
深度學習:語言模型的評估標準
語言模型的評估主要measure the closeness,即生成語言和真實語言的近似度。
Classification accuracy
provides additional information about the power of a model, even if it is not being designed explicitly for text classification. [Jaech, et al. "Low-Rank RNN Adaptation for Context-Aware Language Modeling." arXiv 2017]Perplexity
perplexity is the geometric mean of the inverse probability for each predicted word.
For fair comparison, when computing the perplexity with the 5-gram LM, exclude all test words marked as 〈unk〉 (i.e., with low counts or OOVs) from consideration.
Meteor
[S. Banerjee and A. Lavie, “Meteor: An automatic metric for MT evaluation with improved correlation with human judgments,” in Proc. ACL Workshop Intrinsic Extrinsic Eval. Measures Mach. Transl. Summarization]
ROUGE
is a recall-oriented measure widely used in the summarization literature. It measures the n-gram recall between the candidate text and the reference text(s).
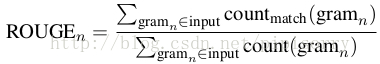
where count match denotes the number of n-grams co-occurring in the input and output.
一般ROUGE-1, 2 and W (based on weighted longest common subsequence).
[C.-Y. Lin, “Rouge: A package for automatic evaluation of summaries,” in Proc. ACL Workshop Text Summarization Branches Out, 2004]
Blue
a form of precision of word n-grams between generated and reference sentences.Purely measuring recall will inappropriately reward long outputs. BLEU is designed to address such an issue by emphasizing precision.
n-gram precision scores are given by:
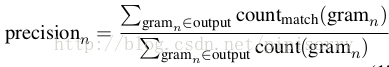
BLEU then combines the average logarithm of precision scores with exceeded length penalization.
most previous work report BLEU-1, i.e., they only compute precision at the unigram level, whereas BLEU-n is a geometric average of precision over 1- to n-grams.
[K. Papineni, S. Roukos, T. Ward, and W. J. Zhu, “BLEU: A method for automatic evaluation of machine translation,” ACL2002]
Coherence Evaluation
Neither BLEU nor ROUGE attempts to evaluate true coherence. There is no generally accepted and readily available coherence evaluation metric. simple approximations like number of overlapped tokens or topic distribution similarity (e.g., (Yan et al., 2011b; Yan et al., 2011a; Celikyilmaz and Hakkani-Tür, 2011)). [Li, Jiwei, et al. "A hierarchical neural autoencoder for paragraphs and documents." ACL2015] Cider
it measures consistency between n-gram occurrences in generated and reference sentences, where this consistency is weighted by n-gram saliency and rarity.
不同評估方法的缺點討論亦可參考[Vedantam, R., Lawrence Zitnick, C., & Parikh, D. Cider: Consensus-based image description evaluation. CVPR2015]
人工評估
ask for raters to give a subjective score
使用Amazon Mechanical Turk
如imge caption中following the guidelines proposed in [M. Hodosh, P. Young, and J. Hockenmaier, “Framing image description as a ranking task: Data, models and evaluation metrics,” J. Artif. Intell. Res.2013]
或者[Jaech, et al "Low-Rank RNN Adaptation for Context-Aware Language Modeling." arXiv2017]
ref: [Vinyals, O., Toshev, A., Bengio, S., & Erhan, D. Show and tell: Lessons learned from the 2015 mscoco image captioning challenge. TPAMI2017]
[Hoang, et al "Incorporating Side Information into Recurrent Neural Network Language Models." NAACL2016]
相關推薦
深度學習:語言模型的評估標準
語言模型的評估主要measure the closeness,即生成語言和真實語言的近似度。 Classification accuracy provides additional information about the
深度學習-自然語言模型隨記
為什麼要研究深度學習? 語言模型 看概率! n-gram 一行一行看,比如第一行,i後面接i的出現次數,i後面接want的出現次數。 上面表表示詞後面接某詞的次數,下面表表示詞後面接某詞的概率。
深度學習:transformer模型
Google於2017年6月釋出在arxiv上的一篇文章《Attention is all you need》,提出解決sequence to sequence問題的transformer模型,用全attention的結構代替了lstm,拋棄了之前傳統的encoder-decoder模型必須結合
【深度學習】深度學習分類與模型評估
內容大綱 分類和迴歸之外的機器學習形式 評估機器學習模型的規範流程 為深度學習準備資料 特徵工程 解決過擬合問題 處理機器學習問題的通用流程 監督學習的主要種類及其變種 主要包括兩大類問題: 分類 迴歸
深度學習:Seq2seq模型
Encoder-Decoder模型和Attention模型。 seq2seq是什麼?簡單的說,就是根據一個輸入序列x,來生成另一個輸出序列y。seq2seq有很多的應用,例如翻譯,文件摘取,問答系統等等。在翻譯中,輸入序列是待翻譯的文字,輸出序列是翻譯後的文字;在問答系
深度學習常用的模型評估指標
地震 時有 就會 com 真的 con section 系統 最大的 “沒有測量,就沒有科學。”這是科學家門捷列夫的名言。在計算機科學中,特別是在機器學習的領域,對模型的測量和評估同樣至關重要。只有選擇與問題相匹配的評估方法,我們才能夠快速的發現在模
21個專案玩轉深度學習:基於TensorFlow的實踐詳解03—打造自己的影象識別模型
書籍原始碼:https://github.com/hzy46/Deep-Learning-21-Examples CNN的發展已經很多了,ImageNet引發的一系列方法,LeNet,GoogLeNet,VGGNet,ResNet每個方法都有很多版本的衍生,tensorflow中帶有封裝好各方法和網路的函式
深度學習目標檢測模型全面綜述:Faster R-CNN、R-FCN和SSD
選自medium 機器之心編輯部 Faster R-CNN、R-FCN 和 SSD 是三種目前最優且應用最廣泛的目標檢測模型,其他流行的模型通常與這三者類似。本文介紹了深度學習目標檢測的三種常見模型:Faster R-CNN、R-FCN 和 SSD。 圖為機
【自然語言處理】預測電影影評情感的深度學習詞袋模型
翻譯自外網:https://machinelearningmastery.com/deep-learning-bag-of-words-model-sentiment-analysis/ 教程概述: 1.電影評論集 2.資料準備 3.詞包表示法 4.情感分析模型 1.電
NLP學習記錄:語言模型
學習了cs224n之後,深感這門課更偏深度學習,因此僅學習這門課後NLP基礎不足,NLP領域的知識學習並不系統,基礎概念不清,感覺對於NLP領域的問題直覺不足,因此開始學習Michael Collins的NLP課程,結合此前學習的體悟寫一些綜合性的感想。
機器學習-分類模型評估標準
對模型的泛化效能進行評估,不僅需要有效可行的實驗估計方法,還需要有衡量模型泛化能力的評價標準,這就是效能度量(performance measure),迴歸任務最常用的效能度量是"均方誤差" (mean squared error)。下面主要介紹分類模型的
CCAI 2017 | 香港科技大學計算機系主任楊強:論深度學習的遷移模型
作者 | 賈維娣 7月23日,由中國人工智慧學會、阿里巴巴集團 & 螞蟻金服主辦,CSDN、中國科學院自動化研究所承辦的第三屆中國人工智慧大會(CCAI 2017)在杭州國際會議中心盛大開幕。大會第一天上午,香港科技大學計算機與工程系主任、AAAI Fellow楊強教授發表了《深度學習的遷移
機器學習模型評估標準選擇循環圖
分享 his 技術分享 選擇 sta 目標 rac 學習 code 要根據不同的目標選取合適的評估指標。 進行二分類問題的時候,數據集之間的不平衡,會導致評價指標accuracy很高,但是卻不能反應模型的好壞。
spaCy 學習 第二篇:語言模型
文本 除了 rip exc 一個 tokenize 常見 ear one spaCy處理文本的過程是模塊化的,當調用nlp處理文本時,spaCy首先將文本標記化以生成Doc對象,然後,依次在幾個不同的組件中處理Doc,這也稱為處理管道。語言模型默認的處理管道依次是:tagg
快速上手深度學習 掌握TensorFlow模型構建與開發
第5章 第6章 優勢 損失函數 學習過程 htm 項目 機器 過程 第1章 課程介紹介紹機器學習的背景,介紹tensorflow的背景,介紹課程python,numpy,virtualenv等前置學習內容,安裝tensorflow1-1 導學1-2 課程安排1-3 深度學習
《深度學習:原理與應用實踐》中文版PDF
應用 href 書籍 nag tex 原理 圖片 water images 下載:https://pan.baidu.com/s/1YljEeog_D0_RUHjV6hxGQg 《深度學習:原理與應用實踐》中文版PDF,帶目錄和書簽; 經典書籍,講解詳細; 如圖: 《深度學
使用函式 initializer 介面優化深度學習場景下模型載入的冷啟動延時
背景 深度學習場景使用函式計算典型案例 阿里雲 函式計算 客戶 碼隆科技 是一家專注於深度學習與計算機視覺技術創新的公司。當碼隆的客戶上傳大量影象資料後,需要儘快把影象按照客戶指定的方式處理,包括商品識別,紡織面料等柔性材質識別分析,內容審查,以圖搜圖等等。影象處理基於碼隆預先訓練好的深度學習模型,要求在
深度學習:YOLO系列
一、YOLO v1 (CVPR2016, oral) (You Only Look Once: Unified, Real-Time Object Detection) 可參考文章:https://zhuanlan.zhihu.com/p/27029015 Faster R-CNN的方法目前
深度學習:keras學習
Keras TensorFlow教程 :如何從零開發一個複雜深度學習模型:https://segmentfault.com/a/1190000012645225 keras概念解釋:http://www.zhiding.cn/techwalker/documents/J9UpWRDfV
深度學習:zero-shot-learning(四)_DAEZSL_2017
參考: https://www.leiphone.com/news/201810/STIq4kDL6mbIKUmH.html 論文地址:https://arxiv.org/pdf/1711.06167.pdf 問題:對映域遷移 (projection domain sh