
AlexNet 講解及pytorch實現 ----1 AlexNet主要技術突破點
一. AlexNet網路結構
2012年,該網路ILSVRC-2012影象分類的冠軍,top-5的識別錯誤率為15.3%, 比第二名高出10個百分點。
- 下面是論文中的網路結構:

原始網路將模型分為兩部分,分開在兩個GPU上訓練,與下面合併的網路結構等價:

- 各部分網路結構的引數及輸入輸出影象大小計算:

二. AlexNet的意義及技術優勢
1. 在神經網路羅發展歷史上的重要意義
- 證明了CNN在複雜模型下的有效性
- 使用GPU訓練可以在可接受的時間內得到結果
以上兩點推動了深層網路結構的構建以及採用GPU的加速訓練方法 。
2. 技術上引進新的思想
-
啟用函式使用Relu, 不再使用sigmoid和tanh函式,其優勢在於收斂速度更快,使得訓練時間更短, 已成為卷積神經網路最常用的啟用函式。https://blog.csdn.net/NOT_GUY/article/details/78749509
函式形式:
函式形狀如下:

但是Relu函式最大的缺點是,
Dead ReLU Problem(神經元壞死現象):某些神經元可能永遠不會被啟用,導致相應引數永遠不會被更新(在負數部分,梯度為0)導致如此的原因有兩個:
-
引數初始化問題: 採用Xavier的變體
He initialization,思想是保證輸入和輸出方差相同,故引數服從均值為0,方差為 的正態分佈 。以及BN層的使用,簡單的說就是線上性變化和非線性啟用函式之間,將數值做一次高斯歸一化和線性變化 -
learning rate太高導致在訓練過程中引數更新太大: 設定曉得學習率以及再用adagrad, adam等自動調整學習率的優化演算法
-
-
區域性響應歸一化層(Local Response Normalization Layer)
LRN層只存在於第一層卷積層和第二層卷積層的啟用函式後面,引入這一層 的主要目的,主要是為了防止過擬合,增加模型的泛化能力.
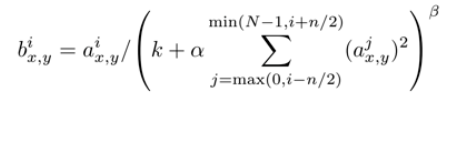

但是對於這種方法對於演算法的優化程度存在爭議,後期的網路結構基本不再採用這種方法。
-
採用重疊的最大池化層,來“稍微”減輕過擬合
kernal_size = 33, s=2 ,通過提取33小矩形框中的最大值來提取區域性特徵,減少冗餘資訊。
傳統的卷積層中,相鄰的池化單元是不重疊的。比如stride>=kernel_size,而如果stride<kernel_size,將使用重疊的池化層。
3. 論文減輕過擬合的方法
-
資料集擴增
大部分演算法過擬合的原因是資料集數量不夠,通過翻轉,裁剪等方法來增加資料集的數量 -
採用Dropout,來減輕過擬合
實際類似於模型集合的方式,在全連線層中使用Dropout,比如設概率為0.5,則每個隱藏層神經元的輸入以0.5的概率輸出為0。輸出為0的神經元相當於從網路中去除,不參與前向計算和反向傳播。所以對於每次輸入,神經網路都會使用不同的結構。注意在測試時需要將Dropout層去掉。 -
使用權重衰減的損失函式優化演算法

為學習率, 為第 訓練的權重
接來下分析pytorch的AlexNet實現,注意AlexNet沒有使用LRN層。
部落格引用:
1… Xavier 初始化引數的推導
http://andyljones.tumblr.com/post/110998971763/an-explanation-of-xavier-initialization
4. 引數初始化討論https://blog.liexing.me/2017/10/24/deep-learning-weight-initialization/
3.啟用函式討論:https://blog.csdn.net/NOT_GUY/article/details/78749509
5. LRN的探討
https://blog.csdn.net/hduxiejun/article/details/70570086
http://yeephycho.github.io/2016/08/03/Normalizations-in-neural-networks/