
Hadoop核心元件之HDFS
HDFS:分散式檔案系統
一句話總結
一個檔案先被拆分為多個Block塊(會有Block-ID:方便讀取資料),以及每個Block是有幾個副本的形式儲存
1個檔案會被拆分成多個Block blocksize:128M(Hadoop2.0以後預設的塊大小,可以自定義配置) 130M ==> 2個Block: 128M 和 2M
HDFS設計目標
- 巨大的分散式檔案系統
- 滿足大資料場景基本資料儲存的要求
- 廉價的機器上
- 當你的儲存空間不夠,你可以水平橫向擴充套件機器方式提高
HDFS架構
NameNode + N個DataNode
典型的主從架構,即: 1 Master(NameNode/NN) 帶 N個Slaves(DataNode/DN) 建議:NN和DN是部署在不同的節點上 PS: 常見的主從架構還有:HDFS/YARN/HBase 主從架構一個難題就是:如何保證HA的問題,很多時候會使用Zookeeper來配置使用
NameNode/NN:主節點Master 1)負責客戶端請求的響應 2)負責元資料(檔案的名稱、副本系數、Block存放的DN)的管理
DataNode/DN:從節點Slaves 1)儲存使用者的檔案對應的資料塊(Block) 2)要定期向NN傳送心跳資訊,彙報本身及其所有的block資訊,健康狀況
HDFS副本機制
-
replication factor:副本系數、副本因子
-
一個大的檔案會被拆分為許多塊,最終以多副本的方式儲存在多個節點上
-
一個檔案,除了最後一個,其餘所有塊的大小都是一致的
問題:那麼如何為每個Block選擇儲存在哪些節點上呢?
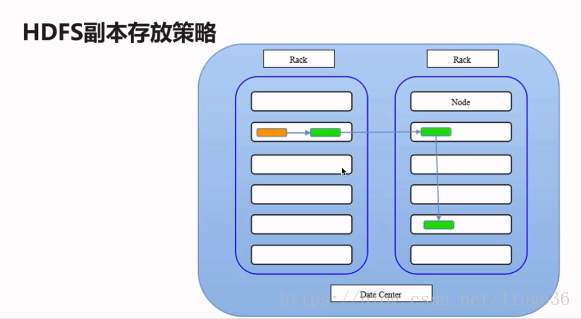
Rack代表的是機架:一般三份副本分別是這樣儲存的 第一份副本:儲存在當前提交儲存的機架中當前節點上 第二份副本:儲存在非當前機架上的某一節點上 第三份副本:和第二副本統一機架的不同節點之上 建議:生產只能夠,起碼劃分兩個及其以上的機架
HDFS Shell
Usage: hdfs dfs [COMMAND [COMMAND_OPTIONS]] hadoop fs -ls / 等價 hdfs dfs -ls /
[[email protected] data]# ls
hadoop-tmp hello.txt
上傳:
[[email protected] data]# hadoop fs -put hello.txt /
下載:
[[email protected] data]# hadoop fs -get /test/a/b/h.txt
檢視內容:
[[email protected] data]# hadoop fs -text /hello.txt
[ HSFS的讀寫流程,工作原理(面試)
Client:客戶端,通過HDFS Shell或Java API發起讀寫請求 1個NameNode:全域性把控 N 個DataNode: 資料儲存
寫資料流程:
1.客戶端把檔案拆分為多個Block 2.NameNode:提供剛才拆分出來的Block塊的具體datanode儲存位置 3.DataNode:儲存Block塊的資料,把3個副本資料寫完
讀資料流程:
1.使用者提供檔名就可以給客戶端 2.客戶端發起請求給NameNode 3.NameNode就會告訴客戶端具體的儲存位置和塊 4.發起最近距離節點請求給DataNode下載資料
HDFS的優缺點
優點: 資料冗餘,硬體容錯 一次寫入,多次讀取資料 適合儲存大檔案 構建在廉價機器上
缺點: 延時性高 不適合小檔案儲存