
深度學習:transformer模型
Google於2017年6月釋出在arxiv上的一篇文章《Attention is all you need》,提出解決sequence to sequence問題的transformer模型,用全attention的結構代替了lstm,拋棄了之前傳統的encoder-decoder模型必須結合cnn或者rnn的固有模式,只用attention,可謂大道至簡。文章的主要目的是在減少計算量和提高並行效率的同時不損害最終的實驗結果,創新之處在於提出了兩個新的Attention機制,分別叫做 Scaled Dot-Product Attention 和 Multi-Head Attention。
transformer模型結構
模型結構如下圖:

和大多數seq2seq模型一樣,transformer的結構也是由encoder和decoder組成。
Encoder
Encoder由Nx個相同的layer組成,layer指的就是上圖左側的單元,最左邊有個“Nx”,論文中是6x個。每個Layer由兩個sub-layer組成,分別是multi-head self-attention mechanism和fully connected feed-forward network。其中每個sub-layer都加了residual connection和normalisation,因此可以將sub-layer的輸出表示為:
multi-head self-attention mechanism和fully connected feed-forward network兩個sub-layer的解釋。
Multi-head self-attention
attention可由以下形式表示[深度學習:注意力模型Attention Model:Attention機制的本質]:
Note: 與之前的模型對應起來的話,Q就是decoder的隱層(如 或者si) ,K就是encoder的隱層(如
),V也是encoder的隱層。encoder中沒有預測的輸入,所有使用的是self-attention,取Q,K,V相同,均為encoder的隱層。
multi-head attention則是通過h個不同的線性變換對Q,K,V進行投影,最後將不同的attention結果拼接起來(很像cnn的思想):
文章中attention的計算採用了scaled dot-product,即:
作者同樣提到了另一種複雜度相似但計算方法additive attention,在 很小的時候和dot-product結果相似,
大的時候,如果不進行縮放則表現更好,但dot-product的計算速度更快,進行縮放後可減少影響(由於softmax使梯度過小)。點乘注意力機制對於加法注意力而言,更快,同時更節省空間。
Note:scaled dot-product有效的解釋:Transformer所使用的注意力機制的核心思想是去計算一句話中的每個詞對於這句話中所有詞的相互關係,然後認為這些詞與詞之間的相互關係在一定程度上反應了這句話中不同詞之間的關聯性以及重要程度。因此再利用這些相互關係來調整每個詞的重要性(權重)就可以獲得每個詞新的表達。這個新的表徵不但蘊含了該詞本身,還蘊含了其他詞與這個詞的關係,因此和單純的詞向量相比是一個更加全域性的表達。
Transformer通過對輸入的文字不斷進行這樣的注意力機制層和普通的非線性層交疊來得到最終的文字表達。
Position-wise feed-forward networks
位置全連結前饋網路——MLP變形。第二個sub-layer是個全連線層,之所以是position-wise是因為處理的attention輸出是某一個位置i的attention輸出。用了兩層Dense層,activation用的都是Relu。可以看成是兩層的1*1的1d-convolution。hidden_size變化為:512->2048->512。
Position-wise feed forward network,其實就是一個MLP 網路,1 的輸出中,每個 d_model 維向量 x 在此先由 xW_1+b_1 變為 d_f $維的 x',再經過max(0,x')W_2+b_2 迴歸 d_model 維。之後再是一個residual connection。輸出 size 仍是 $[sequence_length, d_model]$。
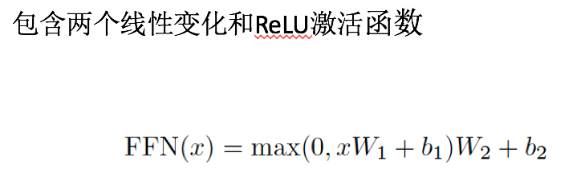
Decoder
Decoder和Encoder的結構差不多,但是多了一個attention的sub-layer。
對應上圖先明確一下decoder的輸入輸出和解碼過程:
- 輸出:對應i位置的輸出詞的概率分佈
- 輸入:encoder的輸出 & 對應i-1位置decoder的輸出。所以中間的attention不是self-attention,它的K,V來自encoder,Q來自上一位置decoder的輸出
- 解碼:編碼可以平行計算,一次性全部encoding出來,但解碼不是一次把所有序列解出來的,而是像rnn一樣一個一個解出來的,因為要用上一個位置的輸入當作attention的query
對於decoder中的第一個多頭注意力子層,需要新增masking,確保預測位置i的時候僅僅依賴於位置小於i的輸出,因為訓練時的output都是ground truth,這樣可以確保預測第i個位置時不會接觸到未來的資訊。通過一個深層轉換『Transformer』編碼器進行輸入,隨後使用對應於遮蓋處的最終隱態『final hidden states』對遮蓋詞進行預測,正如我們訓練一個語言模型一樣。
加了mask的attention原理如圖(另附multi-head attention(多頭注意力機制——點乘注意力的升級版本)):

Positional Encoding
除了主要的Encoder和Decoder,還有資料預處理的部分。Transformer拋棄了RNN,而RNN最大的優點就是在時間序列上對資料的抽象,所以文章中作者提出兩種Positional Encoding的方法,將Positional Encoding後的資料與輸入embedding資料求和,加入了相對位置資訊。
兩種Positional Encoding方法:
- 用不同頻率的sine和cosine函式直接計算
- 學習出一份positional embedding(參考文獻)
經過實驗發現兩者的結果一樣,所以最後選擇了第一種方法,公式如下:
方法1的好處有兩點:
- 任意位置的
都可以被
的線性函式表示。由於三角函式有如下特性:
2. 如果是學習到的positional embedding,可能會像詞向量一樣受限於詞典大小。也就是隻能學習到“位置2對應的向量是(1,1,1,2)”這樣的表示。所以用三角公式明顯不受序列長度的限制,也就是可以對 比所遇到序列的更長的序列 進行表示。
Reddit上作者Jacob的介紹
(原帖連結)
The basic idea is very simple. For several years, people have been getting very good results "pre-training" DNNs as a language model and then fine-tuning on some downstream NLP task (question answering, natural language inference, sentiment analysis, etc.).
Language models are typically left-to-right, e.g.:
"the man went to a store"
P(the | <s>)*P(man|<s> the)*P(went|<s> the man)*...
The problem is that for the downstream task you usually don't want a language model, you want a the best possible contextual representation of each word. If each word can only see context to its left, clearly a lot is missing. So one trick that people have done is to also train a right-to-left model, e.g.:
P(store|</s>)*P(a|store </s>)*...
Now you have two representations of each word, one left-to-right and one right-to-left, and you can concatenate them together for your downstream task.
But intuitively, it would be much better if we could train a single model that was deeply bidirectional.
It's unfortunately impossible to train a deep bidirectional model like a normal LM, because that would create cycles where words can indirectly "see themselves," and the predictions become trivial.
What we can do instead is the very simple trick that's used in de-noising auto-encoders, where we mask some percent of words from the input and have to reconstruct those words from context. We call this a "masked LM" but it is often called a Cloze task.
Task 1: Masked LM
Input:
the man [MASK1] to [MASK2] store
Label:
[MASK1] = went; [MASK2] = store
In particular, we feed the input through a deep Transformer encoder and then use the final hidden states corresponding to the masked positions to predict what word was masked, exactly like we would train a language model.
The other thing that's missing from an LM is that it doesn't understand relationships between sentences, which is important for many NLP tasks. To pre-train a sentence relationship model, we use a very simple binary classification task, which is to concatenate two sentences A and B and predict whether B actually comes after A in the original text.
Task 2: Next Sentence Prediction
Input:
the man went to the store [SEP] he bought a gallon of milk
Label:
IsNext
Input:
the man went to the store [SEP] penguins are flightless birds
Label:
NotNext
Then we just train a very big model for a lot of steps on a lot of text (we used Wikipedia + a collection of free ebooks that some NLP researchers released publicly last year). To adapt to some downstream task, you just fine-tune the model on the labels from that task for a few epochs.
By doing this we got pretty huge improvements over SOTA on every NLP task that we tried, with almost task-specific no changes to our model needed.
But for us the really amazing and unexpected result is that when we go from a big model (12 Transformer blocks, 768-hidden, 110M parameters) to a really big model (24 Transformer blocks, 1024-hidden, 340M parameters), we get huge improvements even on very small datasets (small == less than 5,000 labeled examples).
BERT有哪些“反直覺”的設定?
ELMO的設定其實是最符合直覺的預訓練套路,兩個方向的語言模型剛好可以用來預訓練一個BiLSTM,非常容易理解。但是受限於LSTM的能力,無法變深了。那如何用transformer在無標註資料行來做一個預訓練模型呢?一個最容易想到的方式就是GPT的方式,事實證明效果也不錯。那還有沒有“更好”的方式?直觀上是沒有了。而BERT就用了兩個反直覺的手段來找到了一個方法。
(1) 用比語言模型更簡單的任務來做預訓練。直覺上,要做更深的模型,需要設定一個比語言模型更難的任務,而BERT則選擇了兩個看起來更簡單的任務:完形填空和句對預測。
(2) 完形填空任務在直觀上很難作為其它任務的預訓練任務。在完形填空任務中,需要mask掉一些詞,這樣預訓練出來的模型是有缺陷的,因為在其它任務中不能mask掉這些詞。而BERT通過隨機的方式來解決了這個缺陷:80%加Mask,10%用其它詞隨機替換,10%保留原詞。這樣模型就具備了遷移能力。
感覺上,作者Jacob Devlin是拿著錘子找釘子。既然transformer已經證明了是可以handle大資料,那麼就給它設計一種有大資料的任務,即使是“簡單”任務也行。理論上BiLSTM也可以完成BERT裡的兩個任務,但是在大資料上BERT更有優勢。
BERT這個模型與AI2的 ELMo和OpenAI的fine-tune transformer的區別是
- 它在訓練雙向語言模型時以減小的概率把少量的詞替成了Mask或者另一個隨機的詞。我個人感覺這個目的在於使模型被迫增加對上下文的記憶。至於這個概率,我猜是Jacob拍腦袋隨便設的。
- 增加了一個預測下一句的loss。
Transformer模型的評價
優點
作者主要講了以下三點:
-
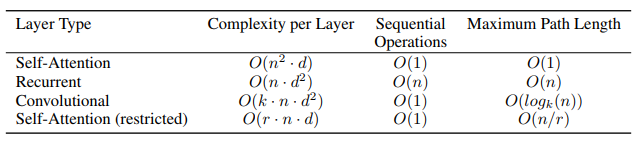
Total computational complexity per layer (每層計算複雜度)
2. Amount of computation that can be parallelized, as mesured by the minimum number of sequential operations required
作者用最小的序列化運算來測量可以被並行化的計算。也就是說對於某個序列 ,self-attention可以直接計算
的點乘結果,而rnn就必須按照順序從
計算到
3. Path length between long-range dependencies in the network
這裡Path length指的是要計算一個序列長度為n的資訊要經過的路徑長度。cnn需要增加捲積層數來擴大視野,rnn需要從1到n逐個進行計算,而self-attention只需要一步矩陣計算就可以。所以也可以看出,self-attention可以比rnn更好地解決長時依賴問題。當然如果計算量太大,比如序列長度n>序列維度d這種情況,也可以用視窗限制self-attention的計算數量
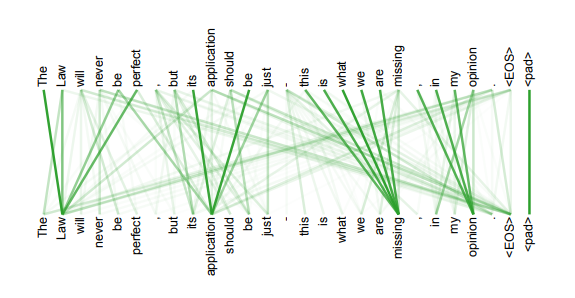
4. 另外,從作者在附錄中給出的栗子可以看出,self-attention模型更可解釋,attention結果的分佈表明了該模型學習到了一些語法和語義資訊
缺點
缺點在原文中沒有提到,是後來在Universal Transformers中指出的,在這裡加一下吧,主要是兩點:
- 實踐上:有些rnn輕易可以解決的問題transformer沒做到,比如複製string,尤其是碰到比訓練時的sequence更長的時
- 理論上:transformers非computationally universal(圖靈完備),(我認為)因為無法實現“while”迴圈
from: http://blog.csdn.net/pipisorry/
ref: