
線性判別分析
線性判別分析(Linear Discriminant Analysis)
在分類器的理論中,貝葉斯分類器是最優的分類器,而為了得到最優的分類器,我們就需要知道類別的後驗概率P(Ck|x)。
這裡假設fk(x)是類別Ck的類條件概率密度函式,πk 是類別Ck的先驗概率,毫無疑問有∑kπk=1。根據貝葉斯理論有:
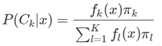
由於πk幾乎是已知的,所以對於貝葉斯公式而言,最重要的就是這個類條件概率密度函式fk(x),很多演算法之所以不同,主要的就是對這個類條件概率密度函式的引數形式的假設不同,比如:
線性判別分析(LDA)假設fk(x)是均值不同,方差相同的高斯分佈
二次判別分析(QDA)假設fk(x)是均值不同,方差也不同的高斯分佈
高斯混合模型(GMM)假設fk(x)是不同的高斯分佈的組合
很多非引數方法假設fk(x)是引數的密度函式,比如直方圖
樸素貝葉斯假設fk(x)是Ck邊緣密度函式,即類別之間是獨立同分布的
各種演算法的不同,基本上都是來至於對類條件概率密度函式的不同,這一點在研究分類演算法的時候,一定要銘記在心。
前面已經說過了LDA假設fk(x)是均值不同,方差相同的高斯分佈,所以其類條件概率密度函式可以寫為:

這裡,特徵xx的維度為pp維,類別CkCk的均值為μkμk,所有類別的方差為ΣΣ。
在前面提到過,一個線性分類器,在判別式函式δk(x)或者後驗概率函式P(Ck|x)上加上一個單調函式f(⋅)後,可以得變換後的函式是x的線性函式,而得到的線性函式就是決策面。LDA所採用的單調變換函式f(⋅)和前面提到的Logistics Regression採用的單調變換函式一樣,都是logit 函式:log[p/(1−p)],對於二分類問題有:
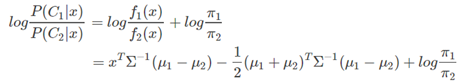
可以看出,其決策面是一個平面。
根據上面的式子,也可以很容易得到LDA的決策函式是:
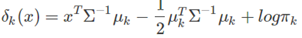
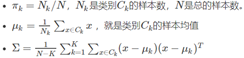
二次判別分析QDA
二次判別函式假設fk(x)是均值不同,方差也不同的高斯分佈,和LDA相比,由於Σk是不一樣 ,所以其二次項存在,故其決策面為:
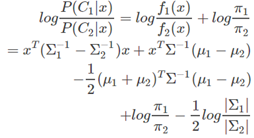
其對應的判別函式為:

使用
# 線性判別式分析
lda = LinearDiscriminantAnalysis(solver='svd', store_covariance=True)
y_pred = lda.fit(X, y).predict(X)
# 二次判別分析
qda = QuadraticDiscriminantAnalysis(store_covariances=True)
y_pred = qda.fit(X, y).predict(X)