
Face Detection SSH 論文理解
阿新 • • 發佈:2019-01-10
最近做人臉相關專案的時候在檢測階段用到了SSH和MTCNN兩種演算法,學習一下paper的具體內容並記錄一些重點
paper:: Single Stage Headless Face Detector
link:SSH paper
code:https://github.com/mahyarnajibi/SSH
摘要
- 本文提出了一個one stage人臉檢測器
- headless的解釋:在分類CNN網路的基礎上移除了fully connected layer;
- 具有尺度不變性性特徵:沒有用影象金字塔image pyramid輸入策略,只是在inference的時候用了多尺度的特徵層feature pyramid來做檢測(SSD演算法思想);
- 由此產生的優點:速度快、輕量級,如果用上影象金字塔策略在WIDER所有的subset上都取得很好的表現;
引言

- 目前存在問題:雖然目前人臉檢測的效能已經有了飛躍的提升但是在同時考慮速度和記憶體利用有效性的情況下,小人臉的檢測還存在很大的挑戰,WIDER資料集中就包含大量的小人臉;
- 提出一個解決方案SSH:基於去掉head的CNN分類網路,使用特徵金字塔代替影象金字塔設計出one stage人臉檢測演算法;
- 在各資料集上的表現:WIDER上配合影象金字塔可以在三個子集都達到最好的效能,FDDB和Pascal-Faces在相對小的輸入尺寸的情況下能夠達到最好的效能;
相關工作
- 人臉檢測相關進展:
- 文中主要提及了基於Faster-RCNN改進的two stage演算法CMS-RCNN,以及
Finding Tiny Faces; - 有影象金字塔影響演算法速度提出了利用特徵金字塔的SSH演算法;
- 文中主要提及了基於Faster-RCNN改進的two stage演算法CMS-RCNN,以及
- 單階段檢測器和推薦區域網路進展:
- 目前one stage主流的演算法有SSD、YOLO,但是在COCO檢測資料集上還是two stage的演算法效能更好;
- 目前的proposal network有兩種anchor定義方式:Scalable, high-quality object detection使用聚類來定義anchor,RPN將anchor定位為以特徵圖上每個位置為中心的具有各種比例和尺寸的密集網格框,ssh採用RPN類似策略來構建anchor;
- 尺寸不變性和context建模進展:
- 目前檢測模型針對不同尺寸的檢測主要有兩種策略:影象金字塔、特徵金字塔,SSH採用後面這種策略;
- two stage的context建模通常通過擴開proposal周圍的視窗;
(context建模應該是指上下文特徵的融合?理解錯誤的地方希望大家糾正)
SSH network
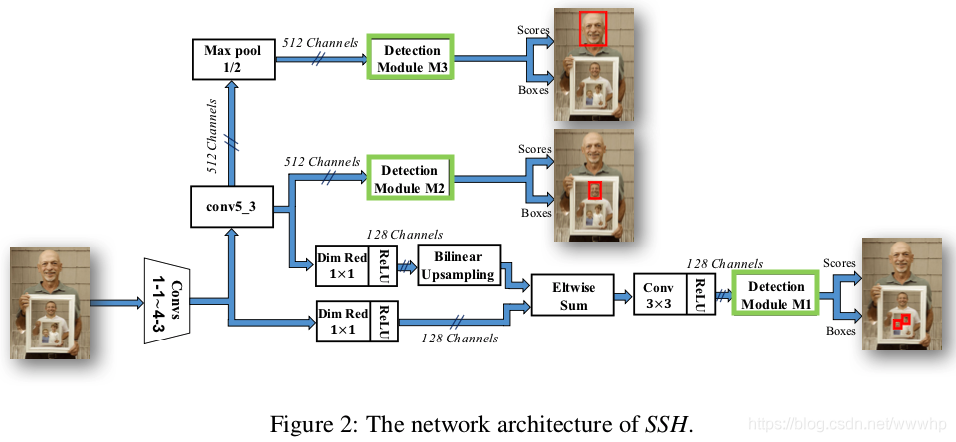

- SSH的設計目標:
inference time少,memory foot-print低,scale-invariant特性; - SSH整體結構:
- 從上圖2中可以看出在stride為8、16、32的feature map後面加上
detection module, ,這些模組主要由卷積層組成用以完成binary classifier和regressor; - 關於bbox迴歸的任務,參考RPN的思路引入
anchor,每個location有 個不同scale anchor,文中提到在人臉檢測任務中anchor的長寬比固定就行,多樣的比例對檢測結果沒有明顯的影響; - feature map size為 ,總共有 個anchor,由不同的scale組成的集合 ;
detection module中還添加了一個context module用來提升感受野的影響,模型最終的輸出tensor shape為 用來表示bbox的分類結果, 用來表示bbox的迴歸結果;
- 從上圖2中可以看出在stride為8、16、32的feature map後面加上
- 尺寸不變性設計:
- 通過在不同stride的feature map上檢測small、medium、larger人臉解決目標多尺度的問題;
- 在 的檢測階段中用到了特徵融合的方法將 的feature map使用bilinear的方法上取樣和 的feature進行融合;
- context模組:
context module使用 的卷積核序列來實現 以及 的卷積核效果,通過卷積層來代替two-stage檢測方法中通過擴充proposal around window來達到上下文合併的策略(沒太明白文中提到的two-stage檢測方法中的context合併策略,可能得迴歸一下Faster-RCNN的RPN部分了);detection module整體比RPN的引數量要少,context module能夠提升檢測效能;
- training:
- 針對不同的檢測模組使用不同scale的人臉進行訓練,只要人臉的scale沒有在當前模組的規定scale範圍內則不會回傳loss,anchor和GT iou大於0.5則被當做true positive;
- Loss function:
:
- 代表分類loss採用logistic loss, 表示 檢測階段所有的anchor, 表示和GT iou大於0.5具有positive label的bbox和iou小於0.3具有negtive label的bbox, 表示參與分類運算的anchor數量;
- 代表迴歸loss採用smooth L1 loss,和大多數檢測一樣需要將anchor和GT在log空間進行編碼, 表示只有positive anchor才能參與迴歸loss的計算;
- OHEM線上困難樣本挖掘:
- OHEM在SSH中被獨立地應用於每一個檢測模組 ,在每一個檢測模組中選擇置信度最高的負樣本和置信度最低的正樣本按照3:1的比例進行批量訓練(和SSD裡面OHEM用法有所區別,SSD只有困難負樣本挖掘,且OHEM是針對分類任務的概念/font>)
實驗結果
- anchor生成階段對應的尺寸是