
深度學習:Seq2seq模型
Encoder-Decoder模型和Attention模型。
seq2seq是什麼?簡單的說,就是根據一個輸入序列x,來生成另一個輸出序列y。seq2seq有很多的應用,例如翻譯,文件摘取,問答系統等等。在翻譯中,輸入序列是待翻譯的文字,輸出序列是翻譯後的文字;在問答系統中,輸入序列是提出的問題,而輸出序列是答案。
Encoder-Decoder模型
為了解決seq2seq問題,有人提出了encoder-decoder模型,也就是編碼-解碼模型。所謂編碼,就是將輸入序列轉化成一個固定長度的向量;解碼,就是將之前生成的固定向量再轉化成輸出序列。
基本的seq2seq模型包含了兩個RNN,解碼器和編碼器,最基礎的Seq2Seq模型包含了三個部分,即Encoder、Decoder以及連線兩者的中間狀態向量State Vector,Encoder通過學習輸入,將其編碼成一個固定大小的狀態向量S,繼而將S傳給Decoder,Decoder再通過對狀態向量S的學習來進行輸出。如下圖所示:
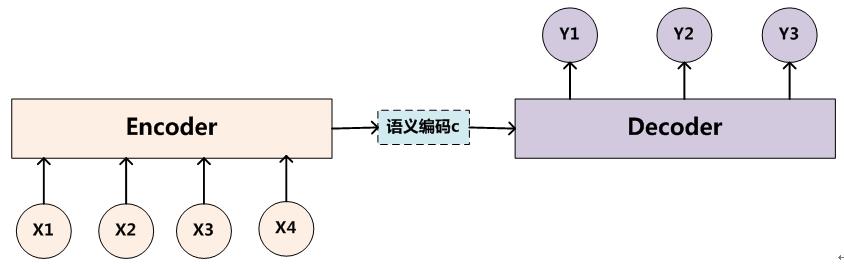

模型展開

編碼器和解碼器可以使用相同的權重,或者,更常見的是,編碼器和解碼器分別使用不同的引數。多層神經網路已經成功地用於序列序列模型之中了。
具體實現的時候,編碼器和解碼器都不是固定的,可選的有CNN/RNN/BiRNN/GRU/LSTM等等,你可以自由組合。比如說,你在編碼時使用BiRNN,解碼時使用RNN,或者在編碼時使用RNN,解碼時使用LSTM等等。每個矩形都表示著RNN的一個核,通常是GRU(Gated recurrent units)或者長短期記憶(LSTM)核。
為了方便闡述,選取編碼和解碼都是RNN的組合。
編碼encoder
在RNN中,當前時間的隱藏狀態是由上一時間的狀態和當前時間輸入決定的,也就是
ht=f(ht−1,xt)
獲得了各個時間段的隱藏層以後,再將隱藏層的資訊彙總,生成最後的語義向量
C=q(h1,h2,h3,…,hTx)
一種簡單的方法是將最後的隱藏層作為語義向量C,即
C=q(h1,h2,h3,…,hTx)=hTx
解碼decoder
解碼階段可以看做編碼的逆過程。這個階段,我們要根據給定的語義向量C和之前已經生成的輸出序列y1,y2,…yt−1來預測下一個輸出的單詞yt,即
yt=argmaxP(yt)=∏t=1Tp(yt|{y1,…,yt−1},C)
也可以寫作
yt=g({y1,…,yt−1},C)
而在RNN中,上式又可以簡化成
yt=g
其中s是輸出RNN中的隱藏層
st=f(st−1,y t−1, C)
C代表之前提過的語義向量,yt−1表示上個時間段的輸出,反過來作為這個時間段的輸入。而g則可以是一個非線性的多層的神經網路,產生詞典中各個詞語屬於yt的概率。
解碼分為訓練和推理兩個階段
注意,我們這裡將decoder分為了training和predicting,這兩個encoder實際上是共享引數的,也就是通過training decoder學得的引數,predicting會拿來進行預測。
那麼為什麼我們要分兩個呢,這裡主要考慮模型的robust。在training階段,為了能夠讓模型更加準確,我們並不會把t-1的預測輸出作為t階段的輸入,而是直接使用target data中序列的元素輸入到Encoder中。而在predict階段,我們沒有target data,有的只是t-1階段的輸出和隱層狀態。當然,predicting雖然與training是分開的,但他們是會共享引數的,training訓練好的引數會供predicting使用。
training過程
優化時,採用極大似然估計,讓seq a encode後再decode得到seq b的概率最大。
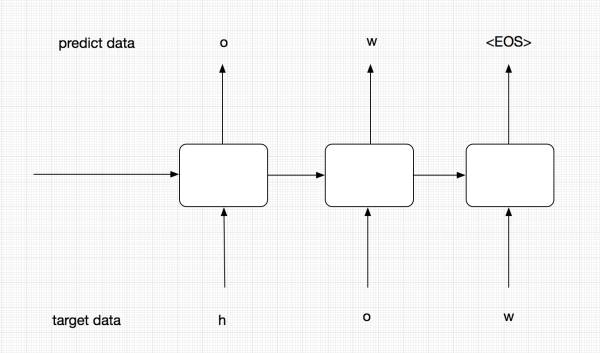
上面的圖中代表的是training過程。在training過程中,我們並不會把每個階段的預測輸出作為下一階段的輸入,下一階段的輸入我們會直接使用target data,這樣能夠保證模型更加準確。
predict階段
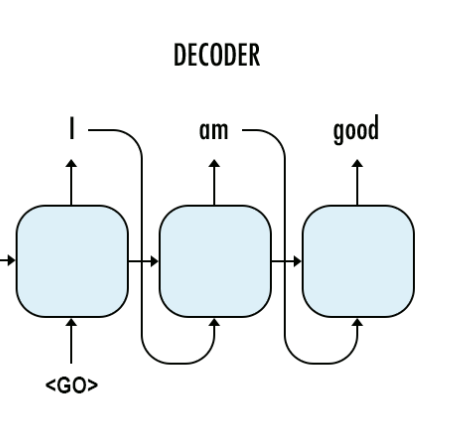
這個圖代表我們的predict階段,在這個階段,我們沒有target data,這個時候前一階段的預測結果就會作為下一階段的輸入。
解譯的過程可以被理解為運用貪心演算法(一種區域性最優解演算法,即選取一種度量標準,預設在當前狀態下進行最好的選擇)來返回對應概率最大的詞彙;
或是通過集束搜尋(Beam Search(Bahdanau, Bengio 2014),一種啟發式搜尋演算法,可以基於裝置效能給予時間允許內的最優解)在序列輸出前檢索大量的詞彙,從而得到最優的選擇;
或者通過random sample(Graves 2013)。

一個多層的seq2seq的LSTM神經網路的處理行為

encoder-decoder的侷限性
最大的侷限性就在於編碼和解碼之間的唯一聯絡就是一個固定長度的語義向量C。也就是說,編碼器要將整個序列的資訊壓縮排一個固定長度的向量中去。
這樣做有兩個弊端,一是語義向量無法完全表示整個序列的資訊,還有就是先輸入的內容攜帶的資訊會被後輸入的資訊稀釋掉,或者說,被覆蓋了。輸入序列越長,這個現象就越嚴重。這就使得在解碼的時候一開始就沒有獲得輸入序列足夠的資訊, 那麼解碼的準確度自然也就要打個折扣了。
由於基礎Seq2Seq的種種缺陷,隨後引入了Attention的概念以及Bi-directional encoder layer等。
在機器翻譯任務上,Cho等人在Decoder部分進行了改進,為Decoder RNN的每個結點添加了由Encoder端得到的上下文向量作為輸入,使得解碼過程中的每個時刻都有能力獲取到上下文資訊,從而加強了輸出序列和輸入序列的相關性(Cho Ket al. 2014)。
注意事項
bucking、填充和反轉encoder輸入
桶(bucket)的方法,這也是一種對於變長度句子翻譯的很好用的工具。當我們想從英文翻譯到法語的時候,輸入的英文的長度為L1而輸出法語的長度則為L2。而我們現在已知英文從encoder_input進入法語從decoder_input輸出(其標識有GO的字首),這樣我們就需要一個(L1,L2+1)長的seq2seq模型,來對每一對英法文進行處理.這將導致一個龐大的圖形,由許多非常相似的子圖組成。另一方面,我們可以用特殊的PAD符號來填充每個句子。那麼我們只需要一個seq2seq模型,用於填充長度。然而對於一些非常短的語句和詞彙,我們的模型將會變得低效,編碼和解碼太多的PAD填充符會變得很沒有意義。
似乎我們需要在對過短和過長句子的處理之間找到一個平衡點,我們會使用不同長度的桶,並且在桶上放置不同的句子並且填充他們至桶滿。在translate.py之中,我們會使用以下的預設長度的桶。
buckets = [(5, 10), (10, 15), (20, 25), (40, 50)]
這意味著如果輸入是具有3個令牌的英文句子,並且相應的輸出是具有6個令牌的法語句子,那麼它們將被放入第一個資料桶,並填充到編碼器輸入的長度為5,解碼器輸入的長度為10 。如果我們有一個8個令牌的英文句子,相應的法語句子有18個令牌,那麼它們將不適用於(10,15)桶,所以(20,25)桶將被使用,即英文句子被填補到20個長度,而法國一到25個長度。
請記住,當構建解碼器輸入時,我們將特殊GO符號新增到到了裡面。這是在seq2seq_model.py的get_batch()函式中完成的,其也會反轉英語的輸入。正如Sutskever所說,這有助於改善機器學習後的結果。現在有句英文I go.就會被分解為["I", "go", "."],其將作為編碼器的輸入,而輸出Je vais.則會被分解為["Je", "vais", "."]。其會被放入(5,10)的桶中。所以經過反轉並且田衝後的輸入就是[PAD PAD "." "go" "I"],而輸出則是[GO "Je" "vais" "." EOS PAD PAD PAD PAD PAD]。
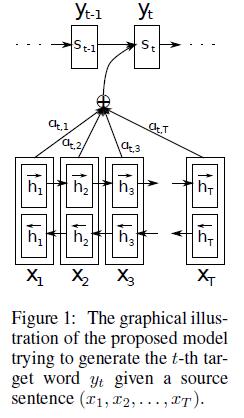
Attention模型
注意機制最早由Bahdanau等人於2014年提出,該機制存在的目的是為了解決RNN中只支援固定長度輸入的瓶頸(as sentences grow longer, the amount of information needing to be carried forward will also grow, and therefore a fixed size embedding may be insufficient)。在該機制環境下,Seq2Seq中的編碼器被替換為一個雙向迴圈網路(bidirectional RNN)。論文作者提出了一個用於翻譯任務的結構。解碼部分使用了attention模型,而在編碼部分,則使用了BiRNN(bidirectional RNN,雙向RNN)。{實際上是cho e.t.進一步的改進,attention過程類似於統計機器翻譯中的對齊過程(Bahdanau D et al. 2014)。}
我們知道每一個隱節點hi都包含了對應的輸入字元xi以及其對上下文的聯絡,這麼做意義就在於現在模型可以突破固定長度輸入的限制,根據不同的輸入長度構建不同個數的隱節點,故不論我們輸入的序列(比如待翻譯的一段原文)長度如何,都可以得到模型輸出結果。????
在注意機制中,我們的源序列x=(x1,x2,…,xt)分別被正向與反向地輸入了模型中,進而得到了正反兩層隱節點,語境向量c則由RNN中的隱節點h通過不同的權重a加權而成。簡單的說,這種模型在產生輸出的時候,還會產生一個“注意力範圍”表示接下來輸出的時候要重點關注輸入序列中的哪些部分,然後根據關注的區域來產生下一個輸出,如此往復。
模型的大概示意圖如下所示
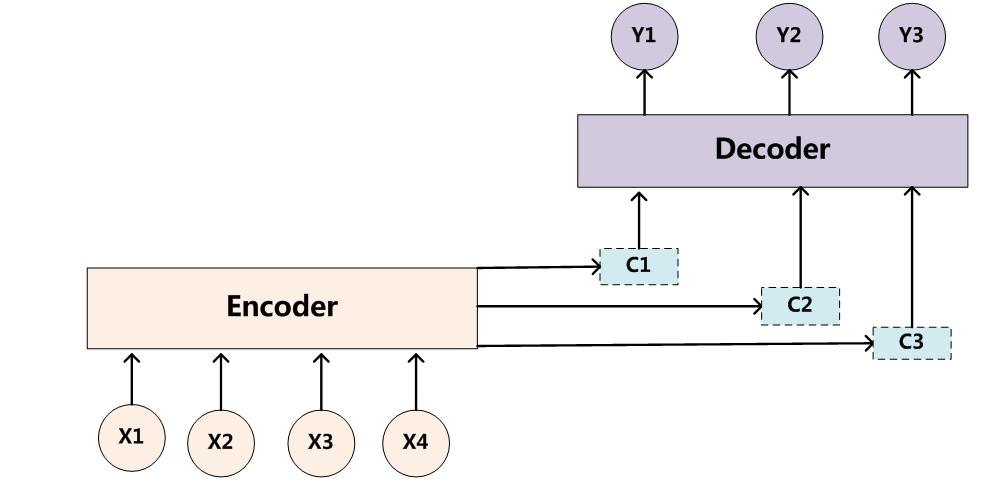
相比於之前的encoder-decoder模型,attention模型最大的區別就在於它不在要求編碼器將所有輸入資訊都編碼進一個固定長度的向量之中。相反,此時編碼器需要將輸入編碼成一個向量的序列,而在解碼的時候,每一步都會選擇性的從向量序列中挑選一個子集進行進一步處理。這樣,在產生每一個輸出的時候,都能夠做到充分利用輸入序列攜帶的資訊。
解碼
先看看解碼。解碼部分使用了attention模型。類似的,我們可以將之前定義的條件概率寫作
p(yi|y1,…,yi−1,X)=g(yi−1,si,ci)
具體展開形式:


or 


上式si表示解碼器i時刻的隱藏狀態。計算公式是
si=f(si−1,yi−1,ci)
注意這裡的條件概率與每個目標輸出yi相對應的內容向量ci有關,而在傳統的方式中,只有一個內容向量C。
內容向量ci是由編碼時的所有(而不只是最後一個隱層了)隱藏向量序列(h1,…,hTx)按權重相加得到的:
c i =∑j=1Txαijhj
由於編碼使用了雙向RNN,因此可以認為hi中包含了輸入序列中第i個詞以及前後一些詞的資訊。將隱藏向量序列按權重相加,表示在生成第j個輸出的時候的注意力分配是不同的。αij的值越高,表示第i個輸出在第j個輸入上分配的注意力越多,在生成第i個輸出的時候受第j個輸入的影響也就越大。
αij又是怎麼得到的呢?這個其實是由第i-1個輸出隱藏狀態si−1和輸入中各個隱藏狀態共同決定的。即
αij=exp(eij)∑Txk=1exp(eik)eij=a(si−1,hj)

也就是說,si−1先跟每個h分別計算得到一個數值,然後使用softmax得到i時刻的輸出在Tx個輸入隱藏狀態中的注意力分配向量。這個分配向量也就是計算ci的權重。
decoder公式彙總(解碼器在第i個時間段內要做的事情) :
eij=a(si−1,hj)αij=exp(eij)∑Txk=1exp(eik)ci=∑j=1Txαijhjsi=f(si−1,yi−1,ci)yi=g(yi−1,si,ci)
示意圖:
編碼
編碼就比較普通了,只是傳統的單向的RNN中,資料是按順序輸入的,因此第j個隱藏狀態h→j只能攜帶第j個單詞本身以及之前的一些資訊;
而如果逆序輸入,則h←j包含第j個單詞及之後的一些資訊。
如果把這兩個結合起來,hj=[h→j,h←j]就包含了第j個輸入和前後的資訊。
程式碼實現及示例
seq2seq有多種多樣的形式,使用了不同的RNN核,但是萬變不離其宗,其總是接受一個編碼和解碼的輸入。
TensorFlow seq2seq模型
TensorFlow也為此建立了一個模型:tensorflow/tensorflow/python/ops/seq2seq.py,最基本的RNN編碼-解碼器就像是這樣子的:
outputs, states = basic_rnn_seq2seq(encoder_inputs, decoder_inputs, cell)
Tensorflow中實現encoder-decoder模型
tensorflow中資料預處理
在神經網路中,對於文字的資料預處理無非是將文字轉化為模型可理解的數字,這裡都比較熟悉,不作過多解釋。
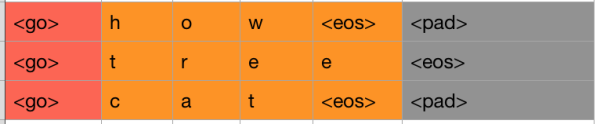
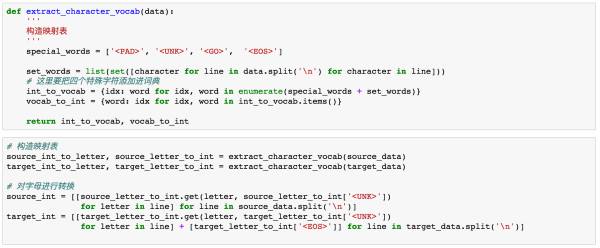
需要對target端的資料進行一步預處理。在這裡我們需要加入以下四種字元,<PAD>主要用來進行字元補全,<EOS>和<GO>都是用在Decoder端的序列中,告訴解碼器句子的起始與結束,<UNK>則用來替代一些未出現過的詞或者低頻詞。
-
< PAD>: 補全字元。
-
< EOS>: 解碼器端的句子結束識別符號。
-
< UNK>: 低頻詞或者一些未遇到過的詞等。
-
< GO>: 解碼器端的句子起始識別符號。
用下圖解釋:

我們此時只看右邊的Decoder端,可以看到我們的target序列是[<go>, W, X, Y, Z, <eos>],其中<go>,W,X,Y,Z是每個時間序列上輸入給RNN的內容,我們發現,<eos>並沒有作為輸入傳遞給RNN。因此我們需要將target中的最後一個字元去掉,同時還需要在前面新增<go>標識,告訴模型這代表一個句子的開始。
構造Decoder
-
對target資料進行embedding。
-
構造Decoder端的RNN單元。
-
構造輸出層,從而得到每個時間序列上的預測結果。
-
構造training decoder。
-
構造predicting decoder。
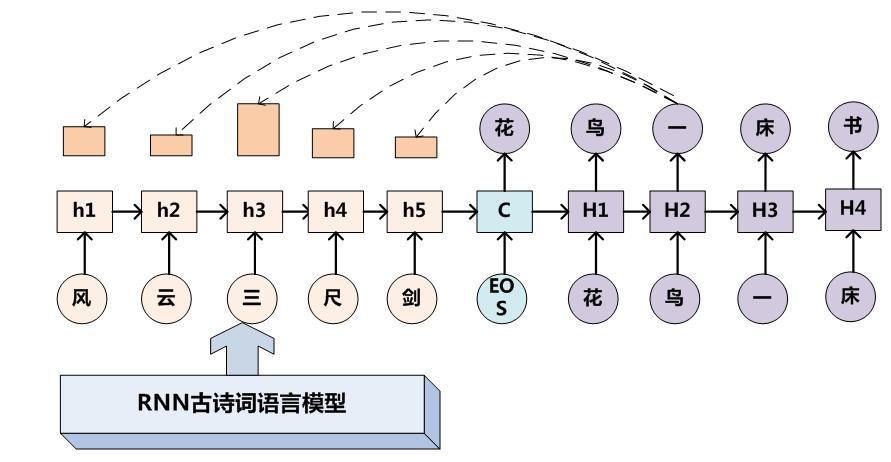
encoder-decoder對聯示例
給出上聯對下聯圖例

Encoder-Decoder框架加上Attention應該會顯著提升產生下聯的質量,原因還是因為它是要求嚴格對仗的。
上聯給出 完全自動生成對聯(上聯也自動生成)
seq2seq在回覆生成(Response Generation)任務中的應用和論文
Shang等人針對單輪對話任務提出了一種混合模型,使用基礎模型的上下文向量建模輸入序列的整體資訊,使用Attention的加權和動態捕捉每次解碼所需的區域性資訊,將兩者拼接作為新的上下文向量進行解碼(Shang L et al. 2015)。
此外,Serban等人提出了多層次的RNN模型來完成多輪對話任務。其中底層Encoder負責句子級的編碼,高層Encoder讀取底層Encoder對所有歷史句子的編碼作為輸入從而對上下文進行編碼,最後由Decoder根據上下文編碼解碼出輸出序列(Serban I Vet al. 2016a)。
用於回覆生成的Sequence to sequence模型所產生的回覆,存在一個較為普遍的問題:回覆內容的相關性問題。通過實驗結果的觀察,大家發現模型總是傾向於生成一般性的萬能回覆,如“我不知道”,“我也是”等。很多人針對這個問題對Sequence to sequence模型進行了相應的改進。
Li等人提出可以使用最大互資訊目標函式來訓練模型,將輸入輸出序列的互資訊視為相關性的參考指標,使模型預測出和輸入序列具有最大互資訊的輸出序列,從而獲得相關性更好的回覆(LiJ etal. 2015)。
Serban等人提出了在生成階段引入一個隨機的隱變數來增強回覆的多樣性(Serban I V et al. 2016b),之後又提出了在基本結構上加入一個主題詞Encoder以加強回覆和輸入序列相關性的方法(Serban I V et al. 2016c)。
此外,Mou等人也基於這種利用主題詞的方法來解決萬能回覆的問題,他們首先使用統計的方式計算出一個應該在回覆中出現的主題詞,然後由這個主題詞開始使用Sequence to sequence模型先逆向生成回覆的前半句,然後再正向生成回覆的後半句,兩者拼接形成最終的回覆(Mou L et al. 2016)。
(Zhu Q et al. 2016)認為模型中所有回覆均由開始字元開始生成,可能是導致萬能回覆的一個問題,進而將生成階段分成了兩部分進行,在不使用開始字元的條件下生成第一個回覆的字元。我們將Encoder的最後一個隱層狀態向量c看做當前時刻的上下文,使用一個相似度矩陣來計算c與所有候選詞Embedding向量的相似性,進而在所有候選詞中選取相似性最大者作為第一個字元。其中相似度矩陣作為模型的引數在訓練過程中和其他引數共同學習得到。獲取第一個字元後,使用這個字元由Decoder繼續後續的生成。
ref: 兩篇文章針對機器翻譯的問題
Google Brain團隊 [Ilya Sutskever, Oriol Vinyals, and Quoc VV Le. Sequence to sequence learning with neural networks. In NIPS, 2014.]
Yoshua Bengio團隊的《Learning Phrase Representation using RNN Encoder-Decoder for Statistical Machine Translation》