
tensorflow實現CIFAR-10圖片的分類
本篇文章主要是利用tensorflow來構建卷積神經網路,利用CIFAR-10資料集來實現圖片的分類。資料集主要包括10類不同的圖片,一共有60000張圖片,50000張圖片作為訓練集,10000張圖片作為測試集,每張圖片的大小為32×32×3(彩色圖片)。

在構建CIFAR-10卷積神經網路中,採用了幾個trick,對權重進行正則化、資料增強、和LRN層來提高模型的效能和泛化能力。
一、下載資料
通過tensorflow官方提供的cifar10來下載CIFAR-10資料
#下載解壓資料
cifar10.maybe_download_and_extract()二、權重的正則化
對於權重的初始化,還是採用截斷的正態分佈來隨機初始化卷積和的權重。在權重初始化的時候,會給權重增加一個L2的損失,相當於做了一個L2的正則化處理。在建立模型的時候,無論是迴歸還是分類,都有可能因為特徵過多而導致模型過擬合,通常可以通過減少特徵或者懲罰不重要的特徵的權重來降低模型的過擬合。然而,我們並不知道那些權重是不重要的,通過正則化可以將權重也作為損失函式的一部分,當我們在使用某個特徵的同時也要增加損失函式,如果在增加這個特徵的權重還不足以抵消它帶來的損失,演算法就會自動降低這部分特徵的權重來減少損失,這樣我們就能給篩選出重要的特徵。L2正則化會讓權重的值不會太大,趨於0。L1正則化會產生稀疏特徵,即大部分的無用特徵都會被至為0。
下面通過tensorflow來實現對權重的L2正則化,通過設定引數w2來決定特徵帶來損失的大小
''' 初始化權重函式 ''' def variable_with_weight_loss(shape,std,w1): var = tf.Variable(tf.truncated_normal(shape,stddev=std),dtype=tf.float32) if w1 is not None: weight_loss = tf.multiply(tf.nn.l2_loss(var),w1,name="weight_loss") tf.add_to_collection("losses",weight_loss) return var
三、資料增強
利用工具類cifar10_input來進行資料增強,對32×32的圖片進行隨機裁剪、翻轉、對比度、亮度的設定,裁剪後的圖片由32×32變成了28 ×28,所以後面在設定卷積神經網路的時候,輸入圖片的大小為28×28×3。在進行資料增強的時候需要消耗大量的CPU,在distorted_inputs內部使用了16個獨立的執行緒來加速任務,函式內部會產生執行緒池,在需要使用的時候會通過TensorFlow queue來排程。
在進行測試的時候,通過裁剪圖片的中間部分,將32×32的圖片轉變成為28×28之後才能預測圖片的類別。
#獲取資料增強後的訓練集資料 images_train,labels_train = cifar10_input.distorted_inputs(cifar10_dir,batch_size) #獲取資料裁剪後的測試資料 images_test,labels_test = cifar10_input.inputs(eval_data=True,data_dir=cifar10_dir ,batch_size=batch_size)
四、卷積神經網路
整個卷積神經網路主要由兩層卷積層和三層全連線層所組成,最後模型在測試集上的top1準確率可以達到80%。
1、第一層卷積層
第一層卷積是由64個5×5的卷積核組成,步長為1,padding為SAME使得卷積之後的圖片輸入和輸出的大小保持一致。將卷積之後的結果加上偏置,然後在通過RELU啟用函式,再經過最大池化,需要注意的是採用的是池化的核為3×3,步長為2×2,池化的尺寸和步長不一致目的是為了增加資料的豐富性。最後再經過Lrn層,LRN層模仿了生物神經系統的“側抑制”機制,對於區域性神經元的活動建立競爭環境,使得其中響應較大的值變得更大,並抑制反饋較小的神經元,提高了模型的泛化能力。Relu啟用函式是沒有邊界的,所以lrn層對於沒有邊界的啟用函式會比較有用,它會從多個卷積核的響應中挑選比較大的反饋。對於有固定邊界且能抑制過大值的啟用函式sigmoid不太適應。
#設計第一層卷積
weight1 = variable_with_weight_loss(shape=[5,5,3,64],std=5e-2,w1=0)
kernel1 = tf.nn.conv2d(image_holder,weight1,[1,1,1,1],padding="SAME")
bais1 = tf.Variable(tf.constant(0.0,dtype=tf.float32,shape=[64]))
conv1 = tf.nn.relu(tf.nn.bias_add(kernel1,bais1))
pool1 = tf.nn.max_pool(conv1,[1,3,3,1],[1,2,2,1],padding="SAME"),
norm1 = tf.nn.lrn(pool1,4,bias=1.0,alpha=0.001 / 9,beta=0.75)2、第二層卷積層
第二層卷積與第一層卷積的總體結構相差不大,相對於第一層卷積,第二層將lrn層和最大池化層的順序進行了調換,先通過lrn層之後,再使用最大池化。
#設計第二層卷積
weight2 = variable_with_weight_loss(shape=[5,5,64,64],std=5e-2,w1=0)
kernel2 = tf.nn.conv2d(norm1,weight2,[1,1,1,1],padding="SAME")
bais2 = tf.Variable(tf.constant(0.1,dtype=tf.float32,shape=[64]))
conv2 = tf.nn.relu(tf.nn.bias_add(kernel2,bais2))
norm2 = tf.nn.lrn(conv2,4,bias=1.0,alpha=0.01 / 9,beta=0.75)
pool2 = tf.nn.max_pool(norm2,[1,3,3,1],[1,2,2,1],padding="SAME")3、第三層全連線層
在進行全連線操作之前,需要先將卷積後的圖片進行flatten,將圖片變成一個行向量,一行代表一張圖片,所有有bath_size行。在這一層全連線中對權重使用L2正則化,正則化的係數為0.004。通過relu啟用函式之後輸出一個384維的向量。
#第一層全連線層
reshape = tf.reshape(pool2,[batch_size,-1])
dim = reshape.get_shape()[1].value
weight3 = variable_with_weight_loss([dim,384],std=0.04,w1=0.004)
bais3 = tf.Variable(tf.constant(0.1,shape=[384],dtype=tf.float32))
local3 = tf.nn.relu(tf.matmul(reshape,weight3)+bais3)
4、第四層全連線層
這一層全連線層和上一層差不多,將輸入的384維向量變成了192維向量的輸出,也使用了L2正則化。
#第二層全連線層
weight4 = variable_with_weight_loss([384,192],std=0.04,w1=0.004)
bais4 = tf.Variable(tf.constant(0.1,shape=[192],dtype=tf.float32))
local4 = tf.nn.relu(tf.matmul(local3,weight4)+bais4)5、第五層全連線層
這一層將192維的向量轉變為10維向量的輸出,代表著十個不同種類的圖片,輸出的並沒有經過softmax。
#最後一層
weight5 = variable_with_weight_loss([192,10],std=1/192.0,w1=0)
bais5 = tf.Variable(tf.constant(0.0,shape=[10],dtype=tf.float32))
logits = tf.add(tf.matmul(local4,weight5),bais5)6、損失函式的計算
使用交叉熵作為損失函式,在這裡我們通過sparse_softmax_cross_entropy_with_logits來實現softmax和交叉熵的計算。最後還需要加上之前的權重的損失作為最後總的損失函式進行優化。
'''
損失函式
'''
def loss_func(logits,labels):
labels = tf.cast(labels,tf.int32)
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits,
labels=labels,name="cross_entropy_per_example")
cross_entropy_mean = tf.reduce_mean(tf.reduce_sum(cross_entropy))
tf.add_to_collection("losses",cross_entropy_mean)
return tf.add_n(tf.get_collection("losses"),name="total_loss")7、訓練和預測
在訓練的過程中,會輸出每秒能夠處理多少圖片,每迭代1000次輸出一次損失值。需要注意的是,在進行預測的時候需要將測試集分成一塊一塊batch_size大小的圖片進行預測,統計top1準確率,最後計算出top1的平均值,top1是指分類準確率最高的那類圖片。
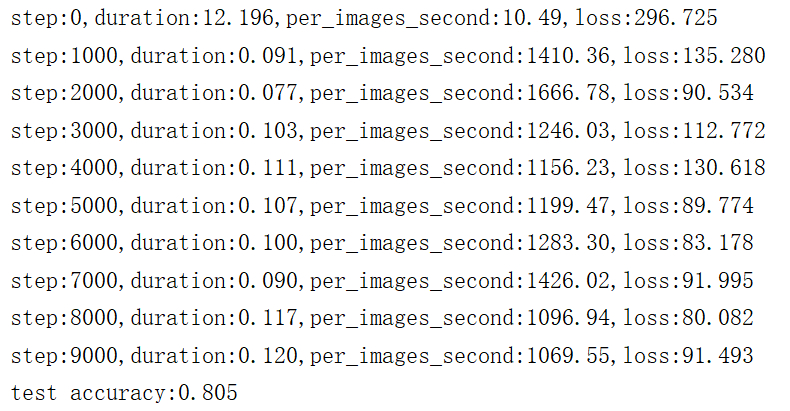
迭代10000次後的準確率可以達到80%,如果還想提高準確率,可以增加迭代的次數,然後在降低學習率。
相關推薦
tensorflow實現CIFAR-10圖片的分類
本篇文章主要是利用tensorflow來構建卷積神經網路,利用CIFAR-10資料集來實現圖片的分類。資料集主要包括10類不同的圖片,一共有60000張圖片,50000張圖片作為訓練集,10000張圖片作為測試集,每張圖片的大小為32×32×3(彩色圖片)。在構建CIFAR-
Tensorflow使用Inception思想實現CIFAR-10十分類demo
使用Inception思想實現一個簡單的CIFAR-10十分類.最主要的是領會Inception的結構. Inception結構圖如下: 思想: 分別使用1*1,3*3,5*5卷積核和一個3*3最大池化層對上一層進行處理,然後將輸入進行合併.
Tensorflow使用Resnet思想實現CIFAR-10十分類demo
關於Resnet殘差網路的介紹已經非常多了,這裡就不在贅述.使用Tensorflow寫了一個簡單的Resnet,對CIFAR-10資料集進行十分類.關鍵步驟都寫了詳細註釋,雖然最後的精度不高,但還是學習Resnet的思想為主. import tensorf
Tensorflow實現CIFAR-10分類問題-詳解四cifar10_eval.py
最後我們採用cifar10_eval.py檔案來評估以下訓練模型在保留(hold-out samples)樣本下的表現力,其中保留樣本的容量為10000。為了驗證模型在訓練過程中的表現能力的變化情況,我們驗證了最近一些訓練過程中產生的checkpoint fil
Tensorflow實現CIFAR-10分類問題-詳解二cifar10.py
上一篇cifar1_train.py主要呼叫的都是cifar10.py這個檔案中的函式。我們來看cifar10.py,網路結構也主要包含在這個檔案當中,整個訓練圖包含765個操作(operations),cifar10.py圖主要有三個模組組成: Model
Pytorch實戰2:ResNet-18實現Cifar-10影象分類(測試集分類準確率95.170%)(轉)
Pytorch實戰2:ResNet-18實現Cifar-10影象分類 實驗環境: torchvision 0.2.1 Python 3.6 CUDA8+cuDNN v7 (可選) Win10+Pycharm 整個專案程式碼:點選這裡 Res
用KNN演算法分類CIFAR-10圖片資料
KNN分類CIFAR-10,並且做Cross Validation,CIDAR-10資料庫資料如下: knn.py : 主要的試驗流程 from cs231n.data_utils import load_CIFAR10 from cs231n.classifiers i
Tensorflow官網CIFAR-10資料分類教程程式碼詳解
標題 概述 對CIFAR-10 資料集的分類是機器學習中一個公開的基準測試問題,本教程程式碼通過解決CIFAR-10資料分類任務,介紹了Tensorflow的一些高階用法,演示了構建大型複雜模型的一些重要技巧,著重於建立一個規範的網路組織結構,訓練並進行評估,為建立更大規模更加複雜的
cifar-10 圖片可視化
adl odi 對象 shape ret plt rgb ray cnblogs 保存cifar-10 數據集 圖片 python3 #用於將cifar10的數據可視化 import pickle as p import numpy as np import matplo
Cifar-10影象分類任務
Cifar-10資料集 Cifar-10資料集是由10類32*32的彩色圖片組成的資料集,一共有60000張圖片,每類包含6000張圖片。其中50000張是訓練集,1000張是測試集。 1. 獲取每個batch檔案中的字典資訊 import pickle def u
一步一步使用Tensorflow實現LSTM對mnist分類
一步一步使用Tensorflow實現LSTM對mnist分類 標籤: LSTM Tensorflow 關於RNN或者LSTM的介紹可以看這裡 讀入資料集以及定義超引數 import tensorflow as tf from tensorflow.examples.
Tensorflow實現的CNN文字分類
翻譯自部落格:IMPLEMENTING A CNN FOR TEXT CLASSIFICATION IN TENSORFLOW 在這篇文章中,我們將實現一個類似於Kim Yoon的卷積神經網路語句分類的模型。 本文提出的模型在一系列文字分類任務(如情感分析
計算機視覺(四):使用K-NN分類器對CIFAR-10進行分類
1 - 引言 之前我們學習了KNN分類器的原理,現在讓我們將KNN分類器應用在計算機視覺中,學習如何使用這個演算法來進行圖片分類。 2 - 準備工作 建立專案結構如圖所示 在datasets檔案中下載資料集Cifar-10 k_nearest_neighbo
【Tensorflow】Cifar-10
tensorflow官方CIFAR-10 教程學習筆記 主要包括以下四部分: 環境: python 3.6 tensorflow 1.8 目錄 完整程式碼: 完整程式碼: cifar10 tf.app.flags.DEFINE_xx
Tensorflow實現簡單的影象分類器
一個簡單的Tensorflow圖片分類器,資料集是iris資料集。兩個指令碼premade_estimator.py分類器指令碼、iris_data.py處理資料的指令碼。 #iris_data.py 下載資料集,並且處理資料集 import pand
深度學習小白——tensorflow(四)CIFAR-10例項
一、資料讀取 因為之前寫過,見http://blog.csdn.net/margretwg/article/details/70168256,這裡就不重複了 二、模型建立 全域性引數 import os import re import sys import tar
KNN實現CIFAR-10資料集識別
KNN缺點:每個測試樣本都要迴圈一遍訓練樣本。 該資料集由5個data_batch和一個test_batch構成,測試程式碼 import pickle import numpy as np fo=open('./datasets/cifar-10-batch
[keras實戰] 小型CNN實現Cifar-10資料集84%準確率
實驗環境 程式碼基於python2.7, Keras1(部分介面在Keras2中已經被修改,如果你使用的是Keras2請查閱文件修改介面) 個人使用的是蟲資料提供的免費GPU主機,GTX1080顯示卡,因為是免費賬號,所以視訊記憶體最高只有1G。為了防止超視
tensorflow下實現ResNet網路對資料集cifar-10的影象分類
DenseNet傳送門:DenseNet先來簡單講講ResNet的網路結構。ResNet的出現是為了解決深度網路中由於層數太多,導致的degradation problem(退化問題),作者在原論文中對比了較為“耿直”的深度卷積網路(例如以VGG為原型,不斷加深層數)在不同層
深度學習之TensorFlow使用CNN測試Cifar-10資料集(Python實現)
題目描述: 1. 對Cifar-10影象資料集,用卷積神經網路進行分類,統計正確率。 2.選用Caffe, Tensorflow, Pytorch等開 源深度學習框架之一,學會安裝這些框架並呼叫它們的介面。 3.直接採用這些深度學習框架針對Cifar-10資料集已訓練好的網路模型,只