
《推薦系統實踐》第六章 利用社交網路資料
6.1 獲取社交網路資料的途徑
6.1.1 電子郵件
我們可以通過分析使用者的聯絡人列表瞭解使用者的好友資訊,而且可以進一步通過研究兩個使用者之間的郵件往來頻繁程度度量兩個使用者的熟悉程度。
如果我們獲得了使用者的郵箱,也可以通過郵箱字尾得到一定的社交關係資訊。很多社交網站都在使用者註冊時提供了讓使用者從電子郵件聯絡人中匯入好友關係的功能,用以解決社交網路的冷啟動問題。
6.1.2 使用者註冊資訊
有些網站需要使用者在註冊時填寫一些諸如公司、學校等資訊。這也是一種隱性的社交網路資料。
6.1.3 使用者的位置資料
在網頁上最容易拿到的使用者位置資訊就是IP地址。對於手機等移動裝置,我們可以拿到更詳細的GPS資料。位置資訊也是一種反映使用者社交關係的資料。
6.1.4 論壇和討論組
如果兩個使用者同時加入了很多不同的小組,我們可以認為這兩個使用者很可能互相瞭解或者具有相似的興趣。如果兩個使用者在討論組中曾經就某一個帖子共同進行過討論,那就更加說明他們之間的熟悉程度或興趣相似度很高。
6.1.5 即時聊天工具
和電子郵件系統一樣,使用者在即時聊天工具上也會有一個聯絡人列表,而且往往還會給聯絡人進行分組。通過這個列表和分組資訊,我們就可以知道使用者的社交網路關係,而通過統計使用者之間聊天的頻繁程度,可以度量出使用者之間的熟悉程度。
6.1.6 社交網站
個性化推薦系統可以利用社交網站公開的使用者社交網路和行為資料,輔助使用者更好地完成資訊過濾的任務,更好地找到和自己興趣相似的好友,更快地找到自己感興趣的內容。
1. 社會圖譜和興趣圖譜
Facebook和Twitter作為社交網站中的兩個代表,它們其實代表了不同的社交網路結構。在Facebook裡,人們的好友一般都是自己在現實社會中認識的人,而且Facebook中的好友關係是需要雙方確認的。在Twitter裡,人們的好友往往都是現實中自己不認識的,而只是出於對對方言論的興趣而建立好友關係,好友關係也是單向的關注關係。以Facebook為代表的社交網路稱為社交圖譜(social graph),而以Twitter為代表的社交網路稱為興趣圖譜(interest graph)。
但是,每個社會化網站都不是單純的社交圖譜或者興趣圖譜。
6.2 社交網路資料簡介
社交網路定義了使用者之間的聯絡,因此可以用圖定義社交網路。我們用圖G(V,E,w)定義一個社交網路,其中V是頂點集合,每個頂點代表一個使用者,E是邊集合,如果使用者和
有社交網路關係,那麼就有一條邊
連線這兩個使用者,而
定義了邊的權重。業界有兩種著名的社交網路。一種以Facebook為代表,它的朋友關係是需要雙向確認的,因此在這種社交網路上可以用無向邊連線有社交網路關係的使用者。另一種以Twitter為代表,它的朋友關係是單向的,因此可以用有向邊代表這種社交網路上的使用者關係。
此外,對圖G中的使用者頂點u,定義out(u)為頂點u指向的頂點集合(如果套用微博中的術語,out(u)就是使用者u關注的使用者集合),定義in(u)為指向頂點u的頂點集合(也就是關注使用者u的使用者集合)。那麼,在Facebook這種無向社交網路中顯然有out(u)=in(u)。
一般來說,有3種不同的社交網路資料。
雙向確認的社交網路資料,這種社交網路一般可以通過無向圖表示。
單向關注的社交網路資料,這種社交網路中的使用者關係是單向的,可以通過有向圖表示。
基於社群的社交網路資料,這種社交網路資料,使用者之間並沒有明確的關係,但是這種資料包含了使用者屬於不同社群的資料。
社交網路資料中的長尾分佈
社交網路中使用者的入度(in degree)和出度(out degree)的分佈也是滿足長尾分佈的。
使用者的入度反映了使用者的社會影響力。使用者的入度近似長尾分佈,這說明在一個社交網路中影響力大的使用者總是佔少數。
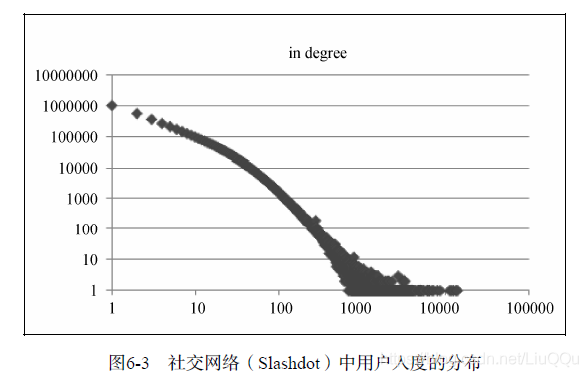
出度代表了一個使用者關注的使用者數,該圖說明在一個社交網路中,關注很多人的使用者佔少數,而絕大多數使用者只關注很少的人。

6.3 基於社交網路的推薦
很多網站都利用Facebook的社交網路資料給使用者提供社會化推薦。
社會化推薦之所以受到很多網站的重視,是緣於如下優點。
(1)好友推薦可以增加推薦的信任度
(2)社交網路可以解決冷啟動問題
社會化推薦也有一些缺點,其中最主要的就是很多時候並不一定能提高推薦演算法的離線精度(準確率和召回率)。特別是在基於社交圖譜資料的推薦系統中,因為使用者的好友關係不是基於共同興趣產生的,所以使用者好友的興趣往往和使用者的興趣並不一致。
6.3.1 基於鄰域的社會化推薦演算法
如果給定一個社交網路和一份使用者行為資料集。其中社交網路定義了使用者之間的好友關係,而使用者行為資料集定義了不同使用者的歷史行為和興趣資料。那麼我們想到的最簡單演算法是給使用者推薦好友喜歡的物品集合。即使用者u對物品i的興趣pui可以通過如下公式計算。
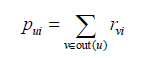 ,其中out(u)是使用者u的好友集合,如果使用者v喜歡物品i,則
,其中out(u)是使用者u的好友集合,如果使用者v喜歡物品i,則=1,否則
=0。
不過,即使都是使用者u的好友,不同的好友和使用者u的熟悉程度和興趣相似度也是不同的。因此,我們應該在推薦演算法中考慮好友和使用者的熟悉程度以及興趣相似度:
![]() ,這裡,
,這裡, 由兩部分相似度構成,一部分是使用者u和使用者v的熟悉程度,另一部分是使用者u和使用者v的興趣相似度。
使用者u和使用者v的熟悉程度(familiarity)描述了使用者u和使用者v在現實社會中的熟悉程度。熟悉度可以用使用者之間的共同好友比例來度量。

在度量使用者相似度時還需要考慮興趣相似度(similarity),而興趣相似度可以通過和UserCF類似的方法度量,即如果兩個使用者喜歡的物品集合重合度很高,兩個使用者的興趣相似度很高。
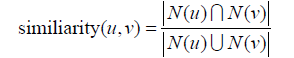 ,其中N(u)是使用者u喜歡的物品集合。
,其中N(u)是使用者u喜歡的物品集合。
def Recommend(uid, familiarity, similarity, train):
rank = dict()
interacted_items = train[uid]
for fid,fw in familiarity[uid]:
for item,pw in train[fid]:
# if user has already know the item
# do not recommend it
if item in interacted_items:
continue
addToDict(rank, item, fw * pw)
for vid,sw in similarity[uid]:
for item,pw in train[vid]:
if item in interacted_items:
continue
addToDict(rank, item, sw * pw)
return rank6.3.2 基於圖的社會化推薦演算法
使用者的社交網路可以表示為社交網路圖,使用者對物品的行為可以表示為使用者物品二分圖,而這兩種圖可以結合成一個圖。圖上
有使用者頂點(圓圈)和物品頂點(方塊)兩種頂點。如果使用者u對物品i產生過行為,那麼兩個節點之間就有邊相連。比如該圖中使用者A對物品a、e產生過行為。如果使用者u和使用者v是好友,那麼也會有一條邊連線這兩個使用者,比如該圖中使用者A就和使用者B、D是好友。

在定義完圖中的頂點和邊後,需要定義邊的權重。其中使用者和使用者之間邊的權重可以定義為使用者之間相似度的倍(包括熟悉程度和興趣相似度),而使用者和物品之間的權重可以定義為使用者對物品喜歡程度的
倍。
和
需要根據應用的需求確定。如果我們希望使用者好友的行為對推薦結果產生比較大的影響,那麼就可以選擇比較大的
。相反,如果我們希望使用者的歷史行為對推薦結果產生比較大的影響,就可以選擇比較大的
。
在定義完圖中的頂點、邊和邊的權重後,我們就可以利用前面幾章提到的PersonalRank圖排序演算法給每個使用者生成推薦結果。
在社交網路中,除了常見的、使用者和使用者之間直接的社交網路關係(friendship),還有一種關係,即兩個使用者屬於同一個社群(membership)。如果要在前面提到的基於鄰域的社會化推薦演算法中考慮membership的社交關係,可以利用兩個使用者加入的社群重合度計算使用者相似度,然後給使用者推薦和他相似的使用者喜歡的物品。但是,如果利用圖模型,我們就很容易同時對friendship和membership建模。如圖6-8所示,可以加入一種節點表示社群(最左邊一列的節點),而如果使用者屬於某一社群,圖中就有一條邊聯絡使用者對應的節點和社群對應的節點。在建立完圖模型後,我們就可以通過前面提到的基於圖的推薦演算法(比PersonalRank)給使用者推薦物品。

6.3.3 實際系統中的社會化推薦演算法
6.3.1節提出的基於鄰域的社會化推薦演算法看起來非常簡單,但在實際系統中卻是很難操作的,這主要是因為該演算法需要拿到使用者所有好友的歷史行為資料,而這一操作在實際系統中是比較重的操作。
我們可以從幾個方面改進基於鄰域的社會化推薦演算法,讓它能夠具有比較快的響應時間。改進的方向有兩種,一種是可以做兩處截斷。第一處截斷就是在拿使用者好友集合時並不拿出使用者所有的好友,而是隻拿出和使用者相似度最高的N個好友。這裡N可以取一個比較小的數。從而給該使用者做推薦時可以只查詢N次使用者歷史行為介面。此外,在查詢每個使用者的歷史行為時,可以只返回使用者最近1個月的行為,這樣就可以在使用者行為快取中快取更多使用者的歷史行為資料,從而加快查詢使用者歷史行為介面的速度。此外,還可以犧牲一定的實時性,降低快取中使用者行為列表過期的頻率。
而第二種解決方案需要重新設計資料庫。
首先,為每個使用者維護一個訊息佇列,用於儲存他的推薦列表;
當一個使用者喜歡一個物品時,就將(物品ID、使用者ID和時間)這條記錄寫入關注該使用者的推薦列表訊息佇列中;
當用戶訪問推薦系統時,讀出他的推薦列表訊息佇列,對於這個訊息佇列中的每個物品,重新計算該物品的權重。計算權重時需要考慮物品在佇列中出現的次數,物品對應的使用者和當前使用者的熟悉程度、物品的時間戳。同時,計算出每個物品被哪些好友喜歡過,用這些好友作為物品的推薦解釋。
6.3.4 社會化推薦系統和協同過濾推薦系統
關於社會化推薦系統的離線評測可以參考Georg Groh和Christian Ehmig的工作成果(參見“Recommendations in Taste Related Domains: Collaborative Filtering vs. Social Filtering”,http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.165.3679&rep=rep1&type=pdf)。不過社會化推薦系統的效果往往很難通過離線實驗評測,因為社會化推薦的優勢不在於增加預測準確度,而是在於通過使用者的好友增加使用者對推薦結果的信任度,從而讓使用者單擊那些很冷門的推薦結果。此外,很多社交網站(特別是基於社交圖譜的社交網站)中具有好友關係的使用者並不一定有相似的興趣。因此,利用好友關係有時並不能增加離線評測的準確率和召回率。因此,很多研究人員利用使用者調查和線上實驗的方式評測社會化推薦系統。
對社會化推薦系統進行使用者調查的代表性工作成果是Rashmi Sinha和Kirsten Swearingen對比社會化推薦系統和協同過濾推薦系統的論文(參見“Comparing Recommendations Made by Online Systems and Friends”,https://pdfs.semanticscholar.org/a239/9a7a0b39ade27f9edf605075f3fa3877e2c9.pdf)。
作者通過分析使用者實驗的過程和最終回答的調查問卷證明,社會化推薦系統推薦結果的使用者滿意度明顯高於主要基於協同過濾演算法的幾個真實推薦系統。
6.3.5 資訊流推薦
資訊流推薦是社會化推薦領域的新興話題,它主要針對Twitter和Facebook這兩種社交網站。資訊流的個性化推薦要解決的問題就是如何進一步幫助使用者從資訊牆上挑選有用的資訊。
目前最流行的資訊流推薦演算法是Facebook的EdgeRank,該演算法綜合考慮了資訊流中每個會話的時間、長度與使用者興趣的相似度。EdgeRank的主要思想參見“EdgeRank: The Secret Sauce That Makes Facebook’s News Feed Tick”,地址為http://techcrunch.com/2010/04/22/facebook-edgerank/。
Facebook將其他使用者對當前使用者資訊流中的會話產生過行為的行為稱為edge,而一條會話的權重定義為:

其中:
指產生行為的使用者和當前使用者的相似度,這裡的相似度主要是在社交網路圖中的熟悉度;
指行為的權重,這裡的行為包括建立、評論、like(喜歡)、打標籤等,不同的行為有不同的權重。
指時間衰減引數,越早的行為對權重的影響越低。
如果一個會話被你熟悉的好友最近產生過重要的行為,它就會有比較高的權重。
不過,EdgeRank演算法的個性化因素僅僅是好友的熟悉度,它並沒有考慮帖子內容和使用者興趣的相似度。所以EdgeRank僅僅考慮了“我”周圍使用者的社會化興趣,而沒有重視“我”個人的個性化興趣。為此,GroupLens的研究人員Jilin Chen深入研究了資訊流推薦中社會興趣和個性化興趣之間的關係。(參見“Speak Little and Well: Recommending Conversations in Online Social Streams”,https://dl.acm.org/citation.cfm?id=1978974)他們的排名演算法考慮瞭如下因素。
會話的長度:越長的會話包括越多的資訊。
話題相關性:度量了會話中主要話題和使用者興趣之間的相關性。這裡Jilin Chen用了簡單的TF-IDF建立使用者歷史興趣的關鍵詞向量和當前會話的關鍵詞向量,然後用這兩個向量的相似度度量話題相關性。
使用者熟悉程度:主要度量了會話中涉及的使用者(比如會話的建立者、討論者等)和當前使用者的熟悉程度。計算熟悉度的主要思想是考慮使用者之間的共同好友數等。
他們設計了使用者調查,讓使用者對如下5種演算法的推薦結果給出1~5分的評分:
Random 給使用者隨機推薦會話。
Length 給使用者推薦比較長的會話。
Topic 給使用者推薦和他興趣相關的會話。
Tie 給使用者推薦和他熟悉的好友參與的會話。
Topic+Tie 綜合考慮會話和使用者的興趣相關度以及使用者好友參與會話的程度。
結果發現:
對於所有使用者不同演算法的平均得分是:Topic+Tie > Tie > Topic > Length > Random
而對於主要目的是尋找資訊的使用者,不同演算法的得分是:Topic+Tie ≥ Topic > Length > Tie > Random
對於主要目的是交友的使用者,不同演算法的得分是:Topic+Tie > Tie > Topic > Length > Random
實驗結果說明,綜合考慮使用者的社會興趣和個人興趣對於提高使用者滿意度是有幫助的。因此,當我們在一個社交網站中設計推薦系統時,可以綜合考慮這兩個因素,找到最合適的融合引數來融合使用者的社會興趣和個人興趣,從而給使用者提供最令他們滿意的推薦結果。
6.4 給使用者推薦好友
好友推薦系統的目的是根據使用者現有的好友、使用者的行為記錄給使用者推薦新的好友,從而增加整個社交網路的稠密程度和社交網站使用者的活躍度。
好友推薦演算法在社交網路上被稱為連結預測(link prediction)。關於連結預測演算法研究的代表文章是Jon Kleinberg的“Link Prediction in Social Network”(https://www.cs.cornell.edu/home/kleinber/link-pred.pdf)。
6.4.1 基於內容的匹配
我們可以給使用者推薦和他們有相似內容屬性的使用者作為好友。下面給出了常用的內容屬性。
使用者人口統計學屬性,包括年齡、性別、職業、畢業學校和工作單位等。
使用者的興趣,包括使用者喜歡的物品和釋出過的言論等。
使用者的位置資訊,包括使用者的住址、IP地址和郵編等。
利用內容資訊計算使用者的相似度和我們前面討論的利用內容資訊計算物品的相似度類似。
6.4.2 基於共同興趣的好友推薦
如果使用者喜歡相同的物品,則說明他們具有相似的興趣。
此外,也可以根據使用者在社交網路中的發言提取使用者的興趣標籤,來計算使用者的興趣相似度。
6.4.3 基於社交網路圖的好友推薦
最簡單的好友推薦演算法是給使用者推薦好友的好友。
基於好友的好友推薦演算法可以用來給使用者推薦他們在現實社會中互相熟悉,而在當前社交網路中沒有聯絡的其他使用者。
對於使用者u和使用者v,我們可以用共同好友比例計算他們的相似度:
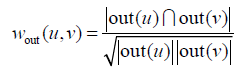
公式中out(u)是在社交網路圖中使用者u指向的其他好友的集合。我們也可以定義in(u)是在社交網路圖中指向使用者u的使用者的集合。在無向社交網路圖中,out(u)和in(u)是相同的集合。但在微博這種有向社交網路中,這兩個集合就不同了,因此也可以通過in(u)定義另一種相似度:

越大表示使用者u和v關注的使用者集合重合度越大,而
越大表示關注使用者u和關注使用者v的使用者的集合重合度越大。
同時,我們還可以定義第三種有向的相似度:
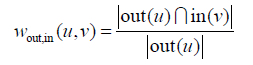
這個相似度的含義是使用者u關注的使用者中,有多大比例也關注了使用者v。但是,這個相似度有一個缺點,就是在該相似度的定義下所有人都和名人有很大的相似度。這是因為這個相似度在分母的部分沒有考慮|in(v)|的大小。因此,我們可以用如下公式改進上面的相似度:

離線實驗
斯坦福大學的大規模網路資料集(http://snap.stanford.edu/data/),該資料集包含很多連結結構資料集,包括社交網路資料集、網際網路超級連結資料集、道路交通網路、使用者行為網路、論文引用網路等。這裡,我們使用該集合中提供的Slashdot社交網路資料集。該資料集是一個有向圖,包含82 168個頂點和948 464條邊。
為了測試不同好友推薦演算法的效能,本節將資料集按照9:1分成訓練集和測試集。然後,給定使用者u,我們會利用訓練集中的社交網路給使用者生成長度為10的好友推薦列表R(u),其中R(u)中的使用者不包含使用者u在訓練集中的好友。

不同資料集上不同演算法的效能並不相同。所以,在實際系統中我們需要在自己的資料集上對比不同的演算法,找到最適合自己資料集的好友推薦演算法。
6.4.4 基於使用者調查的好友推薦演算法對比
通過使用者調查對比了不同演算法的使用者滿意度(參見“‘Make New Friends, but Keep the Old’ - Recommending People on Social Networking Site”),其中演算法如下。
InterestBased 給使用者推薦和他興趣相似的其他使用者作為好友。
SocialBased 基於社交網路給使用者推薦他好友的好友作為好友。
Interest+Social 將InterestBased演算法推薦的好友和SocialBased演算法推薦的好友按照一定權重融合。
SONA SONA是IBM內部的推薦演算法,該演算法利用大量使用者資訊建立了IBM員工之間的社交網路。這些資訊包括所在的部門、共同發表的文章、共同寫的Wiki、IBM的內部社交網路資訊、共同合作的專利等。
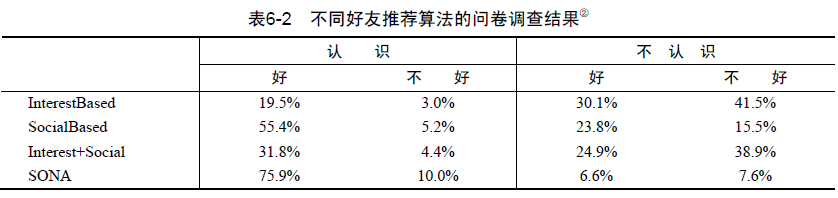
從結果可以發現,對推薦結果的新穎性不同演算法的排名如下:InterestBased > Interest+Social > SocialBased > SONA
其次,結果表明如果使用者認識推薦結果中的人,那麼絕大部分使用者都會覺得這是一個好的推薦結果,而如果使用者不認識推薦結果中的人,絕大多數人都覺得推薦結果不好。
從使用者認為推薦結果是否好的比例看,不同演算法的排名如下:SONA > SocialBased > Interest+Social > InterestBased
6.5 擴充套件閱讀
關於社交網路最讓人耳熟能詳的結論就是六度原理。六度原理講的是社會中任意兩個人都可以通過不超過6個人的路徑相互認識,如果轉化為圖的術語,就是社交網路圖的直徑為6。六度原理在均勻隨機圖上已經得到了完美證明,對此感興趣的讀者可以參考《Random Graph》一書。很多對社交網路的研究都是基於隨機圖理論的,因此深入研究社交網路必須掌握隨機圖理論的相關知識。
社交網路研究中有兩個最著名的問題。第一個是如何度量人的重要性,也就是社交網路頂點的中心度(centrality),第二個問題是如何度量社交網路中人和人之間的關係,也就是連結預測。對這兩個問題感興趣的讀者可以參考社交網路分析方面的書,比如《Social Network Analysis: Methods and Applications》和《Social Network Analysis: A Handbook》。