
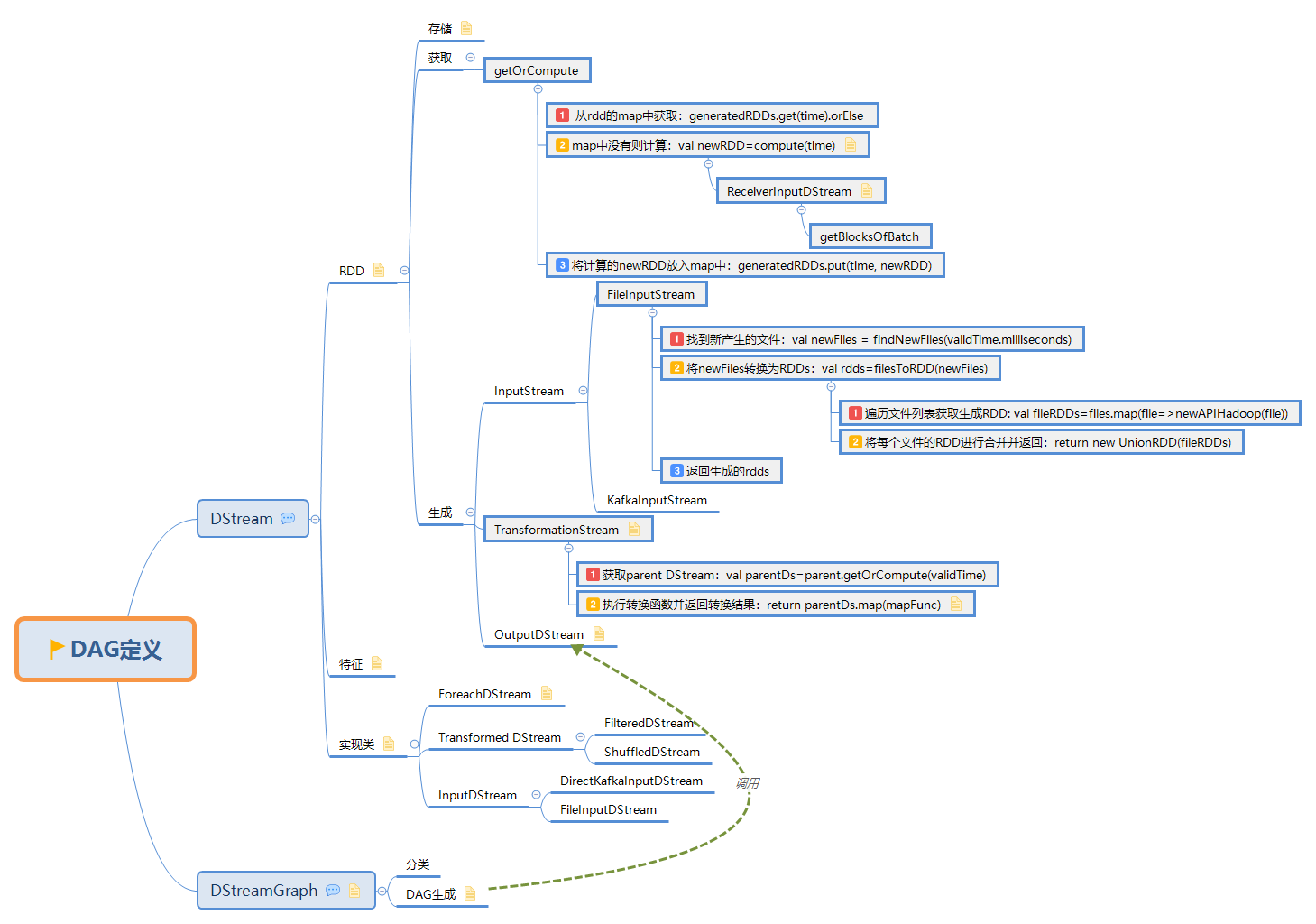
Spark——Streaming原始碼解析之DAG定義
此文是從思維導圖中匯出稍作調整後生成的,思維腦圖對程式碼瀏覽支援不是很好,為了更好閱讀體驗,文中涉及到的原始碼都是刪除掉不必要的程式碼後的虛擬碼,如需獲取更好閱讀體驗可下載腦圖配合閱讀:
此博文共分為四個部分:




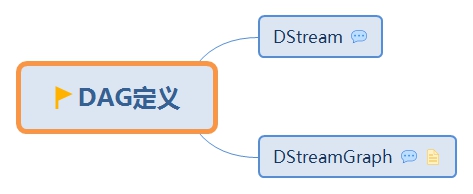
1. DStream
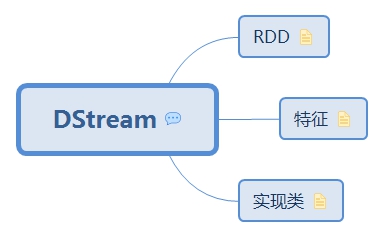
1.1. RDD
DStream和RDD關係:
DStream is a continuous sequence of RDDs:
generatedRDDs=new HashMap[Time,RDD[T]]()
1.1.1. 儲存
儲存格式
DStream內部通過一個HashMap的變數generatedRDD來記錄生成的RDD:
private[streaming] var generatedRDDs = new HashMap[Time, RDD[T]] ()
其中 :
- key: time是生成當前batch的時間戳
- value: 生成的RDD例項
每一個不同的 DStream 例項,都有一個自己的 generatedRDD,即每個轉換操作的結果都會保留
1.1.2. 獲取
1.1.2.1. getOrCompute

-
從rdd的map中獲取:generatedRDDs.get(time).orElse
-
map中沒有則計算:val newRDD=compute(time)
-
將計算的newRDD放入map中:generatedRDDs.put(time, newRDD)
其中compute方法有以下特點:
-
不同DStream的計算方式不同
-
inputStream會對接對應資料來源的API
-
transformStream會從父依賴中去獲取RDD並進行轉換得新的DStream
compute方法實現:
class ReceiverInputDStream{ override def compute(validTime: Time): Option[RDD[T]] = { val blockRDD = { if (validTime < graph.startTime) { // If this is called for any time before the start time of the context, // then this returns an empty RDD. This may happen when recovering from a // driver failure without any write ahead log to recover pre-failure data. new BlockRDD[T](ssc.sc, Array.empty) } else { // Otherwise, ask the tracker for all the blocks that have been allocated to this stream // for this batch val receiverTracker = ssc.scheduler.receiverTracker val blockInfos = receiverTracker.getBlocksOfBatch(validTime).getOrElse(id, Seq.empty) // Register the input blocks information into InputInfoTracker val inputInfo = StreamInputInfo(id, blockInfos.flatMap(_.numRecords).sum) ssc.scheduler.inputInfoTracker.reportInfo(validTime, inputInfo) // Create the BlockRDD createBlockRDD(validTime, blockInfos) } } Some(blockRDD) }
1.1.3. 生成
RDD主要分為以下三個過程:InputStream -> TransFormationStream -> OutputStream
1.1.3.1. InputStream
inputstream包括FileInputStream,KafkaInputStream等等
1.1.3.1.1. FileInputStream
FileInputStream的生成步驟:

-
找到新產生的檔案:val newFiles = findNewFiles(validTime.milliseconds)
-
將newFiles轉換為RDDs:val rdds=filesToRDD(newFiles)
2.1. 遍歷檔案列表獲取生成RDD: val fileRDDs=files.map(file=>newAPIHadoop(file))
2.2. 將每個檔案的RDD進行合併並返回:return new UnionRDD(fileRDDs)
- 返回生成的rdds
1.1.3.2. TransformationStream

RDD的轉換實現:
- 獲取parent DStream:val parentDs=parent.getOrCompute(validTime)
- 執行轉換函式並返回轉換結果:return parentDs.map(mapFunc)
轉換類的DStream實現特點:
-
傳入parent DStream和轉換函式
-
compute方法中從parent DStream中獲取DStream並對其作用轉換函式
private[streaming]
class MappedDStream[T: ClassTag, U: ClassTag] (
parent: DStream[T],
mapFunc: T => U
) extends DStream[U](parent.ssc) {
override def dependencies: List[DStream[_]] = List(parent)
override def slideDuration: Duration = parent.slideDuration
override def compute(validTime: Time): Option[RDD[U]] = {
parent.getOrCompute(validTime).map(_.map[U](mapFunc))
}
}
不同DStream的getOrCompute方法實現:
- FilteredDStream:
parent.getOrCompute(validTime).map(_.filter(filterFunc) - FlatMapValuedDStream:
parent.getOrCompute(validTime).map(_.flatMapValues[U](flatMapValueFunc) - MappedDStream:
parent.getOrCompute(validTime).map(_.map[U](mapFunc))
在最開始, DStream 的 transformation 的 API 設計與 RDD 的 transformation 設計保持了一致,就使得,每一個 dStreamA.transformation() 得到的新 dStreamB 能將 dStreamA.transformation() 操作完美複製為每個 batch 的 rddA.transformation() 操作。這也就是 DStream 能夠作為 RDD 模板,在每個 batch 裡實例化 RDD 的根本原因。
1.1.3.3. OutputDStream
OutputDStream的操作最後都轉換到ForEachDStream(),ForeachDStream中會生成Job並返回。
虛擬碼
def generateJob(time:Time){
val jobFunc=()=>crateRDD{
foreachFunc(rdd,time)
}
Some(new Job(time,jobFunc))
}
原始碼
private[streaming]
class ForEachDStream[T: ClassTag] (
parent: DStream[T],
foreachFunc: (RDD[T], Time) => Unit
) extends DStream[Unit](parent.ssc) {
override def dependencies: List[DStream[_]] = List(parent)
override def slideDuration: Duration = parent.slideDuration
override def compute(validTime: Time): Option[RDD[Unit]] = None
override def generateJob(time: Time): Option[Job] = {
parent.getOrCompute(time) match {
case Some(rdd) =>
val jobFunc = () => createRDDWithLocalProperties(time) {
ssc.sparkContext.setCallSite(creationSite)
foreachFunc(rdd, time)
}
Some(new Job(time, jobFunc))
case None => None
}
}
}
通過對output stream節點進行遍歷,就可以得到所有上游依賴的DStream,直至找到沒有父依賴的inputStream。
1.2. 特徵
DStream基本屬性:
-
父依賴: dependencies: List[DStream[_]]
-
時間間隔:slideDuration:Duration
-
生成RDD的函式:compute
1.3. 實現類
DStream的實現類可分為三種:輸入,轉換和輸出
DStream之間的轉換類似於RDD之間的轉換,對於wordCount的例子,實現程式碼:
val lines=ssc.socketTextStream(ip,port)
val worlds=lines.flatMap(_.split("_"))
val pairs=words.map(word=>(word,1))
val wordCounts=pairs.reduceByKey(_+_)
wordCounts.print()
每個函式的返回物件用具體實現代替:
val lines=new SocketInputDStream(ip,port)
val words=new FlatMappedDStream(lines,_.split("_"))
val pairs=new MappedDStream(words,word=>(word,1))
val wordCounts=new ShuffledDStream(pairs,_+_)
new ForeachDStream(wordCounts,cnt=>cnt.print())
1.3.1. ForeachDStream
DStream的實現分為兩種,transformation和output
不同的轉換操作有其對應的DStream實現,所有的output操作只對應於ForeachDStream
1.3.2. Transformed DStream
1.3.3. InputDStream
2. DStreamGraph
2.1 DAG分類
-
邏輯DAG: 通過transformation操作正向生成
-
物理DAG: 惰性求值的原因,在遇到output操作時根據dependency逆向寬度優先遍歷求值。
2.2 DAG生成
DStreamGraph屬性
inputStreams=new ArrayBuffer[InputDStream[_]]()
outputStreams=new ArrayBuffer[DStream[_]]()
DAG實現過程
通過對output stream節點進行遍歷,就可以得到所有上游依賴的DStream,直至找到沒有父依賴的inputStream。
sparkStreaming 記錄整個DStream DAG的方式就是通過一個DStreamGraph 例項記錄了到所有output stream節點的引用
generateJobs
def generateJobs(time: Time): Seq[Job] = {
val jobs = this.synchronized {
outputStreams.flatMap {
outputStream =>
val jobOption =
// 呼叫了foreachDStream來生成每個job
outputStream.generateJob(time) jobOption.foreach(_.setCallSite(outputStream.creationSite))
jobOption
}
}
// 返回生成的Job列表
jobs
}
腦圖製作參考:https://github.com/lw-lin/CoolplaySpark
完整腦圖連結地址:https://sustblog.oss-cn-beijing.aliyuncs.com/blog/2018/spark/srccode/spark-streaming-all.png
{kind=link}