
SEGAN: Speech Enhancement Generative Adversarial Network
論文分析:
一、引言
經典的語音增強(speech enhancement)方法有譜減法(spectral subtraction)、維納濾波(Wiener filtering)、統計模型(statistical model-based methods)和子空間演算法(subspace algorithms)。
論文結合GAN網路提出了SEGAN,並通過實驗發現,SEGAN主要優勢有以下三點:
1、提供一個快速語音增強過程,沒有因果關係是必要的,因此沒有像RNN那樣的遞迴操作。
2、它基於原始音訊做處理,沒有提取特徵,因此沒有對原始資料做出明確的假設。
3、從不同的說話人和噪聲型別中學習,並將他們合併到相同的共享引數中,這使得系統在這些維度上變得簡單和一般化。
二、Generative Adversarial Networks
論文的第二部分,是介紹GAN的,如果有GAN的基礎可以跳過這一節。GAN網路是一種對抗模型,可以將樣本服從Z分佈的樣本對映到服從X分佈的x。
關於GAN的更多解釋:
有人說GAN強大之處在於可以自動的學習原始真實樣本集的資料分佈。為什麼大家會這麼說。
對於傳統的機器學習方法,我們一般會先定義一個模型讓資料去學習。(比如:假設我們知道原始資料是高斯分佈的,只是不知道高斯分佈的引數,這個時候我們定義一個高斯分佈,然後利用資料去學習高斯分佈的引數,最終得到我們的模型),但是大家有沒有覺得奇怪,感覺你好像事先知道資料該怎麼對映一樣,只是在學習模型的引數罷了。
GAN則不同,生成模型最後通過噪聲生成一個完整的真實資料(比如人臉),說明生成模型已經掌握了從隨機噪聲到人臉資料的分佈規律。有了這個規律,想生成人臉還不容易,然而這個規律我們事先是不知道的,我們也不知道,如果讓你說從隨機噪聲到人臉應該服從什麼分佈,你不可能知道。這是一層層對映之後組合起來的非常複雜的分佈對映規律。然而GAN的機制可以學習到,也就是說GAN學習到了真實樣本集的資料分佈。
三、Speech Enhancement GAN 以及 實驗步驟
整個網路全部是由CNN組成,下圖是生成器G,他是一個encooder-decoder。D的結構是encoder,上面接了一個降維層。將8*1024個引數降維8個。
encoder由步長為2的1維卷積層構成。16384×1, 8192×16, 4096×32, 2048×32, 1024×64, 512×64, 256×128, 128×128, 64×256,32×256, 16×512, and 8×1024。
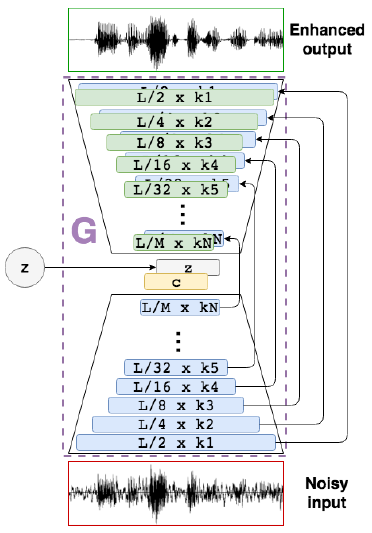
圖二:生成器,encoder-decoder
至於SEGAN訓練,其實跟普通的GAN很類似,如下圖所示,先訓練一個判別器D,D的輸入為純淨訊號和經過生成器增強後的訊號。然後在固定判別器,改變生成器G的引數。

言語強化訓練。虛線代表梯度反向支柱。
其中,有一點,在初步實驗中,我們發現在G的損失中增加一個次要成分是很方便的,以便將它的世代與乾淨的例子之間的距離減至最小。 為了測量這種距離,我們選擇了L1範數,因為它已被證明在影象處理領域有效。
最終G的損失函式如下所示:
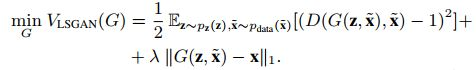
四、結果
分為客觀和主觀評價兩個部分。
4.1 客觀評價
客觀評價有以下幾個指標,都是越大越好:
PESQ: Perceptual evaluation of speech quality, using the wide-band version recommended in ITU-T P.862.2 (from –0.5 to 4.5).
主觀語音質量評估,雖然叫主觀,實際還是個客觀的值。
CSIG: Mean opinion score (MOS) prediction of the signal distortion attending only to the speech signal(from 1 to 5).
CBAK: MOS prediction of the intrusiveness of background noise (from 1 to 5).
COVL: MOS prediction of the overall effect(from 1 to 5).
SSNR: Segmental SNR (from 0 to ∞).
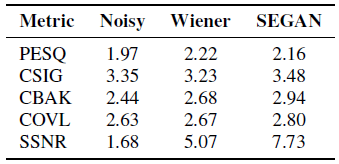
可以看到,SEGAN在PESQ指標上表現稍微差一點。在所有其他指標上,這些指標更與語音失真有關係,SEGAN都比wiener更好。SEGAN產生更少的語音失真(CSIG)和移除噪聲更有效(CBAK和SSNR)。所以,SEGAN能在二者之間取得更好的權衡。
4.2 主觀評價
主觀描述,就是一段音訊,給出它原始音訊、wiener處理的音訊、segan處理後的音訊,不顯示具體哪個對應哪個,讓被測試者打分,1-5之間,分數越高代表越好。 16個測試者,20個句子。效果如下圖。

五、總結
在這項工作中,端對端語音增強方法已經在生成對抗框架內實施。該模型使用編碼器-解碼器完全卷積結構,使得它能夠快速操作來對波形塊進行去噪。 結果表明,不僅該方法是可行的,而且它也可以作當前方法的有效替代。