
什麼是B+Tree
什麼是B+Tree
B+Tree的定義
B+Tree是B樹的變種,有著比B樹更高的查詢效能,來看下m階B+Tree特徵:
1、有m個子樹的節點包含有m個元素(B-Tree中是m-1)
2、根節點和分支節點中不儲存資料,只用於索引,所有資料都儲存在葉子節點中。
3、所有分支節點和根節點都同時存在於子節點中,在子節點元素中是最大或者最小的元素。
4、葉子節點會包含所有的關鍵字,以及指向資料記錄的指標,並且葉子節點本身是根據關鍵字的大小從小到大順序連結。
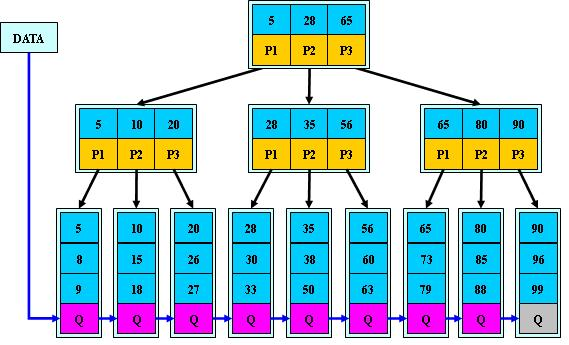
更直觀的圖

1、紅點表示是指向衛星資料的指標,指標指向的是存放實際資料的磁碟頁,衛星資料就是資料庫中一條資料記錄。
2、葉子節點中還有一個指向下一個葉子節點的next指標,所以葉子節點形成了一個有序的連結串列,方便遍歷B+樹。
B+樹的優勢
1、更加高效的單元素查詢
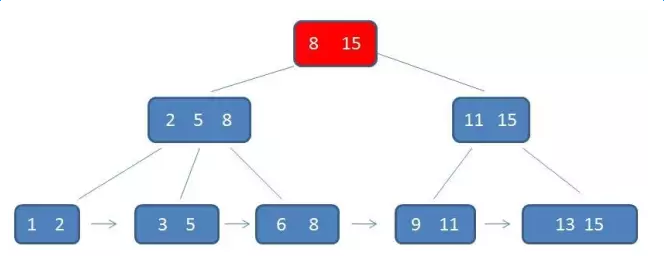
B+樹的查詢元素3的過程:
第一次磁碟IO
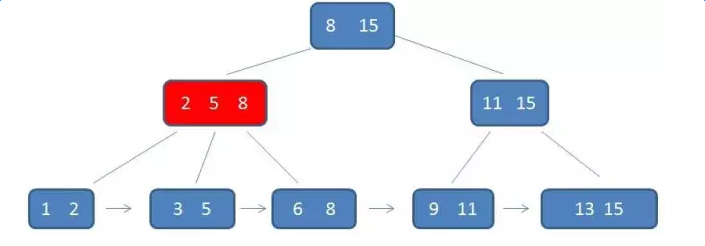
第二次磁碟IO
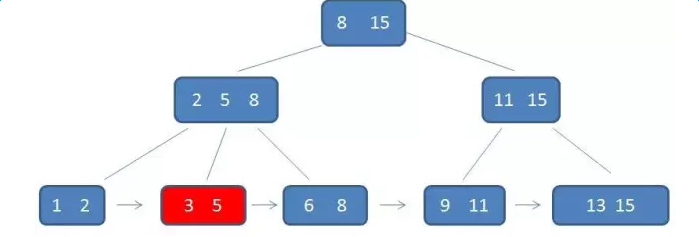
第三次磁碟IO
這個過程看下來,貌似與B樹的查詢過程沒有什麼區別。但實際上有兩點不一樣:
a、首先B+樹的中間節點不儲存衛星資料,所以同樣大小的磁碟頁可以容納更多的節點元素,如此一來,相同數量的資料下,B+樹就相對來說要更加矮胖些,磁碟IO的次數更少。
b、由於只有葉子節點才儲存衛星資料,B+樹每次查詢都要到葉子節點;而B樹每次查詢則不一樣,最好的情況是根節點,最壞的情況是葉子節點,沒有B+樹穩定。
2、葉子節點形成有順連結串列,範圍查詢效能更優
B樹範圍查詢3-8的過程
a、先查詢3
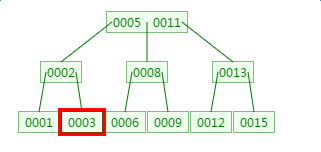
b、再查詢4、5、6、7、8,中間過程省略,直接到8的查詢

這裡查詢的範圍跨度越大,則磁碟IO的次數越多,效能越差。
B+樹範圍查詢3-11的過程
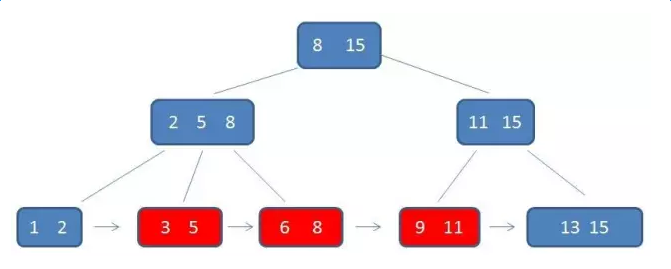
先從上到下找到下限元素3,然後通過連結串列指標,依次遍歷得到元素5/6/8/9/11;如此一來,就不用像B樹那樣一個個元素進行查詢。
總結
1.單節點可以儲存更多的元素,使得查詢磁碟IO次數更少。
2.所有查詢都要查詢到葉子節點,查詢效能穩定。
3.所有葉子節點形成有序連結串列,便於範圍查詢。
PS:在資料庫的聚集索引(Clustered Index)中,葉子節點直接包含衛星資料。在非聚集索引(NonClustered Index)中,葉子節點帶有指向衛星資料的指標。
參考文獻:
【1】很直觀的圖:http://www.jianshu.com/p/6f68d3c118d6
【2】《演算法導論》
轉:https://www.cnblogs.com/dongguacai/p/7241860.html