。由於在影象塊特徵提取期間需要多次訪問網路,因此特徵提取步驟的效率可能會受到影響。
第二,單向CNN方法傾向於將SIFT和混合方法中的各個步驟結合起來。“預訓練單向網路”一類方法整合了特徵檢測和描述的步驟;在“微調單向網路”中,影象級描述符通常是在端到端模式下提取的,因此不需要單獨的編碼過程。在【19】中,集成了類似“PCA”層以減少區分維數,進一步完善了端到端的特徵學習。
第三,出於效率上的考慮,特徵編碼的固定長度表示方法越來越流行。它可以通過聚集區域性描述符(SIFT或CNN)、直接匯或端到端特徵計算的方法來獲得。通常,諸如PCA的降維方法可以在固定長度的特徵表達中使用,ANN搜尋方法(如PQ或雜湊)可用於快速檢索。
參考文獻
【1】J. Sivic and A. Zisserman, “Video google: A text retrieval approach to object matching in videos,” in ICCV, 2003
【2】H. Jégou, M. Douze, and C. Schmid, “Hamming embedding and weak geometric consistency for large scale image search,” in ECCV, 2008
【3】F. Perronnin, J. Sánchez, and T. Mensink, “Improving the fisher kernel for large-scale image classification,” in ECCV, 2010
【4】H. Jégou, M. Douze, C. Schmid, and P. Pérez, “Aggregating local descriptors into a compact image representation,” in CVPR, 2010
【5】A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” in NIPS, 2012
【6】A. Sharif Razavian, H. Azizpour, J. Sullivan, and S. Carlsson, “Cnn-features off-the-shelf: an astounding baseline for recognition,” in CVPR Workshops, 2014
【7】A. S. Razavian, J. Sullivan, S. Carlsson, and A. Maki, “Visual instance retrieval with deep convolutional networks,” in ICLR workshops, 2015.
【8】J. Ng, F. Yang, and L. Davis, “Exploiting local features from deep networks for image retrieval,” in CVPR Workshops, 2015
【9】P. Kulkarni, J. Zepeda, F. Jurie, P. Perez, and L. Chevallier, “Hybrid multi-layer deep cnn/aggregator feature for image classification,”in ICASSP, 2015.
【10】E. Mohedano, K. McGuinness, N. E. O’Connor, A. Salvador,F. Marqués, and X. Giró-i Nieto, “Bags of local convolutional features for scalable instance search,” in ACM MM, 2016.
【11】G. Tolias, R. Sicre, and H. Jégou, “Particular object retrieval with integral max-pooling of cnn activations,” in ICLR, 2016.
【12】A. S. Razavian, J. Sullivan, S. Carlsson, and A. Maki, “Visual instance retrieval with deep convolutional networks,” in ICLR workshops, 2015.
【13】A. Babenko and V. Lempitsky, “Aggregating local deep features for image retrieval,” in ICCV, 2015.
【14】L. Xie, L. Zheng, J. Wang, A. Yuille, and Q. Tian, “Interactive:Inter-layer activeness propagation,” in CVPR, 2016.
【15】Y. Kalantidis, C. Mellina, and S. Osindero, “Cross-dimensional weighting for aggregated deep convolutional features,” in ECCV,2016.
【16】G. Tolias, R. Sicre, and H. Jégou, “Particular object retrieval with integral max-pooling of cnn activations,” in ICLR, 2016.
【17】A. Jimenez, J. M. Alvarez, and X. Giro-i Nieto. Classweighted convolutional features for visual instance search.In 28th British Machine Vision Conference (BMVC), September 2017.
【18】J. Cao, L. Liu, P. Wang, Z. Huang, C. Shen, and H. T. Shen.Where to focus: Query adaptive matching for instance retrieval using convolutional feature maps. arXiv preprint
arXiv:1606.06811, 2016.
【19】Z. Laskar and J. Kannala. Context aware query image representation for particular object retrieval. In Scandinavian Conference on Image Analysis, pages 88–99. Springer, 2017
【20】O. Simeoni, A. Iscen, G. Tolias, Y. Avrithis, and O. Chum. ´Unsupervised deep object discovery for instance recognition.arXiv preprint arXiv:1709.04725, 2017.
【21】S. Bell and K. Bala, “Learning visual similarity for product design with convolutional neural networks,” ACM Transactions on Graphics, vol. 34, no. 4, p. 98, 2015.
【22】F. Radenovi´c, G. Tolias, and O. Chum, “Cnn image retrieval learns from bow: Unsupervised fine-tuning with hard examples,” in ECCV, 2016.
【23】A. Gordo, J. Almazán, J. Revaud, and D. Larlus, “Deep image retrieval: Learning global representations for image search,” in ECCV, 2016
【24】R. Arandjelovi´c, P. Gronat, A. Torii, T. Pajdla, and J. Sivic, “Netvlad: Cnn architecture for weakly supervised place recognition,” in CVPR, 2016
【25】Y. Gong, L. Wang, R. Guo, and S. Lazebnik, “Multi-scale orderless pooling of deep convolutional activation features,” in ECCV, 2014
【26】S. Zagoruyko and N. Komodakis, “Learning to compare image patches via convolutional neural networks,” in CVPR, 2015.
【27】P. Fischer, A. Dosovitskiy, and T. Brox, “Descriptor matching with convolutional neural networks: a comparison to sift,” arXiv:1405.5769, 2014
【28】K. Mopuri and R. Babu, “Object level deep feature pooling for compact image representation,” in CVPR Workshops, 2015.
【29】T. Uricchio, M. Bertini, L. Seidenari, and A. Bimbo, “Fisher encoded convolutional bag-of-windows for efficient image retrieval and social image tagging,” in ICCV Workshops, 2015.
【30】S. Ren, K. He, R. Girshick, and J. Sun, “Faster r-cnn: Towards realtime object detection with region proposal networks,” in NIPS, 2015.
【31】L. Xie, R. Hong, B. Zhang, and Q. Tian, “Image classification and retrieval are one,” in ICMR, 2015.