
吳恩達課程學習筆記--第一週第二課:深度學習的實踐層面
訓練,驗證,測試
在機器學習的小資料時代,70%驗證集,30%測試集,或者60%訓練,20%驗證和20%測試。大資料時代,如果有百萬條資料,我們可以訓練集佔98%,驗證測試各佔1%。
深度學習的一個趨勢是越來越多的訓練集和測試集分佈不匹配,根據經驗,我們要確保兩個資料集來自同一分佈。
測試集的作用是給最後的模型提供無偏估計,如果不需要無偏估計,也可以不設定測試集
偏差,方差
考慮如下的資料,如果採用線性模型,可能會導致高偏差就是不能較好的擬合數據,稱為欠擬合;而如果擬合一個非常複雜的分類器,可能會導致高方差,稱為過擬合。
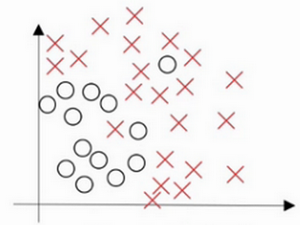
我們想要達到的是中間的情況
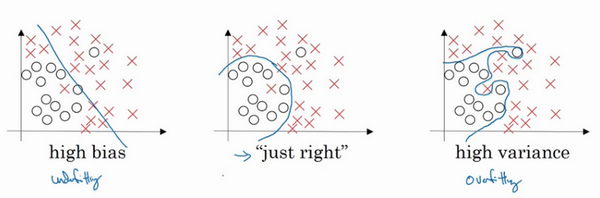
診斷方差和偏差的方式通過分析在訓練集和驗證集的的誤差。
方差是通過檢視訓練集和驗證集的誤差,加入訓練集誤差為1%,驗證集誤差為11%,則可能是過度擬合,導致高方差。偏差,加入訓練集誤差15%,測試集誤差16%,而人的誤差為1%,這是我們認為偏差過大,而方差合理。
機器學習基礎
通常首先看偏差,如果偏差很大,嘗試選擇不同的神經網路結構和延長訓練時間,直到可以擬合數據為止。
當偏差降到可以接受的數值,再檢視方差,通過驗證集效能。如果方差過大,可以通過增加資料集、正則化等方法,不斷嘗試。
在正則適度的情況,一個更大的網路可以在不影響方差的同時減少偏差;採取更多的資料可以在不過多影響偏差的前提下減少方差。
正則化
正則化和增加資料是解決過擬合問題(高方差)的有效方法,正則化引數是
是訓練樣本的個數,
稱為
的歐幾里得範數(2範數)的平方,包含了每一層的w的元素的平方和,此方法稱為L2正則化。因為
包含了絕大多數引數,所以引數b可以不加。L1正則加的則是
,使用L1正則,w會變得稀疏,但卻沒有降低太多記憶體。具體計算如下
在反向傳播時加上
,則計算梯度時相當於給梯度W乘了
,該值小於1,因而正則化也被稱為權重衰減。
直觀理解正則化,w權重的值需要有一定的約束,當增大w的同時,我們在損失函式計算上加上該權重的平方,使其承受一定的損失,有助於維持模型的穩定。下面我們藉助啟用函式,我們通過正則化權重衰減w值較小,則獲取的z也會較小,再通過啟用函式時,就會處於下圖中紅線段,近似於線性函式,而不是一個高度複雜的非線性函式,從而減少過擬合。

dropout正則化
dropout會遍歷網路的每一層,把每個節點以一定的概率消除,得到一個節點更少規模更小的網路,然後使用backprop。
使用正則化最常用的方法反向隨機失活如下:
首先生成一個與每層W相同的矩陣,0~1的隨機數
d = np.random.rand(w.shape[0],w.shape[1])<keep_size
然後看是否大於0.8(假設keep prob=0.8),大於0.8的我們置為0
然後與權重元素相乘
w = np.multipy(w,d)
然後將w向外擴充套件,除以0.8,用來修正我們所需的那20%,
最後,測試階段不需要dropout,因為測試階段進行預測時,我們不希望輸出結果是隨機的。
理解 dropout
dropout會使得不能依賴於任何一個特徵,產生收縮權重的平方範數的效果,與之前的L2正則化效果類似,實施dropout會壓縮權重,來預防過擬合;L2對不同權重的衰減是不同的,它取決於啟用函式倍增的大小。
總結一下,dropout功能類似於L2,與L2不同的是,應用的方式的不同會導致dropout的不同,甚至更適用於不同的輸入範圍。
關於keep-prob的設定,對於W矩陣過大的神經層可以考慮較小的keep-prob,如果某一層不擔心出現過擬合,keep-prob可以為1。
dropout的應用主要在計算機視覺,因為沒有足夠的資料,很容易造成過擬合。如果不存在過擬合的情況,不需要使用dropout。
當然,dropout的一大缺點就是代價函式J不再被明確定義,梯度下降的效能難於複查。
其他正則化方法
資料擴增,通過影象裁剪、翻轉等資料處理,增大資料集
early stopping 代表提早停止訓練,如下圖,通過提早結束訓練來減少過擬合的情況。
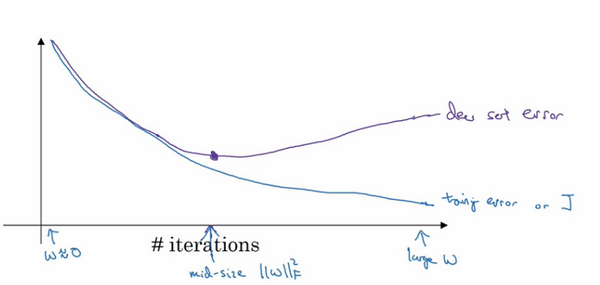
early stopping的優點是,只執行一次梯度下降,就可以找到w的較小值,中間值和較大值,無需
的很多值,缺點是不能獨立處理兩個問題,提早停止梯度下降,也就停止了優化代價函式J,所以代價函式可能不夠小,但是又不希望出現過擬合。
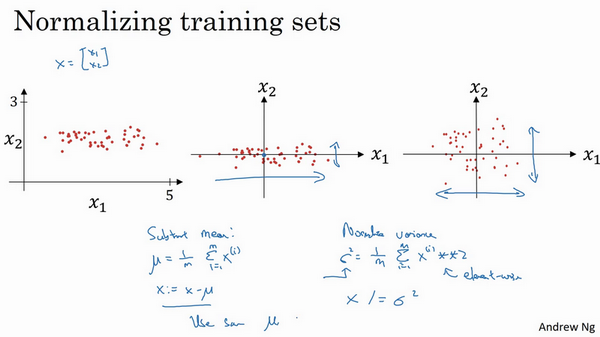
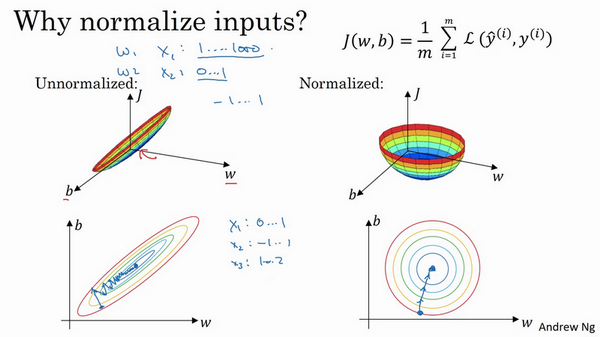
歸一化輸入
我們希望無論是訓練集還是測試集都是經過相同的均值和方差定義的資料轉換
- 零均值
- 歸一化方差
如下圖,假設有兩個維度 ,通過零均值化和標準化,零均值化就是每一個維度減去維度的平均值,標準化則是所有零均值化後的資料除以方差
通過歸一化可以使代價函式更平均,以引數w和引數b為例,如下圖,歸一化後特徵都在相似的範圍內,而不是1到1000,0到1,使得代價函式優化起來更加簡單快速。圖二中的結果函式是一個更圓的球形輪廓,那麼不管從哪個位置開始,梯度下降法都能更直接的找到最小值。
梯度爆炸/梯度消失
梯度爆炸和消失是指在訓練神經網路的時候,導數或坡度變得非常大或非常小。比如我們只考慮初始的一種情況,一個L層的網路,假設啟用函式為線性函式 ,每一層的有兩個神經元假設為1.5倍的單位矩陣,那麼預測結果 ,如果對於深度神經網路L較大,那麼預測的y值也會很大,實際上它是指數級增長的。同樣如果為0.5倍的單位矩陣,會變得指數級下降。
神經網路的權重初始化
我們想出了一個不完整的解決方案,有助於我們為神經網路更謹慎的選擇隨機初始化引數。
假設一個神經元接受四個輸入
,暫時忽略
,為了預防
過大或過小,隨著
越大,
應該越小,最合理的方法是設定
,n表示輸入神經元的特徵數,實際上我們要做的是
,
就是我們餵給第l層神經單元的數量。通常relu啟用函式引用高斯分佈的方差,使用
。
對於tanh啟用函式
,被稱為Xavier初始化
以及
我們可以給上述引數再增加一個乘法引數,但上述方差引數的調優優先順序並不高。通過上述的方法,我們確實降低的梯度爆炸和梯度消失問題。
梯度檢驗
所謂梯度檢驗,實際上是通過微分求導,即
求導,這種方式計算的梯度更準確,但同時也耗費大量的計算資源。
梯度檢驗就是將損失函式J的所有引數W和b組成一個大的一維向量,然後依次對每一個引數利用微分求導,獲得一個一維向量,同時反向傳播的梯度也組成一個一維向量,兩者求歐幾里得距離。下圖中的分母是為了防止分子的計算結果太小。通常
取