
20172308 《程式設計與資料結構》第九周學習總結
教材學習內容總結
第 十五 章 圖
樹的定義是,除根結點之外,樹的每個結點都恰好有一個父結點。
而如果違背了這一個前提,即允許樹的每個結點連通多個其它結點,不再有父親、孩子之說,即得到孩子的概念
一、無向圖
- 圖與樹類似,也由結點和這些結點之間的連線構成(這些結點就是圖的頂點,而結點之間的連線就是圖的邊)
- 無向圖是一種邊為無序結點對的圖
- 如果圖中的兩個頂點之間有一條連通邊,則稱這兩個頂點是鄰接的(也互稱鄰居)
- 連通一個頂點及其自身的邊稱為自迴圈或環
- 如果無向圖擁有最大數目的連通頂點的邊,則認為這個無向圖是完全的
- 對有n個頂點的無向圖,要使該圖為完全的,要求有n(n-1)/2條邊(這裡假設其中沒有邊是自迴圈的)
- 路徑是圖中的一系列邊,每條邊連通兩個頂點(無向圖中的路徑是雙向的)
- 如果無向圖中的任意兩個頂點之間都存在一條路徑,則認為這個無向圖是連通的
- 環路是一種首頂點和末頂點相同且沒有重邊的路徑
- 沒有環路的圖稱為無環的
- 無向樹是一種連通的無環無向圖,其中一個元素被指定為樹根
二、有向圖
- 有向圖(雙向圖),它是一種邊為有序頂點對的圖
- 有向圖的路徑是圖中連通兩個頂點的有向邊序列(有向圖中的路徑不是雙向的)
- 如果有向圖中沒有環路,且有一條從A到B的邊,則可以把頂點A安排在頂點B之前。這種排列得到的頂點次序稱為拓撲序
- 為什麼說樹也是圖?需要滿足的條件?
三、網路(加權圖)
- 網路:一種每條邊都帶有權重的或代價的圖
- 根據需要,網路可以是無向的,也可以是有向的
- 對於網路,可以用一個三元組來表示每條邊(包括起始頂點、終止頂點、權重)
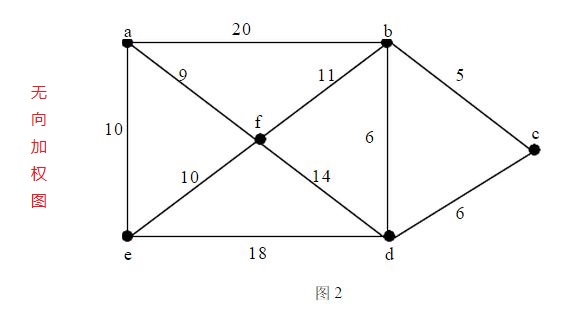
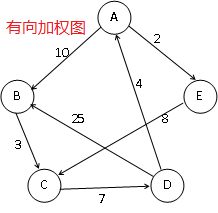
四、常用的圖演算法
1。 比如:各種遍歷演算法、尋找最短路徑演算法、尋找網路中最低代價路徑的演算法,回答一些簡單圖相關問題(如圖是否連通,兩個頂點間最短路徑)
2。 遍歷:
- 廣度優先遍歷:類似於樹的層次遍歷
深度優先遍歷:類似於樹的前序遍歷
但是要注意的是:圖中不存在根結點,因此圖的遍歷可以從其中的任一頂點開始廣度優先遍歷的演算法:用一個佇列和一個無序列表來構造(使用佇列管理遍歷,使用無序列表構造出結果)
第一步,起始點進入佇列traveralQueue,同時標記該頂點為已訪問的( visited)
然後開始迴圈,該循直持續到 traveralQueue為空時停止,在這個迴圈中,從 traveralQueue中取出這個首頂點,並將它新增到 resultList的末端
接著,讓所有與當前頂點鄰接且尚未被標記為 visited的各個頂點依次進入佇列 traversalQuet,同時把它們逐個標記為 visited
然後再重複上述迴圈
對每個已訪問的頂點都重複這一過程,直到 traversalQucue為空時結束,這時意味著無法再找到任何新的頂點
現在resultList即以廣度優先次序(從給定的起始頂點開始)存放著各個頂點深度優先遍歷的演算法:其構造使用了與廣度優先遍歷同樣的邏輯,不過在深度優先遍歷中用 traversalstack代替了 traversalQueue
演算法中還有另一處不同:在頂點尚未新增到 resultList之前,並不想標記該頂點為visited圖的深度優先遍歷與廣度優先遍歷唯一的不同是:前者使用的是棧而不是佇列來管理遍歷
3。 測試連通性
- 不論哪個為起始頂點,當且僅當廣度優先遍歷中的頂點數目等於圖中的頂點數目時,該圖才是連通的
- 關於連通性的解釋
4。 最小生成樹
- 生成樹是一棵含有圖中所有頂點和部分邊(但可能不是所有邊)的樹
- 最小生成樹:其邊的權重總和小於或等於同一個圖中其它任一棵生成樹的權重總和
- 最小生成樹的演算法:
5。 判定最短路徑:判定圖的“最短”路徑有兩種情況
第一種:是判定起始頂與目標頂點之間的字面意義上的最短路徑,也就是兩個頂點之間的最小邊數。
將廣度優先遍歷演算法轉變成尋找最短路徑的演算法,只需在遍歷期間再對每個頂點存另兩個資訊即可:從起始頂點到本頂點的路徑長度,以及路徑中作為本頂點前驅的那個頂點
接著修改迴圈,使得當抵達目標頂點時迴圈將終止,最短路徑的路徑長度就是從起始頂點到目標頂點前驅的路徑長度再加1;
如果要輸出這條最短路徑上的頂點,只需沿前驅鏈回溯即可第二種:尋找加權圖的最便宜路徑。這裡不使用頂點佇列(這要求我們必須根據頂點的遭遇次數來探究圖),而是用一個 minheap或優先佇列來儲存頂點,
基於總權重(從起地頂點到本頂點的權重和)來衡量頂點對,這樣我們總是能優先沿著最便宜的路徑來遊歷
對每個頂點都必須儲存該頂點的標籤,(迄今為止)從起始頂點到本頂點的最便宜路徑的權重,路徑上本頂點的前驅
在 minheap中將儲存頂點、對每條已經遇到但尚未遊歷的候選路徑來權衡頂點對,
從 minheap取出頂點的時候,會權衡取自 minheap的頂點對;
如遇到一個頂點的權重小於目前本頂點中已儲存的權重,則會更新路徑的代價
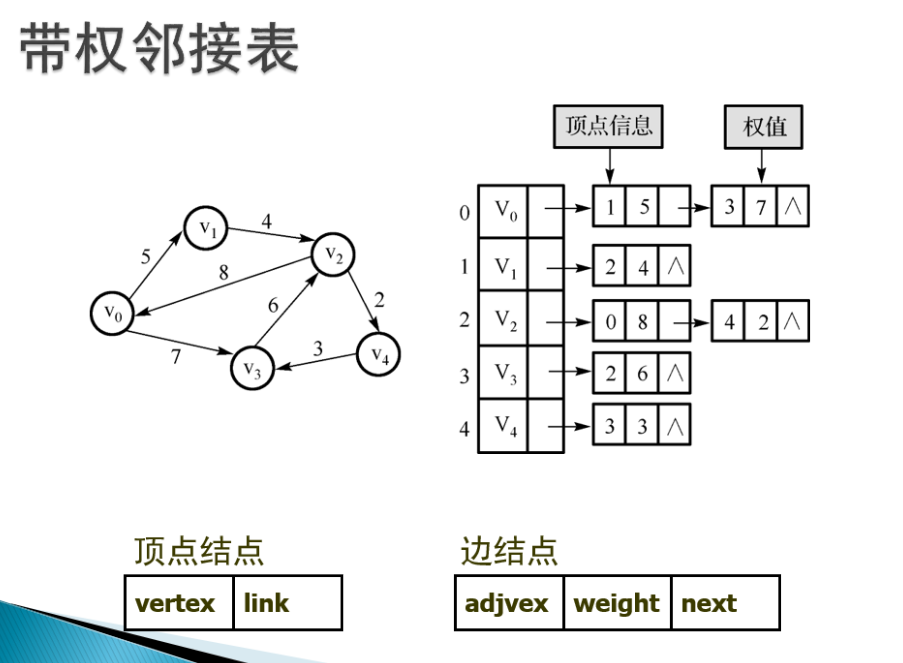
五、圖的實現策略
1。鄰接列表:
對於圖節點來說,每個節點可以有多達n-1條邊與其它結點相連,因此用一種類似於連結串列的動態節點來儲存每個節點帶有的邊,這種連結串列稱為鄰接列表
2.。鄰接矩陣:
- 每個單元都表示了圖中兩個頂點交接情況的二維陣列(這些交接情況由一個表明兩個頂點是否連通的布林值表示)
無向圖的矩陣是對稱的,所以對於無向圖來說,沒必要表示整個矩陣,只需給出矩陣對角線的一側即可
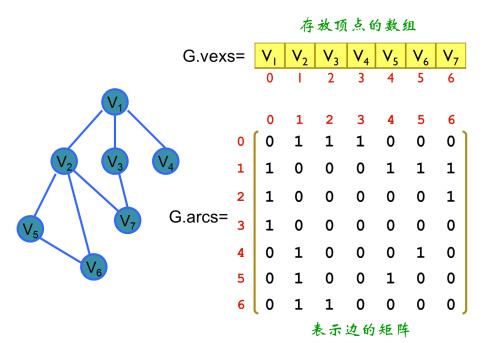
對於有向圖來說,所有邊都是定向的,故而矩陣不對稱
教材學習中的問題和解決過程
問題1:什麼是“拓撲序”?在哪裡應用?
問題1解析:
百度的解釋:
拓撲序:在圖中從頂點A到頂點B有一條有向路徑,則頂點A一定排在頂點B之前。滿足這樣的條件的頂點序列稱為一個拓撲序。
what ???
這就是拓撲序的定義?(手動笑哭)
這麼高大上的名字,就是這個意思?A到B有多條路徑,每一個路徑,A都是起點,B是終點(自己瞎造的理解。。。)
那麼這麼 “ 簡單 ” 的定義有什麼用嗎?還專門定義了一個名詞?
那就是——拓撲排序:獲得一個拓撲序列的過程
說實話,我也沒覺得這個排序有多麼厲害。。。
但是,看了相關參考,才知道專門定義一個這樣的名詞是很有必要的
舉個栗子:
比如大學的課程安排:
例如:
如果你想學習離散數學,前提你必須要預修高等數學這門課。
如果你想學習資料結構這門課,那麼你要先學了程式設計這門課,等等等等
所以大學都會根據課程之間的聯絡來安排學生學習課程的先後次序
所以這個先後順序,就用到了有向圖來表示:
比如下面的這張有向圖:
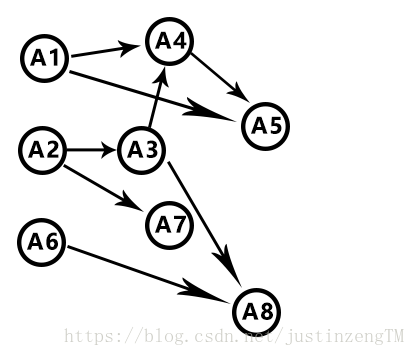
圖中的每一個頂點對應每一門課,如果兩門課之間是有預修關係的,即如果前一門課是後一門課的預修課程,那麼表示這兩門課的兩個頂點間就有一條有向邊
這樣的圖符合上面所說的拓撲序,即兩個頂點之間的邊表示的是兩個之間的前後關係
選擇不同的課程都會按照一定的路徑從A開始到B結束,這樣多個課程混雜也就形成了如上的有向圖
問題2:為什麼深度優先遍歷在頂點尚未新增到 resultList之前,並不想標記該頂點為visited?
問題2解析:
要明白這個問題,得先知道深度優先遍歷是如何遍歷的
課本說它與廣度優先遍歷的邏輯一致
百度的解釋為:從圖的某個頂點v出發,訪問此頂點,然後從v的未被訪問過的鄰接點出發深度優先遍歷圖,直至圖中的所有和v有路徑相通的頂點都被訪問到(對於連通圖來講)
廣度優先遍歷中,頂點進入佇列然後標記為已訪問,然後開始迴圈,該循直持續到佇列為空時停止,在這個迴圈中,從佇列中取出這個首頂點,並將它新增到 resultList的末端
而深度優先遍歷不同的就在這裡:在頂點尚未新增到 resultList之前,並不想標記該頂點為visited
這有什麼區別嗎?
我覺得區別可能在於,深度遍歷是用棧來實現的,不同於佇列實現的廣度優先遍歷,
佇列可以按照先進先出的規則,將鄰接的節點按照一定順序直接設定為已訪問存進去,取出來的時候即按照存進去的順序取出來
而棧是後進先出的,所以在新增進棧的時候,不把他們標記為已訪問,而當將他們取出來,放進resultList裡的時候才將他們標記為已訪問,
這樣可以保證一條路走到黑?
結合百度的資料,總結一下二者的區別:
- 1) 二叉樹的深度優先遍歷的非遞迴的通用做法是採用棧,廣度優先遍歷的非遞迴的通用做法是採用佇列。
- 2) 深度優先遍歷:對每一個可能的分支路徑深入到不能再深入為止,而且每個結點只能訪問一次。
廣度優先遍歷:又叫層次遍歷,從上往下對每一層依次訪問,在每一層中,從左往右(也可以從右往左)訪問結點,訪問完一層就進入下一層,直到沒有結點可以訪問為止。 - 3)深度優先搜素演算法:不全部保留結點,佔用空間少;有回溯操作(即有入棧、出棧操作),執行速度慢。
廣度優先搜尋演算法:保留全部結點,佔用空間大; 無回溯操作(即無入棧、出棧操作),執行速度快。 - 通常 深度優先搜尋法不全部保留結點,擴充套件完的結點從資料庫中彈出刪去,這樣,一般在資料庫中儲存的結點數就是深度值,因此它佔用空間較少。
所以,當搜尋樹的結點較多,用其它方法易產生記憶體溢位時,深度優先搜尋不失為一種有效的求解方法。
廣度優先搜尋演算法,一般需儲存產生的所有結點,佔用的儲存空間要比深度優先搜尋大得多,因此,程式設計中,必須考慮溢位和節省記憶體空間的問題。
但廣度優先搜尋法一般無回溯操作,即入棧和出棧的操作,所以執行速度比深度優先搜尋要快些
【參考資料】
圖的深度優先遍歷和廣度優先遍歷理解
總結深度優先與廣度優先的區別
十二、圖的遍歷--(2)深度優先搜尋演算法
圖的深度優先遍歷
程式碼執行中的問題及解決過程
問題1:PP15.1,利用鄰接列表實現無向圖,如何實現?
問題1解決過程:
對比著課本上給出的鄰接矩陣的實現程式碼、其它網上部落格,並參考了侯澤洋同學的程式碼實現了鄰接列表的程式碼實現,並記錄下瞭如下分析:
1。 鄰接矩陣是通過一個二維陣列實現了對一個點與其它點是否連通的記錄
而如果用鄰接列表的話,則不需要用二維陣列記錄連線情況:直接將與某點鄰接的點鏈在此點的後面即可
如圖:

將節點存在列表當中,在每個節點後面鏈上其它與其鄰接的節點(形成連結串列)
對比程式碼(上方為鄰接矩陣,下方為鄰接列表):
protected int numVertices; // 當前頂點個數
protected boolean[][] adjMatrix; // 鄰接矩陣
protected T[] vertices; // 頂點的值
protected int modCount;// 修改標記數
/* ****************************************************************************** */
protected int numVertices; // 當前頂點個數
protected List<List<Integer>> adjMatrix; // 鄰接的節點鏈成的連結串列
protected List<T> vertices; //存放節點的列表
protected int modCount;
2。 新增節點addvertices操作
- 鄰接矩陣需要將新增的節點與其它節點之間設定為false儲存在二維數組裡,在新增節點前還得判斷陣列是否滿以及執行擴充套件陣列操作
- 鄰接列表不需要上述操作,無序判斷陣列是否滿,直接新增即可,但是要記錄儲存新增節點的索引值
對比程式碼(上方為鄰接矩陣,下方為鄰接列表):
public void addVertex(T vertex) {
// 如果頂點滿了
if ((numVertices + 1) == adjMatrix.length)
expandCapacity();
vertices[numVertices] = vertex;// 新增結點
// 新增的這個頂點和每一個頂點的連邊預設的設定
for (int i = 0; i < numVertices; i++) {
adjMatrix[numVertices][i] = false;
adjMatrix[i][numVertices] = false;
}
numVertices++;
modCount++;
}
/* ******************************************************************************** */
public void addVertex(T vertex) {
vertices.add(vertex);//直接新增到列表中
List list = new ArrayList();
list.add(numVertices);
adjMatrix.add(list);//儲存新增節點的索引值
numVertices++;
modCount++;
}
3。 刪除節點removeVertex操作
鄰接矩陣的節點刪除操作,是直接通過覆蓋完成的:
首先先判斷刪除的節點索引值是否存在
然後先將節點所在的二維陣列中的值行列用下一行、右一列依次向上,向左進行覆蓋
最後將節點陣列中的要刪除的節點處的下一位依次向上移,即完成刪除操作
第二步是相當於完成了刪除邊的操作鄰接列表不用上述操作,直接執行列表具有的刪除節點操作,接下來就是刪除與節點鄰接的邊的操作(具體操作在下面刪除邊的程式碼中分析)
對比程式碼(上方為鄰接矩陣,下方為鄰接列表):
public void removeVertex(int index){
if (indexIsValid(index)) {
for (int a = 0; a < vertices.length; a++) {//相當於完成了刪除邊的操作
adjMatrix[a][index] = adjMatrix[a][index + 1];
adjMatrix[index][a] = adjMatrix[index + 1][a];
}
for (int i = index; i < numVertices; i++) {//刪除節點
vertices[index] = vertices[index + 1];
}
}
}
@Override
public void removeVertex(T vertex) {
if (isEmpty()) {
throw new EmptyCollectionException("Graph");
}
removeVertex(getIndex(vertex));
}
/* ********************************************************************* */
public void removeVertex(T vertex) {
int index = getIndex(vertex);
if (indexIsValid(index))
vertices.remove(index);//刪除節點
for (int i = 0;i < adjMatrix.get(index).size()-1;i++)//找到與節點相鄰接的所有節點並刪除邊
{
int x = adjMatrix.get(index).get(i+1);
removeEdge(x,index);
}
adjMatrix.remove(index);//刪除記錄的節點的索引值
numVertices--;
modCount++;
}
4。 新增邊addEdge操作
- 鄰接矩陣直接找到索引處的兩個節點,將兩個索引處對應的二位陣列設定成true即可(無向的)
- 鄰接列表先找到第一個索引處的節點,然後將下一個索引處的節點新增到其後即可(無向的,索引反過來在執行一遍即可)
這裡有兩種實現方式,在兩個索引處加邊,或在兩個節點間加邊
對比程式碼(上方為鄰接矩陣,下方為鄰接列表):
@Override
public void addEdge(T v1, T v2) {
addEdge(getIndex(v1), getIndex(v2));
}
private void addEdge(int index1, int index2) {
if (indexIsValid(index1) && indexIsValid(index2)) {//兩個索引都存在
adjMatrix[index1][index2] = true;
adjMatrix[index2][index1] = true;
modCount++;
}
}
/* ********************************************************************* */
public void addEdge(int index1,int index2)
{
if (indexIsValid(index1)&&indexIsValid(index2))
{
(adjMatrix.get(index1)).add(index2);
(adjMatrix.get(index2)).add(index1);
modCount++;
}
}
public void addEdge(T vertex1,T vertex2)
{
int index1 = getIndex(vertex1);
int index2 = getIndex(vertex2);
if (indexIsValid(index1)&&indexIsValid(index2))
{
(adjMatrix.get(index1)).add(index2);
(adjMatrix.get(index2)).add(index1);
modCount++;
}
}
5。 刪除邊removeEdge操作
- 鄰接矩陣:與新增邊正好相反,把兩個索引處對應的二位陣列設定成false即可
- 鄰接列表:與新增邊正好相反,先找到第一個索引處的節點,但這裡需要判斷,下一索引處的節點是否與其鄰接
如果鄰接,則將下一個索引處的節點刪除即可(無向的,索引反過來在執行一遍即可)
這裡也有兩種實現方式,在兩個索引處刪邊,或在兩個節點間刪邊
對比程式碼(上方為鄰接矩陣,下方為鄰接列表):
@Override
public void removeEdge(T v1, T v2) {
removeEdge(getIndex(v1), getIndex(v2));
}
private void removeEdge(int index1, int index2) {
if (indexIsValid(index1) && indexIsValid(index2)) {
adjMatrix[index1][index2] = false;
adjMatrix[index2][index1] = false;
modCount++;
}
}
/* ********************************************************************* */
@Override
public void removeEdge(T vertex1, T vertex2) {
int index1 = getIndex(vertex1);
int index2 = getIndex(vertex2);
if (indexIsValid(index1)&&indexIsValid(index2))
{
if (adjMatrix.get(index1).contains(index2))
{
(adjMatrix.get(index1)).remove(adjMatrix.get(index1).indexOf(index2));
(adjMatrix.get(index2)).remove(adjMatrix.get(index2).indexOf(index1));
modCount++;
}
}
}
public void removeEdge(int index1, int index2) {
if (indexIsValid(index1)&&indexIsValid(index2))
{
if ((adjMatrix.get(index1)).contains(index2))
{
(adjMatrix.get(index1)).remove(adjMatrix.get(index1).indexOf(index2));
(adjMatrix.get(index2)).remove(adjMatrix.get(index2).indexOf(index1));
modCount++;
}
}
}
【參考資料】
Java實現無向圖鄰接表
java:鄰接表無向圖的連結串列實現法
鄰接表無向圖(三)之 Java詳解
用鄰接表實現無向圖
用鄰接表表示圖【java實現】
無向圖的實現(鄰接表) 圖的遍歷
問題2:PP15.7,即實現一個無向網路
問題2解決過程:
無向網路只要在無向圖的基礎上,在邊的相關方法里加上權重引數即可
在書上的鄰接矩陣實現的程式碼基礎上,把二維陣列的true或false改成相關權重值即可,刪除邊,只要將其賦成無窮大POSITIVE_INFINITY或其他的什麼
執行結果截圖:
本週錯題
本週無錯題
程式碼託管

結對及互評
- 部落格中值得學習的或問題:
- 侯澤洋同學的部落格排版工整,介面很美觀,並且本週還對部落格排版、字型做了調整,很用心
- 問題總結做得很全面:對課本上不懂的程式碼會做透徹的分析,即便可以直接拿過來用而不用管他的含義
- 對教材中的細小問題都能夠關注,並且主動去百度學習
- 程式碼中值得學習的或問題:
- 對於程式設計的編寫總能找到角度去解決
- 本週結對學習情況
- 20172302
- 結對學習內容
- 第十五 章內容:圖
學習進度條
| 程式碼行數(新增/累積) | 部落格量(新增/累積) | 學習時間(新增/累積) | 重要成長 | |
|---|---|---|---|---|
| 目標 | 5000行 | 30篇 | 400小時 | |
| 第一週 | 0/0 | 1/1 | 4/4 | |
| 第二週 | 560/560 | 1/2 | 6/10 | |
| 第三週 | 415/975 | 1/3 | 6/16 | |
| 第四周 | 1055/2030 | 1/4 | 14/30 | |
| 第五週 | 1051/3083 | 1/5 | 8/38 | |
| 第六週 | 785/3868 | 1/6 | 16/54 | |
| 第七週 | 733/4601 | 1/7 | 20/74 | |
| 第八週 | 2108/6709 | 1/8 | 20/74 | |
| 第九周 | 1425/8134 | 1/9 | 20/94 |