
文字檢測模型概覽(下)
Textboxes
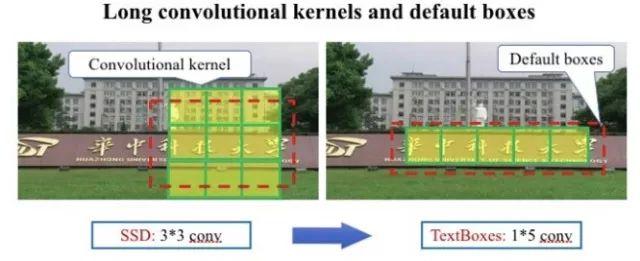
Textboxes是基於SSD框架的圖文檢測模型,訓練方式是端到端的,執行速度也較快。如下圖所示,為了適應文字行細長型的特點,候選框的長寬比增加了1,2,3,5,7,10這樣初始值。為了適應文字行細長型特點,特徵層也用長條形卷積核代替了其他模型中常見的正方形卷積核。為了防止漏檢文字行,還在垂直方向增加了候選框數量。為了檢測大小不同的字元塊,在多個尺度的特徵圖上並行預測文字框, 然後對預測結果做NMS過濾。【1】
Minghui Liao, Baoguang Shi, Xiang Bai, Xinggang Wang, Wenyu Liu
TextBoxes++
Textboxes++是Textboxes的升級版本,目的是增加對傾斜文字的支援。為此,將標註資料改為了旋轉矩形框和不規則四邊形的格式;對候選框的長寬比例、特徵圖層卷積核的形狀都作了相應調整。【1】

Minghui Liao, Baoguang Shi, Xiang Bai. TextBoxes++: A Single-Shot Oriented Scene Text Detector, TIP 2018.
WordSup
這是百度的工作,做法也比較直接:通過一個弱監督的框架使用單詞級別的標註來訓練字元檢測器,然後通過結構分析將檢測到的字元組合成單詞。【3】先用合成數據集來做mask的預訓練。
Han Hu, Chengquan Zhang, Yuxuan Luo, Yuzhuo Wang, Junyu Han, Errui Ding. WordSup: Exploiting Word Annotations for Character based Text Detection, 2017 International Conference on Computer Vision.
DDR
①為了解決傾斜場景文字的檢測,作者提出了將現有檢測方法分類間接回歸和直接回歸兩大類。下圖中左邊的圖就是間接回歸的示意圖,所謂間接回歸,意思就是網路預測的不是直接的bounding box,而是首先需要提proposal,然後預測的是和這個proposal之間的偏移距離。右圖是直接回歸的示意圖,直接回歸直接從每一個畫素點回歸出這個文字的四個角點。②為了不讓網路confuse,作者沒有把text region中的所有畫素點都作為正樣本,而是多加了一個dont care的過渡區域。【2】③融合不同層的特徵,通過多工學習進行文字分割以及文字框的迴歸。【3】

Wenhao He, Xu-Yao Zhang, Fei Yin, Cheng-Lin Liu. Deep Direct Regression for Multi-Oriented Scene Text Detection, 2017
BorderLearning
1) We analyze the insufficiencies of the classic non-text and text settings for text detection. 2) We introduce the border class to the text detection problem for the first time, and validate that the decoding process is largely simplified with the help of text border. 3) We collect and release a new text detection PPT dataset containing 10,692 images with non-text, border, and text annotations. 4) We develop a lightweight (only 0.28M parameters), fully convolutional network (FCN) to effectively learn borders in text images.

Yue Wu ; Prem Natarajan. Self-Organized Text Detection with Minimal Post-processing via Border Learning, ICCV 2017.
Single Shot Text Detector with Regional Attention
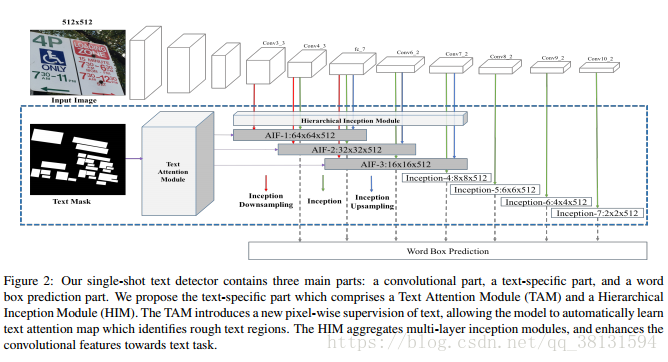
在SSD基礎上加了一個模組,這個模組引入了attention的機制即預測text mask,通過文字和非文字的判別讓檢測更加關注到文字區域上。【3】
Pan He, Weilin Huang, Tong He, Qile Zhu, Yu Qiao, Xiaolin Li. Single Shot Text Detector with Regional Attention, ICCV 2017.
RRD
作者認為,Detect Box的迴歸依賴於文字框的旋轉敏感特徵而text/non-text分類則依賴於旋轉不敏感特徵。傳統的方法對於這兩個任務共享特徵,由於這兩個任務的不相容導致了效能的下降。作者提出了以下方法,在應對長文字和方向變化比較劇烈的情況,效果尤為顯著。
To address this issue, we propose to perform classification and regression on features of different characteristics, extracted by two network branches of different designs. Concretely, the regression branch extracts rotation-sensitive features by actively rotating the convolutional filters, while the classification branch extracts rotation-invariant features by pooling the rotation-sensitive features.
- Rotation-Sensitive Regression: Different from standard CNN features, RRD extracts rotation-sensitive features with active rotating filters (ARF). An ARF convolves a feature map with a canonical filter and its rotated clones.ARF makes N − 1 clones of the canonical filter by rotating it to different angles.It produces a response map of N channels, each corresponding to the response of the canonical filter or its rotated clone.Besides, since the parameters between the N filters are shared, learning ARF requires much less training examples.
- Rotation-Invariant Classification: ORN achieves rotation invariance by pooling responses of all N response maps.the rotationsensitive feature maps are pooled along their depth axis.Since the pooling operation is orderless and applied to all N response maps, the resulting feature map is locally invariant to object rotation.


Minghui Liao, Zhen Zhu, Baoguang Shi, Gui-song Xia, Xiang Bai. Rotation-Sensitive Regression for Oriented Scene Text Detection, CVPR 2018.
參考文獻
【2】論文閱讀與實現--DDR
【3】深度學習大講堂