
GTC中國2018參會見聞及思考
人只不過是一根葦草,是自然界最脆弱的東西;但他是一根能思想的葦草. --- 帕斯卡
人類一思考,上帝就發笑 --- 米蘭昆德拉
GTC是Nvidia組織的關於GPU技術的大會,隨著深度學習的蓬勃發展,3D技術的演進及平行計算等已經慢慢地成為了較成熟的技術而較少地展示;更多的是AI及深度學習在各個領域,各個層面的佈局、應用及展示。GTC的舉辦地從最開始的美國矽谷一個地方發展到現在的包括中國,歐洲,日本等7個地方。這次中國的GTC(11/20~11/22)從以往的舉辦地北京移師到蘇州金雞湖,參會人數破紀錄的超過了5000人。帶著一個平行計算演講的任務,比較全情投入地參加了3天的大會,在此,做一些記錄及思考,偏主觀個人經驗及感受,但也希望能給大家帶來一點了解及思考。
1 自動駕駛的workshop
汽車是一個巨大的工業化產業,技術含量及附加值較高,覆蓋的產業長,使用者規模大且使用頻繁,是很多大城市及國家的重點產業。同時,全世界每年都會有上百萬人(WHO2015年報告為125萬)因為車禍而死亡,相應的財產損失更是萬億級別(用汽車保費*車輛數等進行簡單估計:))。因此,汽車自動駕駛可以算是當前人工智慧領域最大的一個商業研發場景。在11/20的workshop中,Nvidia邀請了中國幾十家自動駕駛相關廠商的上百人,包括上汽,吉利,小鵬等參加了這個"高階產品推介會”。在晶片領域,譬如早期顯示卡的筆記本市場,贏得的一個筆記本產品叫一個design win,在汽車自動駕駛領域,雖然更加複雜,Nvidia也正通過優秀的產品參考設計,舉辦類似的workshop等等,慢慢地在爭取越來越多的汽車企業及方案提供商取樣Nvidia的晶片及系統,下圖是當前Nvidia公佈的一些合作伙伴。

1.1 超強計算力的底層硬體
AI需要比較強大的計算能力,自動駕駛根據自動程度劃分為L1到L5(完全不需要人的操作)5個等級,Nvidia提供的最新的AI平臺著力於L2到L4的計算能力支援。根據不同的需求,它分為Xavier-S, Xavier和Pegasus 3個計算平臺,具體的一些效能引數如下:

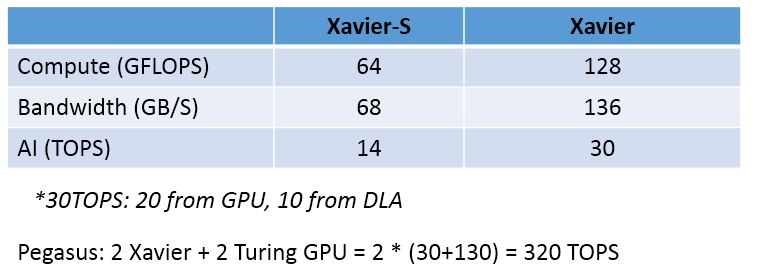
從上述效能可以看出,Pegasus平臺比史上最強核彈V100的AI計算能力還要強悍1倍以上(因為op不是fp16等了)。
1.2 強大豐富的軟體生態
硬體和軟體是相互依存的,沒有強大的軟體,硬體的效能發揮不出來;沒有豐富的軟體生態,硬體也沒有太多的發揮空間。在汽車自動駕駛領域更是如此。Nvidia是一家晶片公司,計算公司,但隨著和汽車領域的相互合作(差不多3,4年左右的樣子),對自動駕駛有了越來越深的理解。它把整個軟體棧分為 Drive OS,DriveWorks和Driving Application3個層次,具體如下:
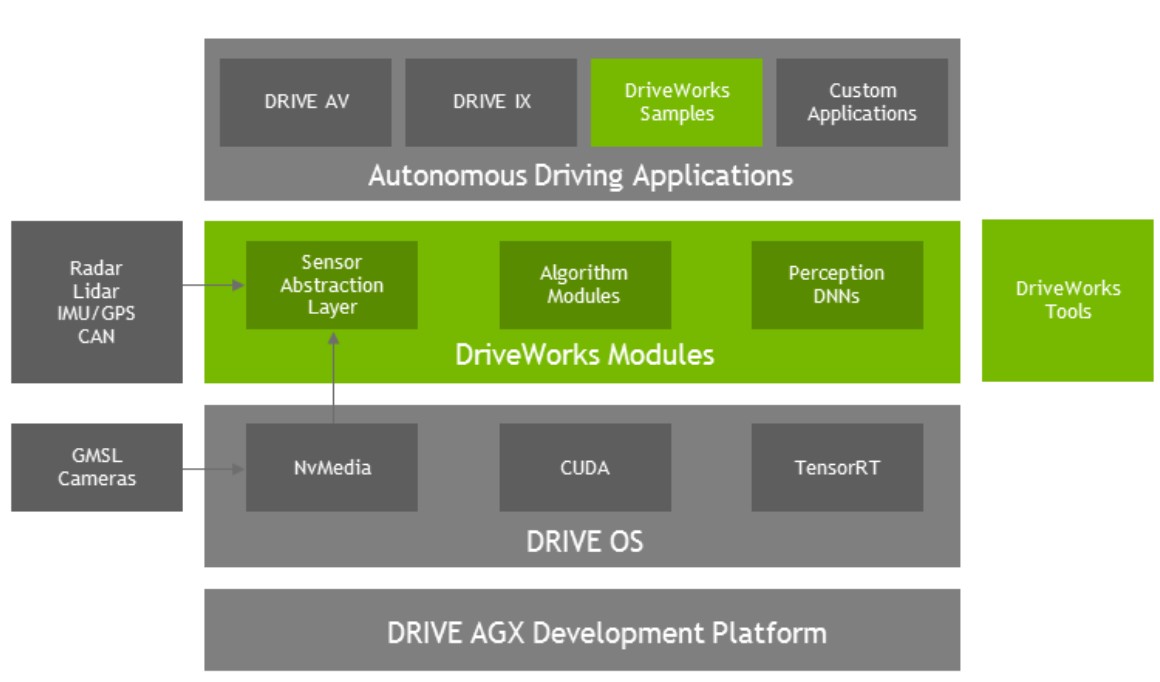
- Drive OS:最底層,也是通用Nvidia GPU的支援,包括driver,cuda,及TensorRT等,是必不可少的部分。
- DriveWorks:中間層,是對汽車這個特別場景設計的硬體適配層,汽車自動駕駛涉及的感知器件包括Radar, Lidar, IMU, GPS和CAN等,這一層有對於這些典型硬體的參考使用設計。這層使用者可以使用自己的初始化程式及演算法等;對於參考設計不支援的感知器件,也需要使用者在這一層做針對性的設計。
- Driving Application:上層,主要是Drive AV和Drive IX。Drive AV負責感知車外的世界,譬如說周圍的汽車,可行駛的路線及交通訊號燈等;Drive IX負責感知車內的情況,主要是駕駛員的指令及狀態等。這一層使用者可以有更加個性化多樣化的設計。
1.3 更貼切的設計理念
Nvidia根據在汽車自動駕駛上經驗的不停積累,在解決具體的問題時,設計理念,思路等也有了一些轉變:
- 最重要的是安全:早期的自動駕駛側重在提供端到端的解決方案,就是根據汽車周圍的各種環境情況,直接給出汽車的駕駛決策。現在發現,即使這種端到端的方案效能有可能是最好的,但肯定不是最合適的。自動駕駛是這麼一個人命關天的大事情,而機器學習很多時候又有很多的不可解釋性。因此,整體的解決方案,一定要做到可控並且讓乘客可理解。所以,AI的結果,需要具體到周圍(至少180度)的車輛,接下來要執行的path,前方的sign等等,需要給出具體的識別並且顯示出來,讓人也能理解它是怎麼想怎麼開的。
- 不僅僅關注外部:原則上自動駕駛只需要關注外部的環境就好,但在當前L2~L4階段,也需要對車輛內部的資訊進行響應,監控及反饋。譬如需要對司機的各種語音手勢等命令做出恰當的反應,同時也需要對司機的狀態進行監控及反饋,特別的司機是不是處在疲勞狀態,眼睛是否在有效的檢視行駛狀態等等。
- 通過遊戲等進行極限測試:現實中比較難以得到各種極端情況來測試自動駕駛系統的表現,可以通過遊戲等場景來進行模擬測試,也測試為主,訓練為輔(用遊戲的場景來大規模訓練不利於真實的場景)。遊戲模擬包括SIL(software in loop)和HIL(Hardware in loop)兩種。海量訓練的資料基本還是用真實的資料,然後可以分階段,早期有監督的還是需要採用大量的人(1000+)進行標註,到中後期以check及關注感興趣區域為主,這時候可以用一些演算法做輔助。
此外硬體安全也是特別重要的,Nvidia專門開發了IST軟體不間斷的對硬體進行safety測試。
1.4 用深度學習加強冗餘設計
因為安全是至關重要的,很有必要進行多維度的冗餘設計。在汽車駕駛過程中,最重要的2個點是:距離前方汽車的距離,及前方汽車和當前汽車的相對速度。普通的會用Radar,Lidar等進行測距,較常見的也會通過2個攝像頭通過3維重建等計算距離,計算相對速度等。

但在現實情況中,有可能攝像頭會有微小的上下左右的移動或者換動,一方面需要對這些硬體進行不定期的軟體矯正等。另外一方面Nvidia給出了一些其它嘗試,直接用深度學習網路識別得到距離和相對速度,從他們給出的結果來看,較近距離(<~60m)時網路識別還是比較準的。因此,在實際情況中,可以用多種方法進行投票,然後找一個相對合理又偏保守一點的結果。
2 GTC Keynote
黃教主的演講歷來是GTC的重頭戲,在開場前30分鐘,排隊已經排成下圖這個樣子了,信仰:)。最終整個3000人的演講廳無意外的座無虛席。然後Jensen的著裝及演講風格還是一如既往的(優酷的視訊連結,從學口語及演講角度也可以感受下),然後我個人的3點特別感受是:


2.1 AI在GPU上的應用
平時大家都是用GPU在其它的應用場景上做AI的應用,這一次,Nvidia在自己GPU渲染上也終於使用上了AI,並且效果還很不錯(如上圖)。這個技術叫做深度學習超級取樣(DLSS)技術。基於 Turing 架構的 DLSS 由兩個模型組成,其中一個模型經過訓練後可根據原始影象生成超高畫質影象,另一個經過訓練後可實現超解析度並以此作為輸出。經由Tensor Core 的計算,RTX 系列顯示卡可以同時實現高畫質和高解析度。
AI做為一種基礎的設施及能力(將來是要和最厲害的人在除了想象思考力之外的所有能力上比肩的),應該是可以在各個領域各個角落發揮出重要作用的!只要有價值。
2.2 CUDA平臺
越來越多的人也意識到(Jensen印象中也提到過類似的),Nvidia之所以會在高效能平行計算,深度學習等領域取得如此巨大的成功,如果非要找最關鍵的一個點,那就是CUDA,它是和C/C++,python等一樣可以為成千上萬的人簡單學習後就可以使用的一種並行程式語言及框架。特別的,它比較好的平衡了上層語音,底層硬體指令集及不同的架構等之間的關係而定義了ptx這一層,可以比較好的向前相容,又能不錯的向後擴充套件。

在這次GTC上,Jensen回顧了下CUDA的發展過程,差不多有12年的歷史,從一開始的寥寥無幾的下載到過去一年cuda的下載量達到了600萬。一個小插曲:回憶Fermi/Kepler等架構時發覺聽眾沒有反應,Jensen即興用中文調侃了下,並且期待下一年的時候可以是“講的是英文,聽眾聽到的是中文”。現在機器翻譯及NLP發展這麼迅猛,包括阿里的天貓精靈,明年這時候機器自動翻譯應該還真是很有可能。
2.3 其它挺震撼挺有意思的點

T4 inference的效能:如果只是一個數字(ResNet152 每秒識別1600多張圖片),沒有感覺。但如果識別具體的花,然後用滿滿的螢幕(15m*6m?)來展示效能對比時,還是很震撼的。所以,選一個具體常見的場景,並且進行視覺化的展示是很有必要的,畢竟人是視覺情感動物:)。
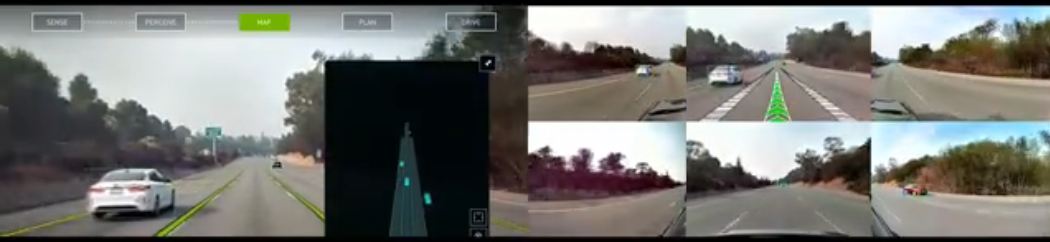
加州自動駕駛:用Nvidia自己的整套解決方案,在加州進行了全程的自動駕駛並記錄。這種富含資訊(不僅僅是自動駕駛了一段路,而是路上所有相關目標的跟蹤,規劃等等)的demo,給普通人對自動駕駛極大的信心。因為看見,所以相信。因為更具體更全方位的看見,所以更容易堅信成熟汽車自動駕駛技術的馬上到來。成本普及到普通的車?那應該還需要更長的一段時間。

跳舞的機器人及同步跳舞的Jensen/MJ/李小龍:機器人可以很流暢地跳舞,虛擬的人可以和另外一個人同步跳舞,挺好的一個展示。從這有帶人工智慧的機器人快要破繭而出的感覺。
3 資料中心和雲端計算基礎架構分論壇
3.1 用GPU加速時序資料的分析和查詢

在這個session中我present了過去半年我們和TSDB團隊一個關於平行計算的成果。在時序場景中用GPU加速了時序資料查詢及jason解析等,效果是原來CPU版本的~30倍,在此分享了一些通用的設計思想,具體的可以在ATA基於CUDA的應用加速方案設計方法找到。其中有一個和AI的思考點是:
- a. AI本質上是把傳統方法的60/80分提高到90/98分;
- b. 在某些領域,因為這種提升,實現了從偏人工到偏自動化,從不可用到可用,可以理解為0到1的突變;
- c. 但AI本質上還是一種提升精度/準確性等的方法,在部署到實際的應用場景中時,效能是特別重要的點,平行計算(先拋開硬體)還是特別重要的。
3.2 基於高效視訊計算框架的雲端視訊結構化分析平臺
優酷的盛驍傑同學做了這個分享,優酷已經開發出了AI視訊異構計算框架,包括視訊圖片的下載,解碼,影象的處理,及一些AI的應用等。一些AI應用包括對視訊進行自動化的分類,內容理解,對海量小視訊進行質量估計等等。
優酷有海量的視訊資料,並且也有使用者的評論資訊等,是有非常多的內容挖掘分析等的AI場景。
3.3 AI硬體基礎設施
百度研發了AI異構硬體GPU盒子X-MAN,採用了單機16卡,液冷散熱等;訓練叢集超過數萬顯示卡。華為有釋出面向資料中心的G5500異構伺服器,支援8卡V100或32塊P4,支援一鍵切換異構拓撲;面向園區等設計了G2500智慧分析伺服器,儲存容器達240TB。騰訊美團科大訊飛等也有類似的基礎設施。



3.4 其它
DaoCloud致力於用容器構建AI計算平臺,使用AI有主機、虛擬機器和容器3種方式,容器越來越成為主流計算架構。下圖比較通俗易懂的說明了容器的好處,需要有額外的Docker這一層但沒有了龐大的虛擬機器OS那一層,可以進行秒級的新任務部署。但怎麼在一片卡上同時執行2個容器?這還是公認的技術痛點和難點。

百度已經有把AI用在汽車車損的AI協助理賠上;在用AI分析足球賽也有不錯的成果,回頭球賽的精彩資訊編輯等AI應該完全可以勝任,也簡單展示了用AI給球員的表現進行打分的邏輯等。怎麼進行AI訓練呢?結合已有的海量足球視訊,再加上搜索技術,進行進球等的子任務訓練,然後融合等,避免或減輕了海量的視訊標註。

4 其它
計算平臺的葉帆同學介紹了PAI-Blade,對模型進行剪枝、模型壓縮、運算元優化及int8技術等等,對線上的inference有了顯著的效能提升。
騰訊介紹了強化學習在遊戲中的應用,包括圍棋,設計類遊戲及即時戰略類遊戲。回頭遊戲的電腦會越來越難打:)。另外,強化學習在遊戲中還是比較能夠發上力,因為不管feedback需要延遲多久但肯定還是有最終結果(可以用來構建groundTruth),在實際的業務場景中,要思考怎麼找到合適的groundTruth。
好吧,也就差不多這麼多了,耐心看完的同學,請點個贊:)。