
序列標註Sequence labeling開原始碼
NCRF++:一個開源的神經序列標註工具包
Sequence labeling模型在許多NLP任務中都很流行,如命名實體識別(NER)、詞性標註(POS)和分詞。最先進的序列標註模型大采用了CRF結構 with input word features。LSTM(或BiLSTM)是一種基於深度學習的序列標註任務特徵提取器。由於計算速度更快,CNN也可以被使用。
NCRF++是一個基於PyTorch的框架,可以靈活選擇輸入特性和輸出結構。使用NCRF++的神經序列標記模型的設計可以通過配置檔案完全配置,不需要任何程式碼工作。NCRF++是CRF++的一個神經版本,是一個著名的統計CRF框架。
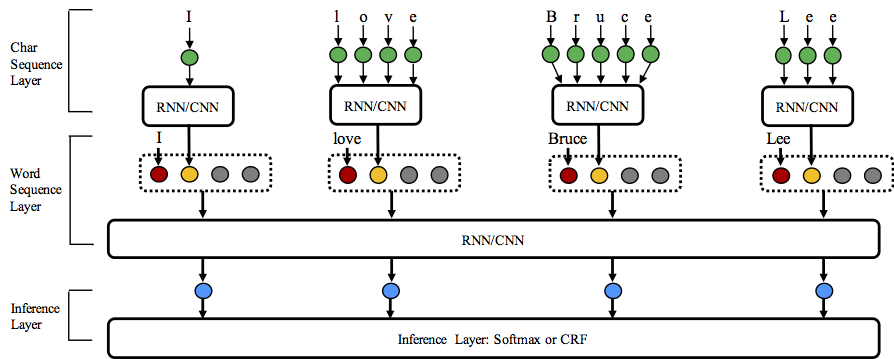
NCRF++ supports diffent structure combinations of on three levels: character sequence representation, word sequence representation and inference layer.
Character sequence representation:character LSTM, character GRU, character CNN and handcrafted word features. Word sequence representation:word LSTM, word GRU, word CNN. Inference layer:Softmax, CRF.
要求:
Python: 2 or 3
PyTorch: 0.3 (currently not support 0.4, waiting the release of PyTorch 1.0)優點:
1.Fully configurable:所有的神經模型結構都可以用配置檔案來設定。
2.State-of-the-art system performance:基於NCRF++的模型與最先進的模型相比可以提供類似或更好的結果。
3.Flexible with features:使用者可以定義自己的特性和預訓練的特性嵌入。
4.Fast running speed:NCRF++充分利用批處理操作,GPU (>1000sent/s training,>2000sents/s decoding)使系統高效執行。
5.N best output:NCRF++ support nbest decoding (with their probabilities).
用法:
In training status: python main.py --config demo.train.config
In decoding status: python main.py --config demo.decode.config
NCRF++支援通過修改配置檔案設計神經網路結構。程式可以在兩種狀態下執行:training和decoding。(示例的配置和資料已包含在此資源中)。配置檔案控制網路結構、I/O、訓練設定和超引數。
這裡列出了詳細的配置和說明。 NCRF++設計為三層(如下圖所示):字元序列層;詞序層和推理層。另一方面,使用者可以通過設計自己的模組來擴充套件每一層(例如,他們可能想要設計自己的神經結構,而不是CNN/LSTM/GRU)。我們的層次化設計使模組擴充套件更加方便,模組擴充套件說明在這裡可以找到。
2.Data format
您可以參考sample_data中的資料格式。NCRF++支援BIO和BIOES(BMES)標籤方案。請注意,目前不支援IOB格式(與BIO不同),因為這個標籤方案比較舊,而且比2017年的Reimers和Gurevych更糟糕。本文闡述了這三種標籤方案的區別。我寫了一個指令碼,將標籤方案在IOB/BIO/BIOES中轉換。
We have compared twelve neural sequence labeling models ({charLSTM, charCNN, None} x {wordLSTM, wordCNN} x {softmax, CRF}) on three benchmarks (POS, Chunking, NER) under statistical experiments, detail results and comparisons can be found in our COLING 2018 paper Design Challenges and Misconceptions in Neural Sequence Labeling.
4.External feature defining
NCRF++集成了CNN、LSTM、GRU等多個SOTA神經特徵提取器。此外,手工製作的feature已經被證明在順序標記任務中很重要。NCRF++允許使用者設計自己的feature,如大寫、POS或任何其他特性(上圖中的灰色圓圈)。使用者可以通過配置檔案配置自定義特性(feature embedding size, pretrained feature embeddings等)。示例輸入資料格式在train.cappos.bmes,其包括兩個人類定義的特性[POS]和[Cap]。([POS]和[Cap]就是兩個例子,你可以給你的特性取任何你想要的名字,只要按照格式[xx],然後在配置檔案中用相同的名字配置特性。)使用者可以配置每個特性通過使用:
feature=[POS] emb_size=20 emb_dir=%your_pretrained_POS_embedding feature=[Cap] emb_size=20 emb_dir=%your_pretrained_Cap_embedding
沒有預訓練embedding的特性將被隨機初始化。
6.N best decoding performance:
傳統的CRF結構只能解碼一個具有最大概率的標籤序列(即1-best output)。而NCRF++可以提供一個large choice,它可以解碼n個標籤序列 with the top n probabilities(即n-best output)。一些流行的統計CRF框架支援nbest解碼。然而就我們所知,NCRF++是唯一也是第一個支援nbest解碼的神經CRF模型的工具包。
在我們的實現中,當nbest=10時,在NCRF++中構建的CharCNN+WordLSTM+CRF模型可以在CoNLL 2003 NER任務上給出97.47% oracle F1-value(當nbest=1時F1 = 91.35%)。

7.Reproduce paper results and Hyperparameter tuning:
要在我們的COLING 2018論文中重現結果,只需在配置文demo.train.config中將迭代=1設定為迭代=100,並在此配置檔案中配置檔案目錄。 預設配置檔案描述Char CNN + Word LSTM + CRF模型,您可以通過相應地修改配置來構建自己的模型。 這個演示配置檔案中的引數在本文中是相同的。(請注意,CNN相關的模型需要稍微不同的引數,細節可以在我們的COLING paper中找到。)