
Temporal Action Detection with Structured Segment Networks
原文連結:
本文只是對原文的簡單翻譯,不對實驗過程分析,如有不準確的地方,歡迎指教~
SSN:結構化分段網路的時序動作檢測
摘要:SSN:structured segment networks,通過結構化時序金字塔對每一個動作例項的時序結構建模。在金字塔的頂端,引入一個判別模型,包括兩個分類器:動作分類和完整度區分,它能有效的將正樣本從背景和不完整的樣本中分離出來,做出準確的識別和定位。將這些元件整合到同一的網路,可以進行端到端的有效訓練。本文還提出一個簡單高效的temporal action proposals scheme,能產生高質量的proposal。資料集:THUMOS14和 ActivityNet,mAP提高10%。
1.簡介
Temporalaction detection 吸引越來越多的注意力,因為它強大的應用。本文任務是在未修剪的長視訊中檢測人的活動例項,並標出起始和結束位置。
傳統方法的侷限性:資料量,不能準確定位。
本文方法:採用proposal+classification。每一個完整的活動被看成由三部分組成:starting,course,ending。基於上述,建立時序金字塔,將各個組成部分的特徵結合起來,構成整個proposal。金字塔頂端,引入兩個判別模型:活動型別判別和完整度判別。這兩者結合,將proposed segment分成三類:positive proposal,pure background,poorly localized proposals。時序金字塔和判別模型構成統一的網路:SSN(structured segment network)。另外,採用sparse snippet sampling(TSN)。本文還提出用基於temporal actionness signal 的multi-scale grouping 產生動作分段。
本文的主要貢獻如下:1)提出高效的對活動建立時序結構模型的機制,區分complete proposals和incomplete proposals。2)實現端到端的流程。3)提高效能
3.StructuredSegment Network

綠框為候選區域,黃框為擴充套件區域,把黃框的內容分成三部分:starting(黃色),course(綠色),ending(藍色)。額外的兩層處理course部分。將提取的特徵作為five parts的輸入,生成全域性區域描述。Activity classification 和completeness classification基於區域描述產生activity probability和class conditional completeness probability。區域為正樣本的final probability由這兩個分類器的聯合概率決定。訓練中,本文sparsely sample L = 9 snippet。
從input到output,經歷三個key steps:1)temporal proposals。2)temporal pyramid ,產生global proposal representation。3)two classification。
這一部分主要說明如何對給定的proposals進行預測。each proposal 看成starting, course, ending,並對其分別建立representation。通過temporal pyramid pooling合成global representation。然後訓練two classifiers。訓練期間,採用sparse snippet sampling來估計dense samples的temporal pyramid。3.1 Three-StageStructure
Input video可看成snippet 的集合,表示為(St)Tt=1。一個snippet包含多個幀,由多個RGB images和optical flow stack組成。給定N個proposals的集合P= {pi = [si,ei]},每一個P由開始時間si和結束時間ei組成,pi為di= ei – si。為了更好的分析是否為Complete instance,需要把它放到上下文中。因此,增強proposal pi =pi’ = [si’,ei’], si’ = si- di/2,ei’ = ei+di/2(擴充套件一倍)。然後將pi分成3個consecutive interval , psi = [si’, si],pci = [ci’,ci] ,pei = [ei’, e]分別稱為starting、course、ending。
3.2 Structured Temporal Pyramid Pooling
每一個proposal通過temporal pyramid pooling會生成一個global representation。給定增強proposal pi’ ,分成三個階段psi,pci,pei,首先計算stage-wise特徵向量fsi,fci,fei, 然後連線成global representation。
Stage[s,e]包含多個snippet序列,表示為{St|s<=t<=e}。每一個snippet,獲取一個特徵向量vt。基於這些特徵,建立K-Level temporal pyramid如下,each level將interval 分成Bk個部分,i-th part of k-th level, 表示為[ski,eki],特徵為:
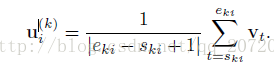
fci= (ui(k)|k=1,……K,i=1,……,Bk)
不同的stage採用不同的方法,course stage用K = 2,starting 和ending 使用one-stage。
3.3Activity and Completeness Classifiers
兩種分類器:activity classifier and a set of completeness classifier。對course,基於 fci,activity classifier A classifies 將inputproposals 分成K+1個類(with labels 1....K),background with label = 0。Completeness classifiers {Ck}k=1K為二分類器,基於{ fsi,fci,fei }預測proposals是否獲取完整的instance。此時completeness不僅取決於proposal,也要考慮它所在的上下文。
所有的分類器都是線性分類器。給定pi , activity classfier 會通過softmax layer生成normalized response。可看做條件概率分佈P(ci |pi), ci為class label。對每一個activity class k,與其對應的completeness classifier Ck會生成條件概率值P(bi|ci,pi),bi決定Pi是否完整。outputs是兩個分佈的聯合分佈。當ci>=1, P(ci, bi| pi) =P(ci | pi)*P(bi|ci, pi),因此loss 可表示為兩個分類器的和。給定proposal pi和label ci
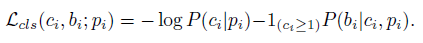
訓練期間,獲取三種proposals samples :1)positive proposals(IOU>0.7);2)background proposals(不包含任何instance);3)incomplete proposals(IOU<0.3)。
3.4Location Regression and Multi-Task Loss
設定一系列的定位迴歸(location regression) {Rk}k=1K,對每一個類別定界。採用RCNN,但是用於1維 temporal regions。給定proposal Pi,同時對間隔中心(interval center ui)和跨度(span ∮i)迴歸。定義multi-task loss:
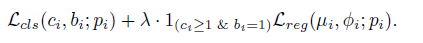
Lreg使用L1 loss function
4.Efficient Training and Inference with SNN
面對計算量大的問題,採用如下解決辦法:
Training with sparse sampling。A augmented proposal p’i分成L=9 segments, 任意在每一個segment取一個snippet。固定求取特徵的數量(不論視訊長度),減少了計算成本,實現了端到端的訓練。
Inferencewith reordered computation。測試期間,每間隔6幀提取一個snippet樣本,建立temporal pyramid。原始的temporal pyramid首先計算特徵,再計算分類和迴歸(不高效)。事實上,每個長視訊會產生上百個proposals,並有很大的重複。
利用這種冗餘,採用position sensitive pooling。由於分類器和迴歸都是線性的,因此,分類和迴歸的關鍵是特徵向量f乘以權重矩陣W。計算公式為:Wf = ∑Wjfj,j代表pyramid的不同region。這裡fj是對region rj 的snippet 特徵做的平均池化(average pooling)。因此:
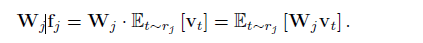
Et~rj代表對rj做average pooling,這是一個線性操作。方程顯示關於分類器和迴歸的線性響應能夠在pooling之前進行。這樣,矩陣乘法只需要做一次,對proposals只需要池化它的response值。提取完網路輸出之後,通過重排矩陣乘法和pooling,對每一個視訊的推理時間由10s降至低於0.5s。(維度問題?升維?)
5.Temporal Region Proposals
Temporal Actionness grouping(TAG)。用actionness classifier估計每一個snippet 的actionness probability。本文的基本思想是找到具有high actionness probability 的連續的region。

6.Experimental Result
ActivityNet 和THUMOS14
6.1Experimental settings
ActivityNet :兩個版本v1.2和v1.3.前者包含9682個視訊,100個分類。後者包含19994個視訊,200個分類。分成三部分:training, validation, testing,比例2:1:1
THUMOS14:1010個validation視訊,1574個testing視訊。20個分類。Training set為UCF101。一般將validation 作為訓練集,因此,訓練集包含220個視訊,20個分類。
Implementation Details: 端到端的訓練。輸入:視訊幀 和 action proposals。Two-stream CNNs用於提取特徵。SGD學習CNN引數,batch_size=128,momentum=0.9,用ImageNet的pre-train models初始化CNN。Learning_rate=0.001 for RGB network,0.005 for opticalflow network。在每一個minibatch中,positive background incomplete proposals的比例為1:1:6。對completeness classifier,只有在一個minibatch中損失值排在前1/6的樣本才會用於計算梯度,這與hard negative mining類似(在negative sets中產生質量更高的samples)。在ActivityNet的兩個版本上,RBG和optical flow 生成two-stream CNN ,分別訓練9.5K和20K次,每4K和1K次迭代後learning_rate縮小0.1。THUMOS14,two-stream分別訓練1K和6K次,每400和2500次迭代後,learning_rate 縮小0.1。
Evaluation Metric。因為資料集來自競賽,每個資料集都有convention of reporting mean average precious(mAP)。本實驗採用 mAP,IoU threshold為{0.5,0.75,0.95},average of mAP
Values with IoU threshold將和其他方法比較。THUMOS14 的IOU threshold 為{0.1,0.2,0.3,0.4,0.5},mAP of 0.5 IoU 用於和其他方法比較。
6.2 Ablation Studio
Temporal Action Proposal :在三個方面比較不同的action proposal scheme:recall,quality,detection performance。
Structured Temporal Pyramid Pooling:
Classifier Design:activity classifiers , completement classifiers.
Location Regression & Multi-Task Learning :
Training :Stage-wise v.s. End-to-End: SSN為end-to-end訓練,分別進行提取特徵,用SVM訓練分類器和迴歸,嶺迴歸,我們稱之為stage-wise training。
6.3 Comparison with the State of Art
與現有的方法比較。
7.總結
本文提出一個通用模型,將structured temporal pyramid 與兩種分類器相結合。