
face detection[DSFD]
本文來自《DSFD: Dual Shot Face Detector》,時間線為2018年10月,是南理工Jian Li在騰訊優圖實驗室實習時候的作品。在WIDER FACE,FDDB上效果也超過了PyramidBox和SRN。
0 引言
最近在比賽上拿到最好成績的人臉檢測模型大致可以分成2類:
- 基於RPN的網路,這種網路是2階段模型
- 基於SSD這種一次shot檢測,直接預測邊界框和置信度。
而一次shot的檢測器因其高預測速度和簡單的系統設計而更受青睞。不過分析下來,仍然有以下三個問題未完全解決:
- 特徵學習:當前特徵金字塔網路(feature pyramid network,FPN)廣受應用,然而FPN只是將high-level和low-level的輸出網路層簡單合併了下,並未考慮到當前層的資訊,而且基於錨之間的上下文關係資訊都被忽略了;
- loss設計:主流使用的是目標檢測中傳統的loss函式,為了解決類別不平衡問題,Focal loss可以重點關注一個稀疏的硬樣本的訓練。為了使用所有原始和增強的特徵,《Feature agglomeration networks for single stage face detection》提出層級loss以更有效訓練網路。然而上面這些loss函式都沒考慮到feature map在不同level上需要漸進學習的能力;
ps:平滑L1 loss有助於阻止梯度爆炸;- 錨匹配策略:基本上,每個feature map上面的預定義錨集合是通過在圖片上平鋪不同尺度和長寬比的框完成的。許多別人先前的工作分析了錨的合理尺度和錨的補償策略,以此來增加正錨的數量。然而這些策略忽略了資料增強中的隨機取樣。人臉尺度的連續性和大量不同尺度的錨仍然會導致負錨和正錨之間比例的差距
本文提出了一個新的人臉檢測框架叫DSFD(dual shot face detector),其繼承了SSD的結構:
- 首先,結合PyramidBox中low-level的FPN與RFBNet中的感受野塊(receptive field block,RFB),提出一個特徵增強模組(feature enhance module,FEM)來增強特徵的判別性和魯棒性;
- 其次,受到《Feature agglomeration networks for single stage face detection》中層級loss(hierarchical loss)和PyramidBox中的金字塔錨的啟發,將更小的錨平鋪到higher-level feature map cell上可以獲得更多關於分類的語義資訊和更多關於檢測的高解析度定位資訊。提出漸進錨loss(progressive anchor,loss,PAL),通過一組更小的錨去計算輔助有監督loss,以輔助特徵學習;
- 最後,提出一個改進錨匹配方法(improved anchor matching,IAM),在DSFD中融合錨劃分策略和基於錨的資料增強方法去,以提供更好的迴歸器初始化,讓錨和ground-truth人臉儘可能匹配。

圖1顯示更小的錨平湖和改進的錨與ground-truth人臉的匹配可以消除尺度和遮擋的問題,從而提升人臉檢測效能。
1 結構
1.1 DSFD的結構(Pipeline of DSFD)
DSFD的結構如圖2。
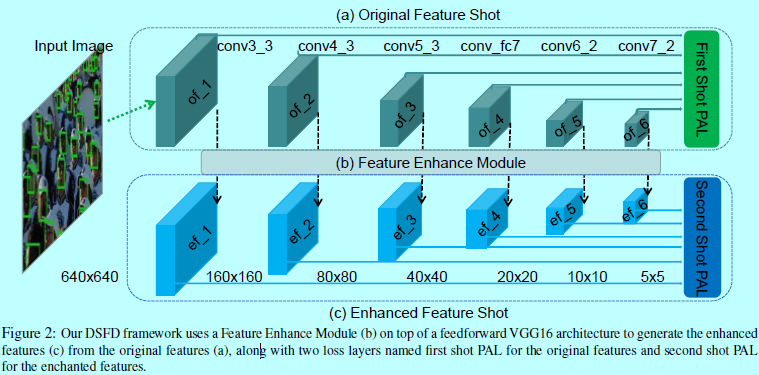
作者也採用如PyramidBox和S3FD中一樣的策略,通過擴充套件VGG16作為DSFD的基底骨幹網路,即將VGG16的全連線層替換成其他輔助的卷積層。作者選擇conv3_3,conv4_3,conv5_3,conv_fc7,conv6_2,conv7_2作為first shot檢測器層,以生成6個original feature maps,其對應命名為, \(of_1\), \(of_2\), \(of_3\), \(of_4\), \(of_5\), \(of_6\);然後,作者提出的FEM可以將這些original feature maps 轉換成6個增強的feature maps,其對應命名為 \(ef_1\), \(ef_2\), \(ef_3\), \(ef_4\), \(ef_5\), \(ef_6\),它們與對應的original feature maps有相同的size,通過將他們輸入到SSD型別的頭部,以此構建second shot 檢測層。注意到訓練圖片的輸入size是640,這意味著lowest-level層到highest-level層的feature map的size 從160到5。不同於S3FD和PyramidBox, 在使用FEM對感受野增強和新的錨設計策略後,原則上就沒必要讓(stride,錨,感受野)這三個size滿足等比例間隔原則。因此,DSFD更靈活也更魯棒。同時,original和enhanced shot有2個不同的loss。分別被命名為第一次shot漸進式錨loss(first shot progressive anchor loss, FSL)和第二次shot漸進式錨loss(second shot progressive anchor loss, SSL)。
1.2 特徵增強模組(Feature Enhance Module)
這裡提出的FEM模組主要是為了增強original features 讓特徵變得更據辨識性和魯棒性。對於當前錨\(a(i,j,l)\),FEM會利用包含當前層錨\(a(i-1,j-1,l)\),\(a(i-1,j,l)\),...\(a(i,j-+1,l)\),\(a(i+1,j+1,l)\)和上層錨\(a(i,j,l+1)\)的不同維度資訊。具體的,關聯錨\(a(i,j,l)\)的feature map cell可以通過數學定義:
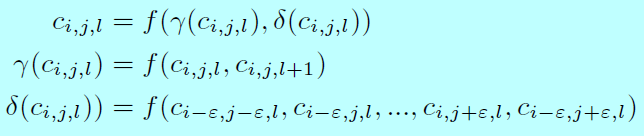
這裡 \(c_{i,j,l}\)是在第 \(l\)層中feature maps上座標為 \((i,j)\)的cell, \(f\)表示擴張卷積(dilation convolution),逐元素相乘和上取樣操作的組合, \(\gamma, \delta\)分別表示當前層資訊和上一層資訊。
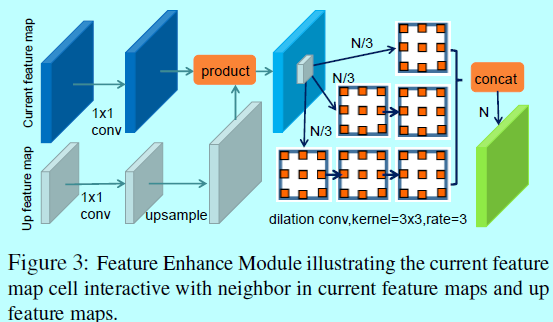
如圖3所示,其是FEM的原理,主要是受到FPN和RFB的啟發。這裡:
- 首先用1x1卷積核去歸一化feature maps;
- 然後,上取樣上一層feature maps並與當前層進行逐元素相乘;
- 最後,將feature maps劃分成3個部分,並連線對應的3個子網路,每個子網路包含不同數量的擴張卷積層。
1.3 漸進錨loss(Progressive Anchor Loss)
DSFD採用的是多工loss,因為其可以讓original和enhanced feature maps的訓練任務以兩個shots進行訓練。首先,DSFD的second shot anchor-based 多工loss函式定義如下:
\[L_{SSL}(p_i,p_i^*,t_i,g_i,a_i)=\frac{1}{N}(\sum_iL_{conf}(p_i,p_i^*)+\beta\sum_ip_i^*L_{loc}(t_i,g_i,a_i))\]
這裡\(N\)是匹配的密集邊界框的個數;\(L_{conf}\)是基於2個類(人臉和背景)的softmax loss;\(L_{loc}\)是基於錨\(a_i\)下,介於引數化的預測邊界框\(t_i\)和ground-truth邊界框\(g_i\)之間的平滑L1 loss;當\(p_i^*=1(p_i^*=\{0,1\})\)時,錨\(a_i\)是正類,且此時位置loss也是啟用的。\(\beta\)是一個權衡這兩個loss的超引數。相比於同一個level中的enhanced feature maps,original feature maps針對分類的語義資訊更少,但是有更多針對檢測的高解析度定位資訊。因此,作者認為original feature maps可以檢測和分類更小的人臉。因此,作者提出了基於一組更小錨的first shot 多工loss:
\[L_{FSL}(p_i,sp_i^*,t_i,g_i,sa_i)=\frac{1}{N}(\sum_iL_{conf}(p_i,sp_i^*)+\beta \sum_ip_i^*L_{loc}(t_i,g_i,sa_i))\]
這兩個shot loss可以組合成一個漸進式錨loss:
\[L_{PAL}=L_{FSL}(a)+L_{SSL}(sa)\]
這裡first shot中錨的size是second shot中的一半。在預測階段,只採用second shot的輸出,這意味著預測階段並不會有額外的計算代價。
1.4 改進的錨匹配策略(Improved Anchor Matching)
在訓練中,需要計算正錨和負錨以決定對應人臉邊界框是哪一個錨。當前錨匹配方法是基於錨和ground-truth人臉之間雙向選擇。因此錨的設計和增強的人臉取樣是協同的,以此儘可能讓錨和人臉進行相配,以此提供迴歸器更好的初始化。

表1顯示DSFD的錨設計細節,每個feature map cell是如何關聯固定shape的錨的。這裡基於人臉尺度的統計資訊,將錨尺度的比例設為1.5:1。original feature中錨的size是enhanced feature中的一半。另外,在資料增強上:
- 基於\(\frac{2}{5}\)的概率,採用PyramidBox中data-anchor-sampling相似的基於錨的取樣,其是在一個圖片中隨機選擇一個人臉(裁剪的子圖片包含人臉),並將子圖和選擇的人臉之間size比例設定為\(\frac{640}{rand(16,32,64,128,256,512)}\);
- 基於\(\frac{3}{5}\)的概率,採用SSD中的資料增強方法。
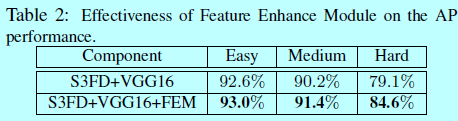
2 實驗結果分析


.