K近鄰分類
阿新 • • 發佈:2018-11-29
K近鄰分類
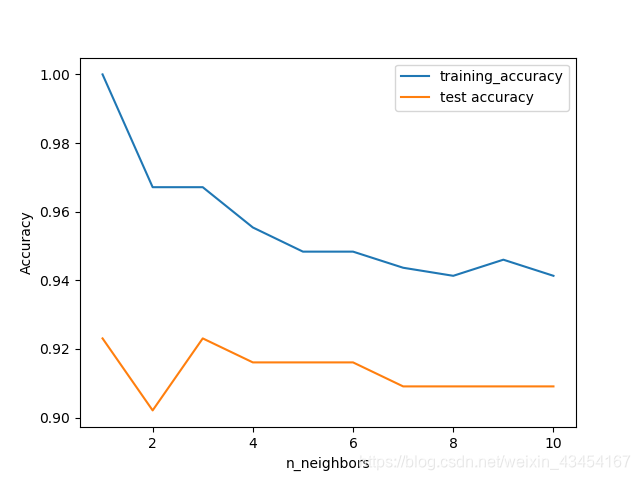
import numpy as np import matplotlib.pyplot as plt import pandas as pd import mglearn from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier cancer = load_breast_cancer() X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target,random_state=66) training_accuracy = [] test_accuracy = [] neighbors_setting = range(1, 11) #neighbor存成一維陣列 for n_neighbors in neighbors_setting: #構建模型 clf = KNeighborsClassifier(n_neighbors=n_neighbors) clf.fit(X_train, y_train) #記錄訓練集精度 training_accuracy.append(clf.score(X_train, y_train)) #記錄泛化精度 test_accuracy.append(clf.score(X_test,y_test)) plt.plot(neighbors_setting, training_accuracy, label="training_accuracy") plt.plot(neighbors_setting, test_accuracy, label='test accuracy') plt.ylabel("Accuracy") plt.xlabel("n_neighbors") plt.legend() plt.show()