
文字檢測模型概覽(上)
以下內容摘自各個部落格,文中會進行標註,做個人概覽用,沒有仔細斟酌對錯。
CTPN(2016)
CTPN是目前流傳最廣、影響最大的開源文字檢測模型,可以檢測水平或微斜的文字行。文字行可以被看成一個字元sequence,而不是一般物體檢測中單個獨立的目標。同一文字行上各個字元影象間可以互為上下文,在訓練階段讓檢測模型學習影象中蘊含的這種上下文統計規律,可以使得預測階段有效提升文字塊預測準確率。【1】
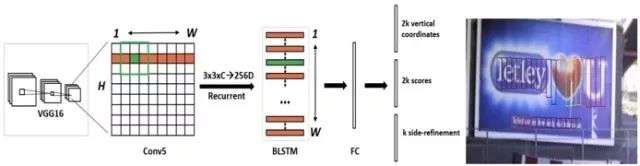
- 用VGG16的前5個Conv stage(到conv5)得到feature map(W*H*C)
- 在Conv5的feature map的每個位置上取3*3*C的視窗的特徵,這些特徵將用於預測該位置k個anchor(anchor的定義和Faster RCNN類似)對應的類別資訊,位置資訊。
- 將每一行的所有視窗對應的3*3*C的特徵(W*3*3*C)輸入到RNN(BLSTM)中,得到W*256的輸出
- 將RNN的W*256輸入到512維的fc層
- c層特徵輸入到三個分類或者回歸層中。第二個2k scores 表示的是k個anchor的類別資訊(是字元或不是字元)。第一個2k vertical coordinate和第三個k side-refinement是用來回歸k個anchor的位置資訊。2k vertical coordinate表示的是bounding box的高度和中心的y軸座標(可以決定上下邊界),k個side-refinement表示的bounding box的水平平移量。這邊注意,只用了3個引數表示迴歸的bounding box,因為這裡默認了每個anchor的width是16,且不再變化(VGG16的conv5的stride是16)。迴歸出來的box如Fig.1中那些紅色的細長矩形,它們的寬度是一定的。
- 用簡單的文字線構造演算法,把分類得到的文字的proposal(圖Fig.1(b)中的細長的矩形)合併成文字線【2】
RRPN(2017)
基於旋轉區域候選網路(RRPN, Rotation Region Proposal Networks)的方案,將旋轉因素併入經典區域候選網路(如Faster RCNN)。【1】
整體結構和Faster-RCNN可以說是一樣的。訓練階段,一個文字區域的ground truth用一個5元組(x,y,h,w,θ)來表示,(x,y)表示邊界框的幾何中心的座標。高度h表示短邊的長度,寬度w表示長邊的長度,而θ表示x正軸到邊界框長邊的角度。統的錨點公使用大小(scale)和比例(aspect ratio)兩個變數,作者對傳統的錨點進行了改進,以適應自然場景下的文字檢測。首先,新增了方向這個變數,加入6個方向角:−π/6、0、π/6、π/3、π/2、2π/3。其次,由於文字區域的形狀比較特殊,將比例調整為:1:2、1:5和1:8。大小還是8,16和32保持不變。

RRPN中方案中提出了旋轉感興趣區域(RRoI,Rotation Region-of-Interest)池化層,將任意方向的區域建議先劃分成子區域,然後對這些子區域分別做max pooling、並將結果投影到具有固定空間尺寸小特徵圖上。【1】
EAST(2017)
EAST(Efficient and Accuracy Scene Text detection pipeline)模型中,首先使用全卷積網路(FCN)生成多尺度融合的特徵圖,然後在此基礎上直接進行畫素級的文字塊預測。該模型中,支援旋轉矩形框、任意四邊形兩種文字區域標註形式。對應於四邊形標註,模型執行時會對特徵圖中每個畫素預測其到四個頂點的座標差值。對應於旋轉矩形框標註,模型執行時會對特徵圖中每個畫素預測其到矩形框四邊的距離、以及矩形框的方向角。該模型檢測英文單詞效果較好、檢測中文長文字行效果欠佳。或許,根據中文資料特點進行鍼對性訓練後,檢測效果還有提升空間。【1】
- Feature extractor stem: 利用Inception的思想,即不同尺寸的卷積核的組合可以適應多尺度目標的檢測,作者在這裡採用PVANet模型,提取不同尺寸卷積核下的特徵並用於後期的特徵組合。
- Feature merging branch: 在這一部分用來組合特徵,並通過上池化和concat恢復到原圖的尺寸。
- Output layer: ①通過一個(1x1,1)的卷積核獲得score_map。score_map與原圖尺寸一致,每一個值代表此處是否有文字的可能性。 ②通過一個(1x1,4)的卷積核獲得RBOX 的geometry_map。有四個通道,分別代表每個畫素點到文字矩形框上,右,底,左邊界的距離。另外再通過一個(1x1, 1)的卷積核獲得該框的旋轉角,這是為了能夠識別出有旋轉的文字。 ③通過一個(1x1,8)的卷積核獲得QUAD的geometry_map,八個通道分別代表每個畫素點到任意四邊形的四個頂點的距離。
- Threshold&NMS過濾: 在假設來自附近畫素的幾何圖形傾向於高度相關的情況下,逐行合併幾何圖形,並且在合併同一行中的幾何圖形時將迭代合併當前遇到的幾何圖形。【4】

SegLInk(2017)
SegLink模型的標註資料中,先將每個單詞切割為更易檢測的有方向的小文字塊(segment),然後用鄰近連線(link )將各個小文字塊連線成單詞。這種方案方便於識別長度變化範圍很大的、帶方向的單詞和文字行。【1】
閱讀原論文Section 3.1部分很好理解。
- Given an input image I of size wI × hI , the model outputs a fixed number of segments and links, which are then filtered by their confidence scores and combined into whole word bounding boxes. A bounding box is a rotated rectangle denoted by b = (xb, yb, wb, hb, θb), where xb, yb are the coordinates of the center, wb, hb the width and height, and θb the rotation angle.
- Segments and links are detected on 6 of the feature layers, which are conv4 3, conv7, conv8 2, conv9 2, conv10 2, and conv11.A convolutional predictor with 3 × 3 kernels is added to each of the 6 layers to detect segments and links. We index the feature layers and the predictors by l = 1, . . . , 6.
- We detect segments by estimating the confidence scores and geometric offsets to a set of default boxes [14] on the input image.For simplicity, we only associate one default box with a feature map location.(一些轉換公式省略)
- Within-Layer Link Detection: Links are not only necessary for combining segments into whole words but also helpful for separating two nearby words – between two nearby words, the links should be predicted as negative.we define the within-layer neighbors of a segment as its 8-connected neighbors on the same feature layer.A predictor outputs 16 channels for the links to the 8-connected neighboring segments. Every 2 channels are softmax-normalized to get the score of a link.
- Cross-Layer Link Detection: segments of the same word could be detected on multiple layers at the same time, producing redundancies. To address this problem, we further propose another type of links, called cross-layer links.A cross-layer link connects segments on two feature layers with adjacent indexes.Every segment has 4 cross-layer neighbors. The correspondence is ensured by the double-size relationship between the two layers.



Baoguang Shi, Xiang Bai, Serge Belongie. Detecting Oriented Text in Natural Images by Linking Segments, CVPR 2017
PixelLink
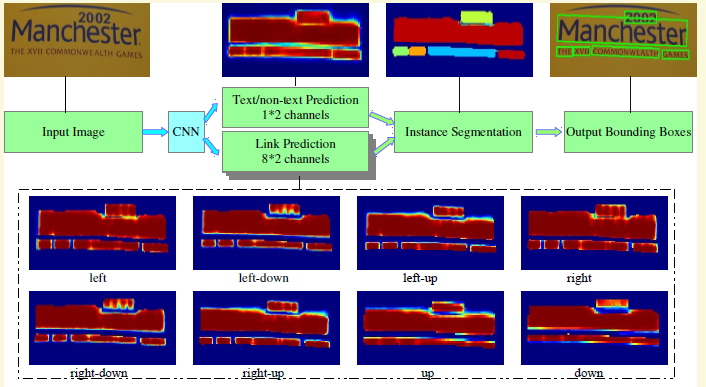
相當於EAST和SegLink的結合,只不過由SegLink中連線segment轉變為連線pixel。自然場景影象中一組文字塊經常緊挨在一起,通過語義分割方法很難將它們識別開來,所以PixelLink模型嘗試用例項分割方法解決這個問題。
- the whole model has two separate headers, one for text/non-text prediction, and the other for link prediction. Softmax is used in both, so their outputs have 1*2=2 and 8*2=16 channels, respectively.
- It is worth noting that, given two neighboring positive pixels, their link are predicted by both of them, and they should be connected when one or both of the two link predictions are positive.
- Bounding boxes of CCs are then extracted through methods like minAreaRect in OpenCV (Its 2014).
Dan Deng, Haifeng Liu, Xuelong Li, Deng Cai. PixelLink: Detecting Scene Text via Instance Segmentation, AAAI 2018
參考文獻
【3】論文閱讀之R-RPN
【4】EAST: An Efficient and Accurate Scene Text Detector 自然場景下的文字識別(原理及程式碼理解)