
face detection[FaceBoxes]
該文來自《FaceBoxes: A CPU Real-time Face Detector with High Accuracy》。該文時間線是2018年1月
雖然人臉檢測上隨著深度學習的普及,引來了巨大的進步,可是如何在CPU環境下實時的保持高準確度是一個難題,因為高準確度的網路往往伴隨著大量的計算。本文提出的模型就是如何在CPU環境下依然保持高準確度。為此Shifeng Zhang提出了FaceBoxes,一個輕量級且強大的網路結構,其中包含:
- 快速消解卷積層(rapidly digested convolutional layers,RDCL);
- 多尺度卷積層(Multiple Scale Convolutional Layers,MSCL)。
其中RDCL設計用來確保FaceBoxes能在CPU上獲得實時的能力;而MSCL為了豐富不同網路層上的感受野和離散的錨點以幫助處理不同尺度的人臉。同時,提出了一個新的錨增密策略來讓不同型別的錨在圖片上都有相同的密度,這明顯的提升了在小人臉上的召回度。提出的檢測器在單CPU核上可以跑到20FPS,在GPU上可以跑到125FPS。並且FaceBoxes的速度對於人臉的數量具有不變性。
0 引言
人臉檢測中的挑戰主要來自2個方向:
- 在嘈雜背景下人臉具有較大的視覺變化,需要處理複雜的人臉二分類問題;
- 搜尋空間很大:基於可控時間內,對人臉可能存在的位置以及人臉尺度進行搜尋。
如上述兩個問題,所以如何保證實時性,然後網路結構又不復雜,且高準確度一直是個難點。而之前提出的級聯CNN雖然進一步加速了整個檢測過程,不過其本身還是有不少問題:
- 檢測速度是相對圖片中人臉的個數的,如果圖片中人臉數量很多,那麼整體速度就會下降了;
- 該方法在訓練的時候是幾個網路單獨訓練的,從而讓訓練變得相對複雜,而且最後輸出的哦模型不是最優的;
- 對於VGA解析度的圖片,在CPU上執行的效率是14FPS,還是趕不上實時的速度。
受到Faster RCNN中的RPN和SSD的多尺度機制的啟發,作者提出了一個能在CPU上跑出實時的模型,叫FaceBoxes。其只包含一個全卷積網路,且能end to end的訓練
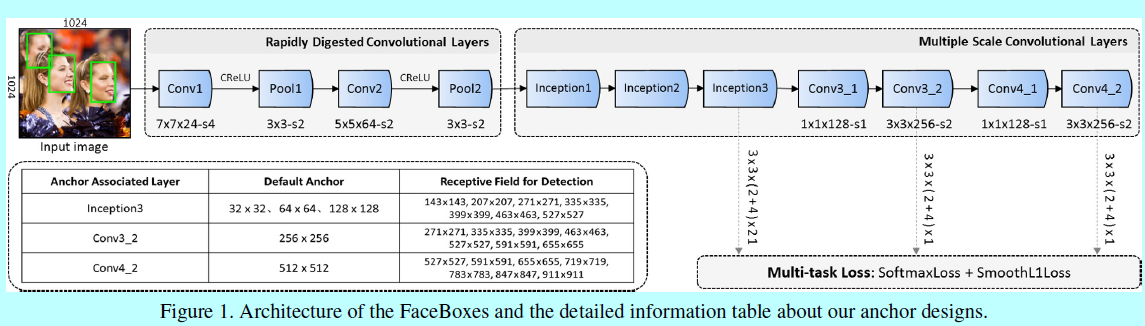

如圖1,其中包含快速消融卷積層(RDCL)和多尺度卷積層(MSCL)。所以本文的主要貢獻:
- 設計了RDCL用來確保CPU上的實時性;
- 引入了MSCL用來豐富不同網路層上的感受野和離散錨從而處理多尺度的人臉;
- 提出了一個新的錨增密策略來提升小臉的召回率;
- 讓AFW, PASCAL人臉,FDDB資料集上的最好結果又提升了。
1 結構
1.1 快速消解卷積層 RDCL
RDCL設計之初就是為了快速將影象的尺度將下去,並相對其他網路減少通道數,從而確保FaceBoxes能夠實時:
- 快速降低輸入的空間尺度:通過在卷積層和池化層引入一系列大strides,如圖1所示,Conv1,Pool1,Conv2和Pool2的stride分別是4,2,2,2.總的RDCL是32,意味著輸入圖片的空間尺度被減小了32倍;
- 選擇合適的核尺度:網路中最開始的層上核尺度應該是小的,從而才能加速。同時它也應該足夠大,以減輕空間尺寸減小帶來的資訊損失。如圖1,為了儘可能保持高效,在Conv1,Conv2,Conv3上分別選擇7x7,5x5,3x3的卷積核;
- 減少輸出的通道數:這裡利用C.ReLU啟用函式(如圖2(a)),去減少輸出的通道數。C.ReLU是來自CNN的觀察,其中較低層中的濾波器會形成對(即濾波器具有相反相位)。 根據這一觀察,C.ReLU可以通過在ReLU之前簡單地concatenating否定的輸出來使輸出通道的數量加倍。 使用C.ReLU可顯著提高速度,而且精度基本沒下降。
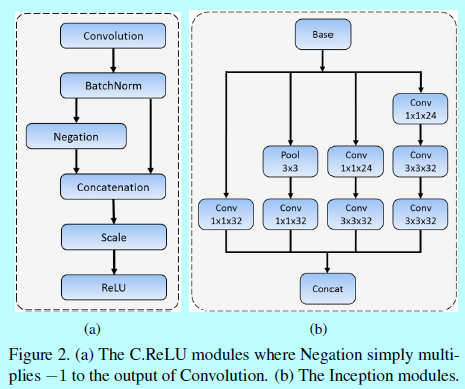
1.2 多尺度卷積層 MSCL
RPN原來是基於多類別目標檢測提出的,而人臉檢測就是個單類別。而作為獨立的人臉檢測器,RPN並不能提供很高的效能。作者認為這樣的現象主要來自兩個方面:
- RPN中的錨只與最後的卷積層相關聯,而一層卷積層含有的特徵和解析度對於抓取不同尺度的人臉來說太弱了;
- 一個關聯錨的層(RPN層)需要負責在一個尺度範圍內檢測人臉,但是一個感受野(此時是基於一個劃窗位置上,這裡參考faster rcnn的RPN部分)並不能匹配不同尺度的人臉。
為了解決上述2個問題,MSCL主要遵循下面2個維度:
- 基於網路深度的多尺度設計:如圖1,MSCL包含幾層,這些層在尺寸上是逐步減小的,因此形成一個多尺度feature map。如SSD,這裡預設的錨是關聯著多尺度feature map(即,Inception3,Conv3_2,Conv4_2)。這些層就如基於網路深度這個維度上進行的多尺度設計,基於不同解析度的多層去分散錨能夠處理不同尺度的人臉;
- 基於網路寬度的多尺度設計:為了學習不同尺度人臉的模式,關聯錨的層的輸出特徵應該對應不同尺度的感受野,這可以容易的通過Inception模組去實現。Inception模組包含不同核的多個卷積分支。這些分支作為網路寬度上的多尺度設計,如圖1中,MSCL前三個層都是基於Inception實現的。圖2(b)詳細介紹了Inception模組,用於捕捉不同尺度的人臉。
1.3 錨增密策略
如圖1,這裡引入的是1:1的預設錨(即平方錨),因為人臉大多都是正方形的。Inception3層中錨的尺度分別是32,64,128;而Conv3_2和Conv4_2層上錨的尺度分別是256和512個畫素。
影象上錨點的平鋪間隔等於相應關聯錨的層的stride大小。例如,Conv3_2的stride是64個畫素,他對應的錨是256x256,表示對於輸入圖片上每64個畫素點就有256x256的一個錨。這裡定義錨的平鋪密度(即\(A_{density}\)):
\[A_{density}=A_{scale}/A_{interval}\]
這裡\(A_{scale}\)是錨的尺度,\(A_{interval}\)是錨的平鋪間隔。這裡預設錨的平鋪間隔是32,32,32,64,128。按照上面的式子,對應的密度是1,2,4,4,4。很明顯的,這裡錨的不同尺度之間存在平鋪密度不平衡的問題。相對與大錨(如128x128,256x256,512x512),小錨(如32x32,64x64)太稀疏了,這導致小臉的低召回率。
為了消除這種不平衡,提出了一個新的錨增密策略。特別的,為了增密一個型別的錨n次,我們在一個感受野的中心周圍均勻平鋪\(A_{number}=n^2\)個錨,而不是隻平鋪一個錨。如圖3
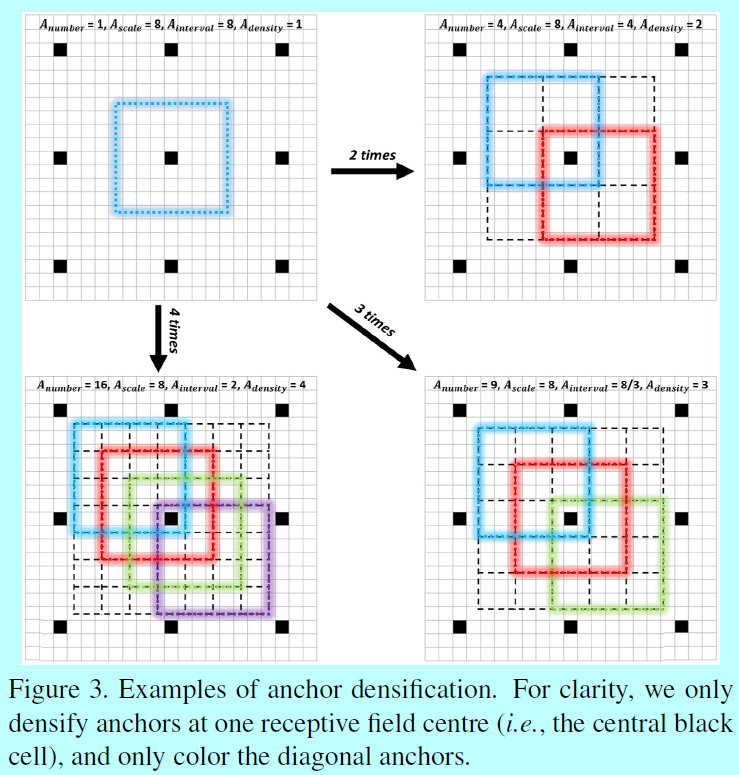
為了提升小錨的平鋪密度,作者的策略是使用32x32的錨4次,64x64的錨2次,這保證了不同尺度的錨有相同的密度(即 4),所以不同尺度的人臉就能匹配差不多相同數量的錨。
1.4 訓練
這裡介紹了訓練資料集,資料增強,匹配策略,loss函式,硬負樣本挖掘,和其他技術細節。
訓練資料集:WIDER FACE
資料增強:每個圖片都經歷下面的策略:
- 顏色失真:如《Some improvements on deep convolutional neural network based image classification》中的照片失真方法;
- 隨機裁剪:從原始圖片中隨機裁剪5個圖片:一個是最大的平方塊,其他的是基於最短邊的[0.3,1]的尺寸。然後從這5張中隨機挑一張給後續處理流程;
- 尺度變化:將裁剪後的圖片resize成1024x1024;
- 水平翻轉:將resize之後的圖片以0.5的概率水平翻轉;
- 人臉框過濾:保留那些人臉框的中心還在的圖片;將那些人臉框的高或者框小於20的圖片刪掉。
匹配策略:在訓練中,需要檢測哪個錨對應哪個人臉框。首先匹配最高IOU值的錨,然後匹配那些IOU高於0.35的錨;
loss 函式:如faster rcnn中的RPN的loss,這裡基於二值softmax做人臉分類,用L1平滑loss做迴歸。
硬負樣本挖掘:在錨匹配之後,大部分都是負的,這時候會造成正負樣本失衡,所以基於loss進行排序,挑選最高的那些,保證負正樣本比例為3:1
其他策略:採用xavier方法初始化,用帶有0.9動量的SGD做迭代,權重衰減的係數為0.0005,batchsize為32.最大的迭代次數為120k,採用基於錢80k的迭代,採用0.001作為學習率;基於後面的20k,20k次,分別採用0.0001和0.00001作為學習率。並基於caffe實現。
.