
face detection[S^3FD]
本文來自《\(S^3\)FD: Single Shot Scale-invariant Face Detector》,時間線為2017年11月.
0 引言
基於錨的目標檢測方法,是通過分類和迴歸一系列預先設定的錨來檢測目標的。這裡預先設定的錨通常都是一個個基於不同尺度和長寬比的框。這些錨通常都是關聯一層(faster rcnn)或者多層(SSD)卷積層。通過不同卷積層的空間尺度和stride大小來決定錨的位置和間隔。關聯錨的網路層通常是為了用來分類和對齊這些錨。相比於其他方法,基於錨的檢測方法在複雜場景下更魯棒,而且他們針對不同的物件個數也具有速度不變性(即不會因為圖片中目標個數增加而導致整體計算量增加)。然而,正如《Speed/accuracy trade-offs for modern convolutional object detectors》所述,基於錨的檢測器會隨著目標尺寸的變小,其效果會急劇變差
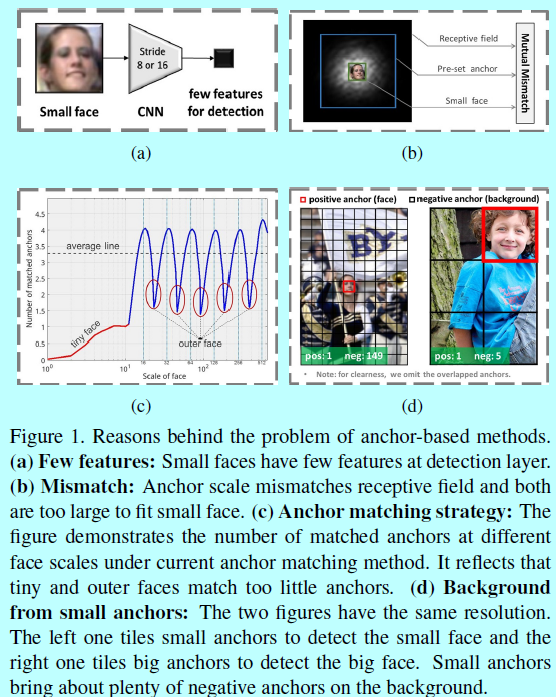
為了得到一個基於錨的尺度不變人臉檢測器,作者綜合分析了背後的原因:
- 有偏框架:基於錨的檢測框架通常會丟失小型和中型的人臉。首先,最低的關聯錨的層的stride太大了(如SSD中8個畫素,Faster rcnn中16個畫素 ),因此小型人臉和中型人臉在這些層上就被極度壓縮,從而幾乎沒有特徵以供檢測,如圖1(a);其次,小型人臉,錨的尺度,感受野互相不匹配:錨的尺度首先和感受野不匹配,然後他們相對小型人臉而言都太大了,如圖1(b)。為了處理這樣的問題,作者提出了一個尺度等同的人臉檢測框架。作者在一個範圍內的網路層上平鋪錨(如SSD),其中stride從4個畫素到128個畫素,從而保證了人臉的各種尺度都有足夠的特徵以供檢測。同時,基於不同層上的感受野大小,設計錨本身的尺度從16個畫素到512個畫素,並提出一個等比例區間原則,從而確保不同層上的錨能夠匹配他們對應的感受野,而且不同尺度的錨點均勻分佈在影象上。
- 錨匹配策略:在基於錨的檢測框架中,錨的尺度都是離散的(即16,32,64,128,256,512),但是人臉的尺度確是連續的。因而,那些人臉的尺度就會嚴重偏離從而沒法很好的匹配錨,比如非常小的,和非常大的,如圖1(c),從而導致召回率很低。為了提升這些被忽略的人臉的尺度,作者提出了一個基於2階段的尺度補償錨匹配策略。第一個階段就是採用當前的錨匹配方法,不過調整到一個更合理的閾值;第二個階段就是通過尺度補償確保每個尺度的人臉都有足夠的錨去匹配。
- 小錨的背景:為了很好的檢測小型人臉,需要許多小的錨密集的平鋪在圖片上,如圖1(d),這些小的錨導致背景上負錨的數量急劇上升,從而帶來許多假陽性人臉。例如,在作者的尺度等同框架中,超過75%的負錨都來自最低的conv3_3層,而這一層是用來檢測小型人臉的。本文基於最低檢測網路層提出了一個max-out背景標籤,從而減少小型人臉帶來的假陽性比率。
本文的貢獻:
- 提出了一個尺度等同人臉檢測框架:基於一個較廣的範圍內去建立錨和卷積層關聯,並且加之一系列合理的錨尺度,一起去處理不同尺度的人臉;
- 提出一個尺度補償錨匹配策略去提升小型人臉的召回率;
- 引入一個max-out背景標籤方法,去減少小型人臉的假陽性比例;
- 在AFW,PASCAL face,FDDB,WIDER FACE上達到了實時的效果。
1 結構
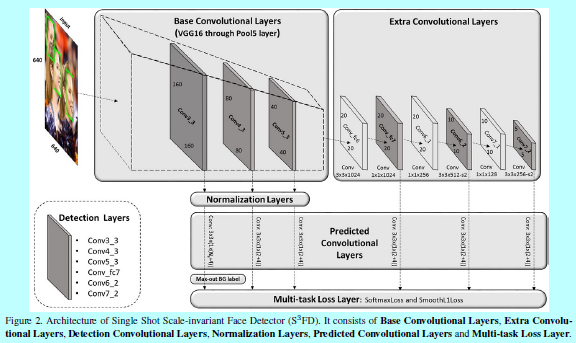


如圖所示,可以看出,該模型和《FaceBoxes》模型還是挺像的,畢竟來自同一個人之手。
1.1 尺度等同結構
這裡的尺度等同架構也是基於錨的檢測框架,如RPN和SSD。而這些網路的一個缺點就是隨著目標尺度的變小,其檢測效能急速下降。為了提升人臉尺度的魯棒性,作者提出了一個有著較廣範圍的錨關聯層的網路結構,這裡stride從4個畫素逐步增長到128個畫素。因此,這個架構確保不同人臉的尺度在對應的錨關聯層上有合適的特徵用來做檢測。在決定錨的位置後,還設計了基於感受野和等比例間隔的錨尺度,其從16個畫素逐步過渡到512個畫素。前面的考慮是為了保證每個尺度的錨能夠匹配對應的感受野;後面的考慮是為了讓不同尺度的錨在圖片上有相同的平鋪密度。
構建的結構:如上圖的圖2所示
- 基礎卷積層:保留VGG16的conv1_1到pool5,移除其他後續的層;
- 額外卷積層:將VGG16的fc6和fc7通過子取樣的方式構建卷積層,然後在後面增加額外的卷積層,這些層可以逐漸的降低feature map的尺度,並形成多尺度feature map;
- 檢測卷積層:這裡選擇conv3_3,conv4_3,conv5_3,conv_fc7,conv6_2,conv7_2作為檢測層,它們都關聯不同尺度的錨以供檢測;
- 歸一化層:相比於其他檢測層,conv3_3,conv4_3,conv5_3有不同的特徵尺度,這裡使用L2歸一化的方式去將他們的範數縮放到10.8.5,然後在BP中學習該尺度;
- 預測的卷積層:每個檢測層後面都跟著一個\(p\times 3 \times 3 \times q\)的卷積層,這裡p 和q 是對應的輸入和輸出的通道數,3x3是核尺度。對於每個錨,這裡都預測其4個座標的偏移量和對應的\(N_s\)個類別的分類得分,對於conv3_3檢測層,\(N_s=N_m+1\),(\(N_m\)就是後面介紹的max-out背景標籤),而其他檢測層\(N_s=2\)。
- 多工loss層:使用softmax loss做分類,使用平滑L1 loss做迴歸。
基於錨設計的尺度:
上述介紹的6個檢測層都關聯一個特定尺度的錨(如下表)
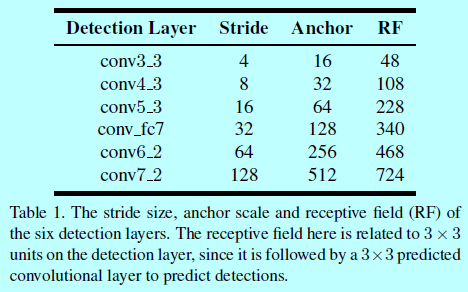
因為人臉基本都是方形的,所以這裡的錨長寬比都是1:1(平方錨)。如表1中第2和第4列,每個檢測層上的感受野和stride都是固定的,這裡有2點設計原則:
- 有效的感受野:如《Understanding the effective receptive field in deep convolutional neural networks》指出的,CNN中一個單一有2種類型的感受野:一種是理論上的感受野,其表示輸入區域可以理論上影響該單元的值。然而不是每個理論感受野上的畫素都能夠在最終輸出上有相同的貢獻度。通常而言,中心區域的畫素會比外圍畫素有更多的影響,如圖3(a)

換句話說,只有部分割槽域會影響到輸出值;另一種就叫做有效感受野,根據該理論,錨應該明顯的小於理論感受野,從而才能匹配有效感受野(圖3b);- 等比例間隔原則:一個檢測層的stride決定輸入影象上錨的間隔。例如conv3_3的stride是4個畫素,那麼他的錨應該是16x16,表示一個16x16的錨在輸入影象上每4個畫素會平鋪一個。如表1中第2列和第3列,錨的尺度應該是剛好4倍於它的間隔。這裡稱這種叫等比例間隔原則(圖3c),從而保證不同尺度的錨在影象上有相同的密度,所以每個尺度的人臉都大致有相同數量的錨。
1.2 尺度補償和錨匹配策略
在訓練中,需要決定哪個錨對應哪個人臉邊界框。當前的錨匹配策略首先匹配與人臉IOU最高的那個錨,然後匹配那些與人臉高於閾值(通常是0.5)的錨。然而,錨尺度是離散的,而人臉尺度是連續的,從而錨沒有足夠的數量去匹配所有的尺度的人臉,就導致降低了人臉的召回率。如圖1c,作者統計了下不同尺度的人臉能匹配的錨的平均數量。發現兩個結論:
- 匹配的錨的平均數量是3,這導致沒法獲得較高召回率;
- 匹配的錨,高度依賴錨的尺度。
那些尺度偏離錨尺度的人臉都容易被忽略。為了解決這個問題,作者提出了一個尺度補償錨匹配策略,其中包含2個階段:
- 階段1:首先遵循當前的錨匹配方法,不過將閾值從0.5降低到0.35,為了增加匹配的錨的數量。
- 階段2:經過階段1之後,仍有一些人臉還不夠錨,比如,如圖4a中那些灰點標出的尺度極小和極大的人臉(tiny,outer)。
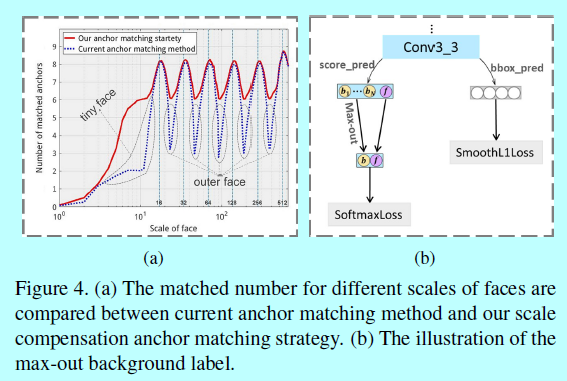
對於這些人臉,首先抓取那些與該人臉的IOU超過0.1的錨,然後將它們進行排序,選擇前N個匹配的錨(這裡的N就是階段1的平均錨個數)。
如圖4a,這裡的錨匹配策略極大的增加了關於極小和極大的人臉匹配的錨,這明顯增加了這些人臉的召回率。
1.3 max-out 背景標籤
基於錨的人臉檢測模型可以被認為是一個二分類問題。而作者發現這是一個不平衡的二值分類問題:按照統計的結果,超過99.8%的預設定錨都屬於負錨(即都是背景),只有一小部分是正錨(即人臉)。這極端的不平衡主要是受到檢測小型人臉的問題引起的。特別的,為了檢測小臉,需要早影象上平鋪一堆錨,這導致負錨的數量極端增多。例如如表2,
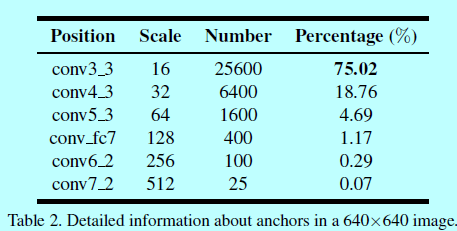
一個640x640的圖片一共有34,125個錨,而差不多75%來自conv3_3檢測層,該檢測層又關聯最小的檢測錨(16x16)。這些最小的錨貢獻了最多的假陽性人臉。所以通過平鋪小型錨來提升小人臉檢測結果也不可避免的增大了訊息人臉的假陽性比例。
為了解決這個問題,作者提出了在最低層上採用一個更好的分類策略來處理來自小型錨的複雜背景。作者在conv3_3檢測層上使用max-out 背景標籤。對於每個最小的錨,需要預測 \(N_m\)的背景標籤的得分,然後選擇最高分作為最終分手,如圖4b。max-out操作將一些區域性最優解整合到 \(S^3FD\)模型中,從而減少最小人臉的假陽性比例。
1.4 訓練 & loss函式 & 硬負樣本挖掘
這部分,介紹下訓練資料集,資料增強,loss函式,硬負樣本挖掘和其他細節。
訓練資料集:是WIDER FACE資料集;
資料增強:
- 顏色失真:採用一些影象測度的失真方法, 類似《Some improvements on deep convolutional neural network based image classification》;
- 隨機裁剪:因為有太多小型人臉,所以通過放大操作來生成更大的人臉。特別的,每個圖片都通過以下5種方式中的一種來完成該部分。裁剪最大的正方形,其他四種方形圖片塊來自原始影象最短邊的[0.3,1]倍。這些裁剪圖片塊中都保證人臉區域的中心還在裁剪的塊中;
- 水平翻轉:在隨機翻轉中,選擇的平方塊被resize到640x640,然後以0.5的概率水平翻轉。
loss 函式
採用RPN中定義的多工loss:
\[L({p_i},{t_i})=\frac{\lambda}{N_{cls}}\sum_iL_{cls}(p_i,p_i^*)+\frac{1}{N_{reg}}\sum_ip_i^*L_{reg}(t_i,t_i^*)\]
這裡\(i\)表示第幾個錨,\(p_i\)表示關於第\(i\)個錨預測人臉的概率。這裡ground-truth標籤如果錨為正,則\(p_i^*\)是1,否則為0。\(t_i\)是一個向量,表示預測的邊界框的4個引數化的座標,\(t_i^*\)是關聯一個正錨的ground-truth。分類loss\(L_{cls}(p_i,P_i^*)\)是基於2類的softmax loss。迴歸loss\(L_{reg}(t_i,t_i^*)\)是《Fast r-cnn》中定義的平滑L1 loss,\(P_i^*L_{reg}\)意味著迴歸loss只被正錨啟用。這兩項分別被\(N_{cls}\)和\(N_{reg}\)所歸一化,並通過平衡引數\(\lambda\)所權重化。在我們的實現中,\(cls\)項是通過正錨和負錨的數量歸一化,而\(reg\)項是通過正錨的數量歸一化。因為正錨和負錨之間數量不平衡,所以引入\(\lambda\)進行平衡。
硬負樣本挖掘
在錨匹配過程中,大多數錨都是負的,這引入一個明顯的正負訓練樣本不平衡的問題。對於更快的優化和更穩定的訓練,需要對負樣本進行取樣,那麼就按照loss進行排序,並挑選排序前面的樣本,保持負正樣本比例3:1。在使用硬負樣本挖掘後,我們將上面的背景標籤\(N_m=3\),且\(\lambda=4\)來平衡分類和迴歸的loss。
其他細節
比如引數初始化,這裡急促和卷積層與VGG16採用一樣的結構,他們的引數也是《Imagenet large scale visual recognition challenge》進行預訓練的。conv_fc6,conv_fc7通過VGG16的fc6和fc7進行子取樣來初始化,其他的額外從通過xavier方式初始化。通過帶有0.9動量的SGD來訓練,權重衰減值為0.0005,batchsize為32。最大的迭代次數為120k,前80k次學習率為0.001,後20k為0.0001,然後接下來20k為0.00001。基於caffe實現。
.