
社交網路演算法
社交網路演算法
1、應用場景
在社交網路中社群圈子的識別
基於好友關係為使用者推薦商品或內容
社交網路中人物影響力的計算
資訊在社交網路上的傳播模型
虛假資訊和機器人賬號的識別
基於社交網路資訊對股市的預測
網際網路金融行業中的反欺詐模型
2、社交網路演算法的分析指標
1)度(Degree)
連線點活躍性的度量;與點相連的邊的數目。在有向圖中,以頂點A為起點記為出度(out degree)OD(A),以頂點A為終點入度(In degree)ID(A),則頂點A的度為D(A) = OD(A) + ID(A)。
計算方法:
g = Graph([(0,1), (0,2), (2,3), (3,4), (4,2), (2,5), (5,0), (6,3), (5,6)])
g.degree()
ecount = g.ecount()#統計邊的數目
vcount = g.vcount()#統計節點數目
maxdegree = g.maxdegree()#最大度值
2)緊密中心性(closness centrality)
節點V到達其他節點的難易程度,也就是到其他所有節點距離的平均值的倒數。
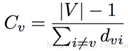
實現方法:
ccvs = []
for p in zip(g.vs, g.closeness()):
ccvs.append({"name": p[0], ["name"], "cc": p[1]})
sorted(ccvs, key=lambda k: k['cc'], reverse=True)[:10]
3)介數中心性
如果一個成員A位於其他成員的多條最短路徑上,那麼成員A的作用就比較大,也具有較大的介數中心性。
本質:網路中包含成員B的所有最短路徑條數佔所有最短路徑條數的百分比。
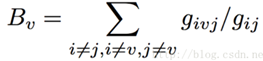
計算步驟:
1.計算每對節點(i,j)的最短路徑(需要得到具體的路徑)
2. 對各節點判斷v是否在最短路徑下
3. 累加經過v的最短路徑條數
btvs = []
for p in zip(g.vs, g.betweenness()):
btvs.append({"name": p[0]["name"], "bt": p[1]})
sorted(btvs, key=lambda k: k['bt'], reverse=True)[:10]
3、社群發現演算法
3.1 GN 演算法
邊介數(betweenness):
網路中經過該邊的最短路徑佔所有最短路徑的比例。
GN演算法計算步驟:
1. 計算網路中所有邊的介數
2. 找到介數最高的邊,並將它從網路中移除
3. 重複以上步驟,直到每個節點就是一個社群為止。

3.2 Louvain 演算法
Louvain演算法是基於模組度的演算法,其優化目標就是最大化整個社群網路結構的模組度。
模組度
它的物理含義是社群內節點的連邊數與隨機情況下節點的連邊數之差,它可以衡量一個社群緊密程度的度量。因此模組度就可以作為優化函式優化社群的分類。
計算方法如下:

其中,Aij節點i和節點j之間邊的權重,網路不是帶權圖時,所有邊的權重可以看做是1;ki=∑jAij表示所有與節點i相連的邊的權重之和(度數);ci表示節點i所屬的社群;m=∑ijAij表示所有邊的權重之和(邊的數目), 取值範圍:[-1/2, 1)。
公式中Aij−=Aij−ki,節點j連線到任意一個節點的概率是現在節點i有ki的度數,因此在隨機情況下節點i與j的邊為.
δ(ci, cj)將所有的節點都限制在一個社群中,另一個重點是ki和kj都是包括與其他社群相連的邊數,因此是在隨機情況下節點i和節點j的邊數。
基於模組度的社群發現演算法,都是以最大化模組度Q為目標。
演算法思想
Louvain演算法的思想很簡單:
1)將圖中的每個節點看成一個獨立的社群,次數社群的數目與節點個數相同;
2)對每個節點i,依次嘗試把節點i分配到其每個鄰居節點所在的社群,計算分配前與分配後的模組度變化Delta Q,並記錄Delta Q最大的那個鄰居節點,如果maxDelta Q>0,則把節點i分配Delta Q最大的那個鄰居節點所在的社群,否則保持不變;
3)重複2),直到所有節點的所屬社群不再變化;
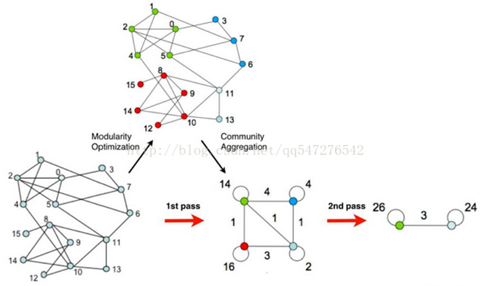
4)對圖進行壓縮,將所有在同一個社群的節點壓縮成一個新節點,社群內節點之間的邊的權重轉化為新節點的環的權重,社群間的邊權重轉化為新節點間的邊權重;
5)重複1)直到整個圖的模組度不再發生變化。
使用圖來表示演算法的過程:
3.3 LPA與SLPA
LPA演算法思想:
1. 初始化每個節點,並賦予唯一標籤
2. 根據鄰居節點最常見的標籤更新每個節點的標籤
3. 最終收斂後標籤一致的節點屬於同一社群
SLPA演算法思想:
SLPA是LPA的擴充套件。
1. 給每個節點設定一個list儲存歷史標籤
2. 每個speaker節點帶概率選擇自己標籤列表中標籤傳播給listener節點。(兩個節點互為鄰居節點)
3. 節點將最熱門的標籤更新到標籤列表中
4. 使用閥值去除低頻標籤,產出標籤一致的節點為社群。