
神經網路----學習
目錄
歷程

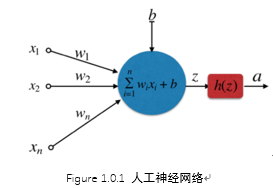
人工神經網路
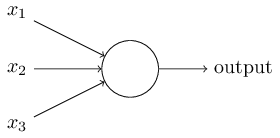
右圖的圓圈就代表一個感知器。它接受多個輸入(x1,x2,x3...),產生一個輸出(output),
為了簡化模型, 約定每種輸入只有兩種可能:1 /0。
所有輸入都是1--條件都成立--輸出--1;
所有輸入都是0--條件都不成立--輸出--0。
按照假設,輸出只有兩種結果:0和1。但是,模型要求w或b的微小變化,會引發輸出的變化。如果只輸出0和1,未免也太不敏感了,無法保證訓練的正確性,因此必須將"輸出"改造成一個連續性函式.

為什麼要是深度神經網而不是”肥胖“(寬度)神經網路---引數
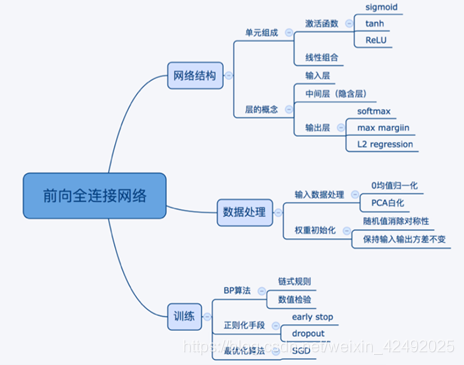
啟用函式
需要原因:就是使神經網路具有擬合非線性函式的能力,使其具有強大的表達能力
萬能近似定理:一個前饋神經網路如果具有線性層和至少一層具有"擠壓"性質的啟用函式(如signmoid等),給定網路足夠數量的隱藏單元,它可以以任意精度來近似任何從一個有限維空間到另一個有限維空間的borel可測函式
要有帶有“擠壓”性質的啟用函式”:
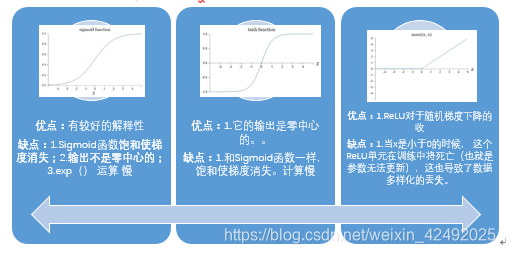
怎麼用啟用函式
用ReLU非線性函式。注意設定好學習率可以監控你的網路中死亡的神經元佔的比例。
模型引數

損失函式—交叉熵
為什麼用交叉熵而不用平方損失?

平方:偏導數受啟用函式的導數影響 ,sigmoid 的導數在輸出接近 0 和 1 的時候 是非常小的,這會導致一些例項在剛開始訓練時學習得非常慢
交叉熵:權重學習的速度受到 σ(z) − y 影響,更大的誤差,就有更快的學習速度,還避免了二次代價函式方程中因 σ′(z) 導致的學習緩慢
CNN
由來:影象領域,28*28*1的圖片進行處理,採用15個神經元,會有784*15*10+15+10=117625個引數
CNN將輸入資料看成三維的張量 (Tensor), 之前的NN把輸入資料看作向量
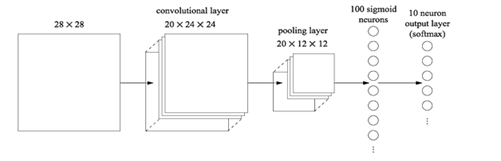
Figure 0.1 CNN
Convolution (卷積)
本質:提取影象不同頻段的特徵,可降低引數數量;稀疏互動防止過擬合;引數共享,減小儲存需求
更本質是積分,將時域->頻域相乘-反變換->時域的積分

Pooling
作用
- 整合特徵-降維
- 保證某種不變性(旋轉、平移、伸縮、對稱)(文字:獲得定長輸出)
- 減少計算量
- 提高感受野大小
方式
- Max—保留紋理(減小卷積層引數誤差造成估計均值偏移)
- Mean—保留背景(減低鄰域大小受限造成的估計值方差)
- Stochastic
Zero Padding
有時候會將輸入資料用0在邊緣進行填充,零填充可以控制輸出資料的尺寸(最常用的是保持輸出資料的尺寸與輸入資料一致)
Fully Connected Layer
作用
如果說卷積層、池化層和啟用函式層等操作是將原始資料對映到隱層特徵空間的話,全連線層則起到將學到的“分散式特徵表示”對映到樣本標記空間的作用。FC可視作模型表示能力的“防火牆”,特別是在源域與目標域差異較大的情況下,FC可保持較大的模型capacity從而保證模型表示能力的遷移。
RNN
迴圈神經網路(Recurrent Neural Network,RNN)是一種用於處理序列資料的神經網路。相比一般的神經網路來說,他能夠處理序列變化的資料
BPTT演算法是針對迴圈層的訓練演算法,它的基本原理和BP演算法是一樣的,也包含同樣的三個步驟:
- 前向計算每個神經元的輸出值;
- 反向計算每個神經元的誤差項值,它是誤差函式E對神經元j的加權輸入的偏導數;
- 計算每個權重的梯度。
最後再用隨機梯度下降演算法更新權重。
遞迴神經網路 (RNN)
代表迴圈網路的另一個擴充套件,它被構造為深的樹狀結構而不是RNN的鏈狀結構,因此是不同型別的計算圖
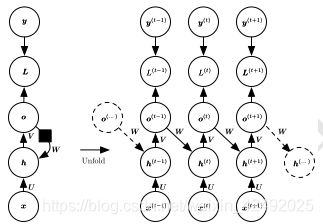
遞迴神經網路的權重和偏置項在所有的節點都是共享的
架構
Hopfield
Hopfield 網路實質上是二進位制的,各個神經元要麼開啟(啟用),要麼關閉(未啟用)
能夠學習(通過Hebbian學習)多種模式,並且在輸入中存在噪聲的情況下收斂以回憶最接近的模式。Hopfield 網路不適合用來解決時域問題
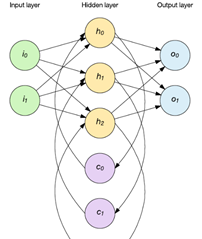
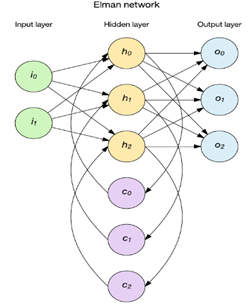
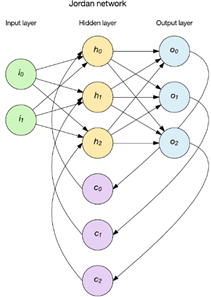
簡單遞迴網路
兩種流行方法是 Elman 和 Jordan 網路
LSTM&GRU
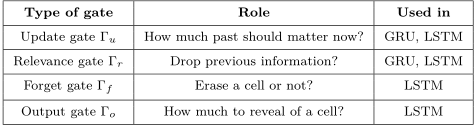
權重爆炸可能引起權重振盪。梯度消失又導致網路調參失去方向感
梯度截斷有助於處理爆炸的梯度;為了解決消失的梯度和更好地捕獲長期依賴,一種方法是使用LSTM以及其他自迴圈和門控機制;另一個想法是正則化或約束引數,以引導資訊流
- LSTM 通過引入巧妙的可控自迴圈,以產生讓梯度能夠得以長時間可持續流動的路徑避免長期依賴問題,關鍵就是細胞狀態
- GRU 它將忘記門和輸入門合成了一個單一的更新門。同樣還混合了細胞狀態和隱藏狀態,和其他一些改動
-

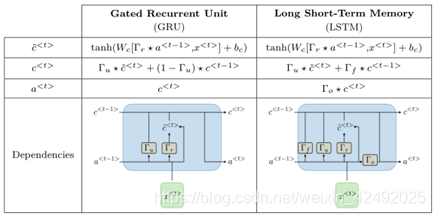
由於傳統的RNN存在梯度彌散問題或梯度爆炸問題,導致第一代RNN基本上很難把層數提上去,因此其表徵能力也非常有限,應用上效能也有所欠缺。於是,胡伯提出了LSTM,通過改造神經元,添加了遺忘門、輸入門和輸出門等結構,讓梯度能夠長時間的在路徑上流動,從而有效提升深度RNN的效能。