
統計學習方法_李航_筆記
統計學習方法_李航
因本人剛開始寫部落格,學識經驗有限,如有不正之處望讀者指正,不勝感激;也望藉此平臺留下學習筆記以溫故而知新。這一篇文章介紹的是李航的統計學習方法一書的第一遍學習筆記。
統計學習方法概論
統計學習方法概論
統計學習的物件是資料,從資料出發,提取資料的特徵, 抽象出資料的模型, 發現數據中的知識, 又回到對資料的分析與預測中去。
統計學習的目標是考慮學習什麼樣的模型和如何學習模型,以使模型能對資料進行準確的預測與分析,同時也要考慮儘可能地提高學習效率。
統計學習的組成:監督學習、非監督學習、半監督學習和強化學習等。
統計學習方法的三要素:模型、策略和演算法.
學習或選擇最優模型的預測錯誤的程度度量:通常採用損失函式或代價函式。
統計學習常用的損失函式:損失函式、平方損失函式、絕對損失函式、對數損失函式。
典型的生成模型:樸素貝葉斯法和隱馬爾可夫模型。
典型的判別模型:k近鄰法、感知機、決策樹、邏輯斯諦迴歸模型、最大熵模型、支援向量機、提升方法和條件隨機場等。
生成方法的特點: 生成方法可以還原出聯合概率分佈P(X,Y), 而判別別方法則不能。生成方法的學習收斂速度更快, 即當樣本容量增加的時候, 學到的模型可以更快地收斂於真實模型;當存在隱變數時,仍可以用生成方法學習,此時判別方法就不能用。
判別方法的特點:判別方法直接學習的是條件概率 P(Y|X)或決策函式f(X),直接面對預測,往往學習的準確率更高;由於直接學習P(Y|X)或f(X),可以對資料進行各種程度上的抽象、定義特徵並使用特徵,因此可以簡化學習問題。
實現統計學習方法的步驟如下:
(1)得到一個有限的訓練資料集合;
(2)確定包含所有可能的模型的假設空間,即學習模型的集合;
(3)確定模型選擇的準則,即學習的策略;
(4)實現求解最優模型的演算法,即學習的演算法;
(5)通過學習方法選擇最優模型;
(6)利用學習的最優模型對新數掘進行預測或分析。
監督學習圖示:

感知機學習演算法

K近鄰

K近鄰模型由三個基本要素距離度量、k值的選擇和分類決策規則決定。
距離度量:

K近鄰法的實現:kd樹
構造kd樹


搜尋kd樹


樸素貝葉斯

決策樹
決策樹學習過程
• 特徵選擇
• 決策樹生成:遞迴結構 ,對應於模型的區域性最優
• 決策樹剪枝:縮小樹結構規模、緩解過擬合


ID3基於資訊增益作為屬性選擇的度量


C4.5基於資訊增益比作為屬性選擇的度量

邏輯迴歸模型

支援向量機


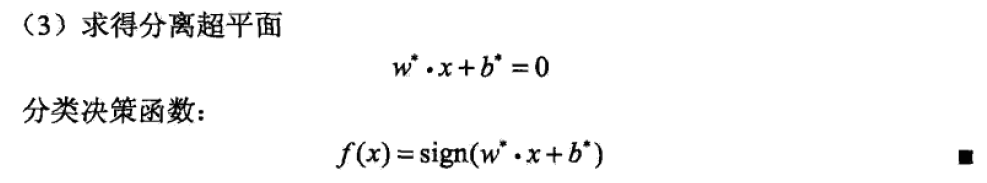
提升方法boosting
核心:多個弱分類器可以組成成為強分類器


EM演算法
求期望,再求最大值



隱馬爾可夫模型


參考文獻
統計學習方法 李航