
虛假流量識別(2)
上篇圍繞虛假流量的發生機制、發生原因(背後的利益捆綁)、識別虛假流量的常見維度等;下篇從一個案例完整介紹如何識別虛假流量。

在虛假流量的認知與識別(上篇)中介紹,虛假流量的識別可從基本屬性、產品參與度、轉化情況三方面來識別。
- 首先,基本屬性。具體包括:時間 & 地域維度、終端型別、作業系統、聯網方式、運營商、IP 集中等
- 其次,產品參與度。具體包括:跳出率、平均訪問深度、平均訪問時長、使用者行為路徑、頁面點選情況、流量留存情況、單頁面人均訪問次數等。
- 第三,轉化情況。因為很多作弊流量可以模仿人類行為,成功繞過跳出率、平均訪問深度和停留時長這些巨集觀指標,但是要模仿一個業務轉化就 比較難了,如果巨集觀指標表現很好,業務轉化很少的話,就需要提高警覺。
下面通過一個案例從使用者行為資料多維診斷虛假流量。這個案例圍繞上述三種A 企業是電商企業,日常會在社會化媒體進行廣告投放,在1月8日線上資料投放的常規檢查中發現,近期一家媒體(下 稱“M 渠道”)所帶來的流量資料異常大。為查明該媒體渠道所帶來的流量是否為虛假流量,A企業將M渠道下的使用者行為進行多維度細分,進行流量排查。
一. 基本屬性初步排查
流量訪問通常會分佈在一天中的各個時段,伴隨平滑的曲線形成訪問高峰與低峰。顯然虛假流量不具備這一特點,因為人 為 / 機器操作為節省成本不會在意流量的時間分佈,難免會在時間曲線上會有流量突增的情況。因此,要找到異常流量發 生的時間點,將時間細化到每小時的訪問資料,如果流量過於集中在某個時段,或者在不恰當的時間點出現了流量激增的 情況,這時候就要引起注意了。
1. 時間維度
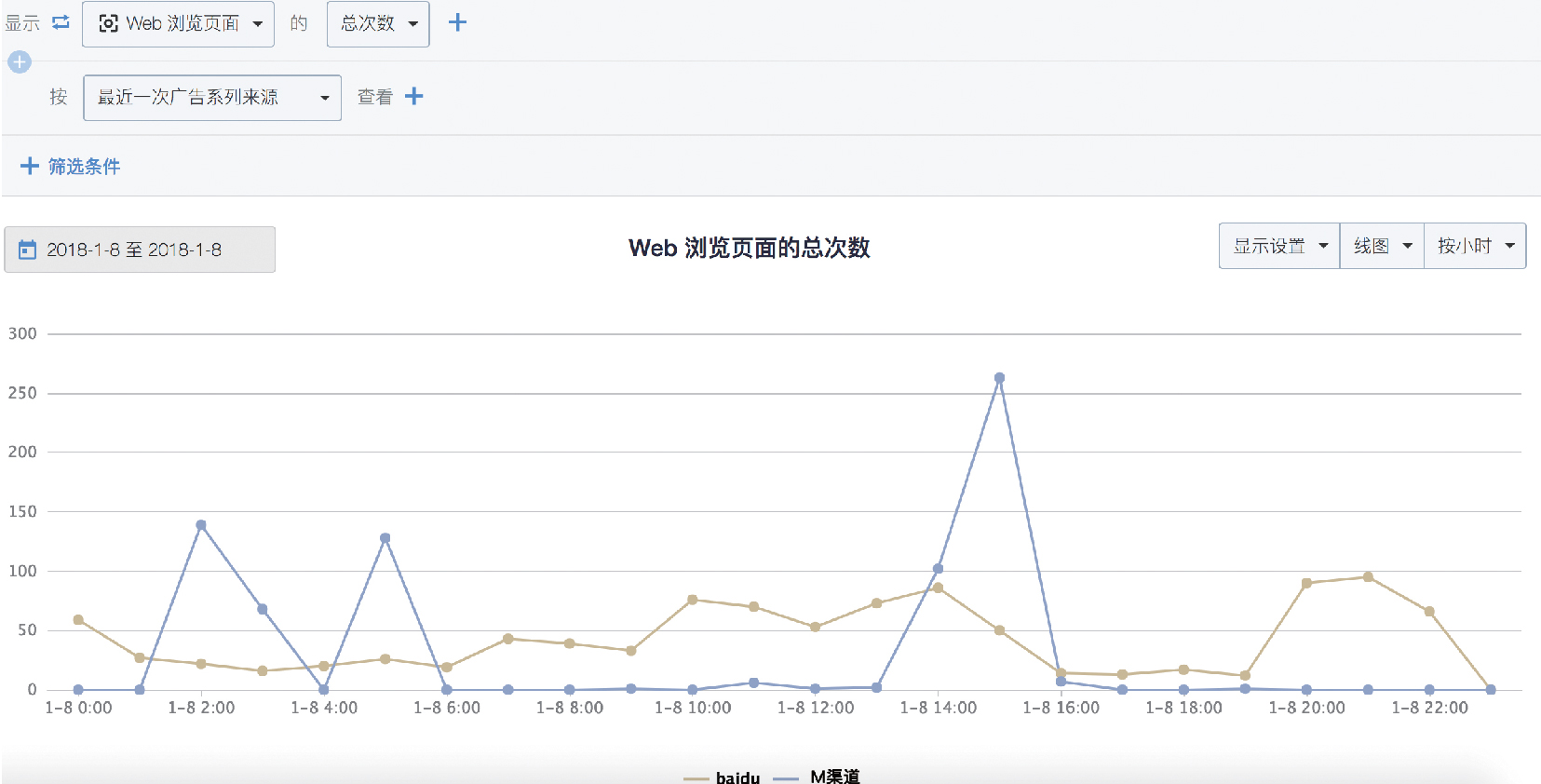
圖1 M 渠道與百度渠道流量對比
通過圖 1 看到,百度流量來源呈現平緩變化,從流量時間分佈上看,基本符合正常訪問情況。與之形成鮮明對比的是, M 渠道全天流量高峰期分別在 2:00、5:00、14:00、15:00。這幾個時段內的流量過於集中,而在其他正常時段內,流量幾乎為零。 經過內部確認,該階段並未有活動發生,產生突增的訪問高峰十分可疑。
2. 使用者訪問裝置
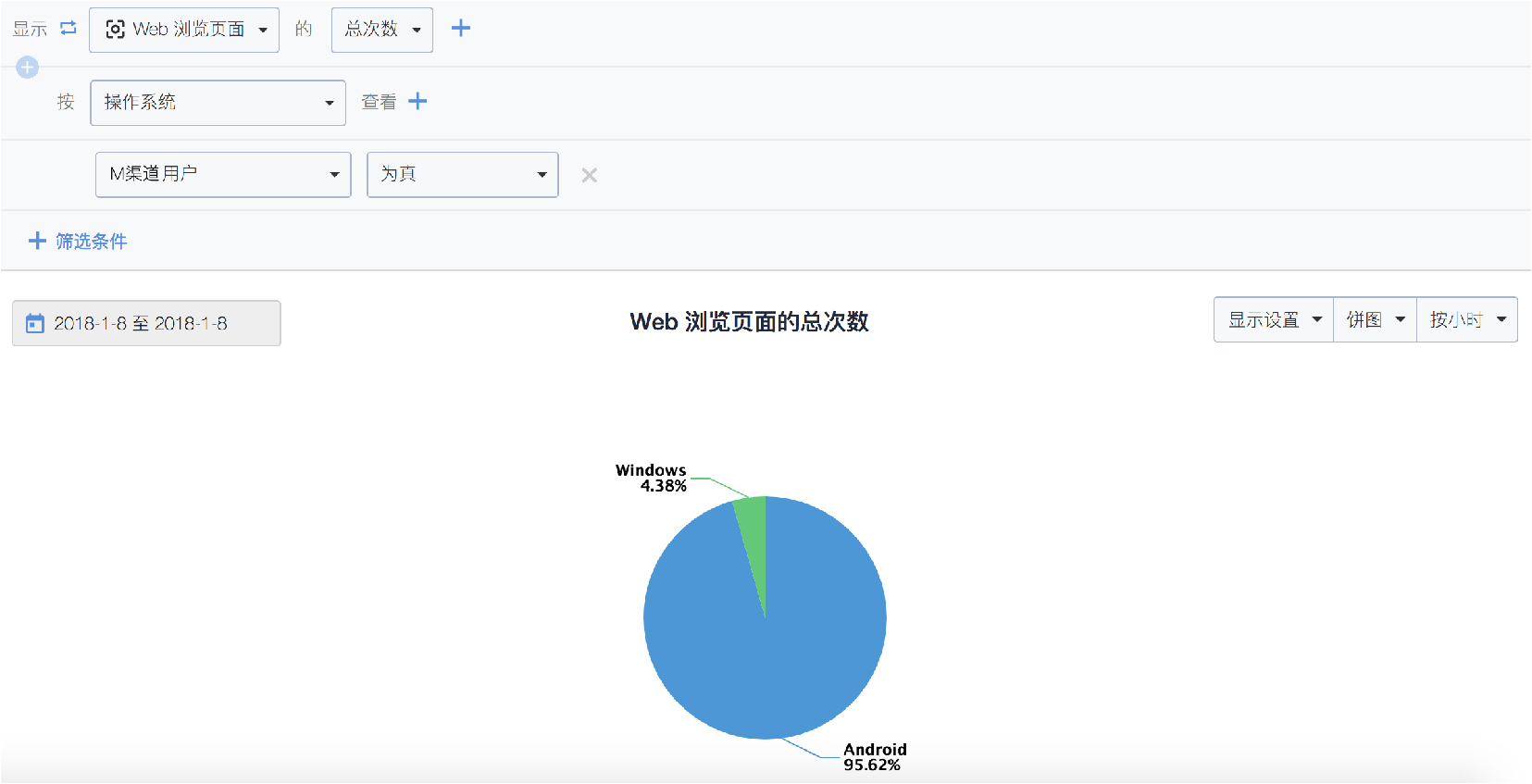
圖2 從裝置情況瞭解 M 渠道使用者的作業系統
上文提到在正常情況下,同樣使用者訪問裝置應該多元化。在這個案例中,通過上圖發現 M 渠道流量裝置基本都是 Android 端。 由於 M 渠道未投放,更沒有裝置限定,增加了虛假流量的可能性。
3. IP 集中
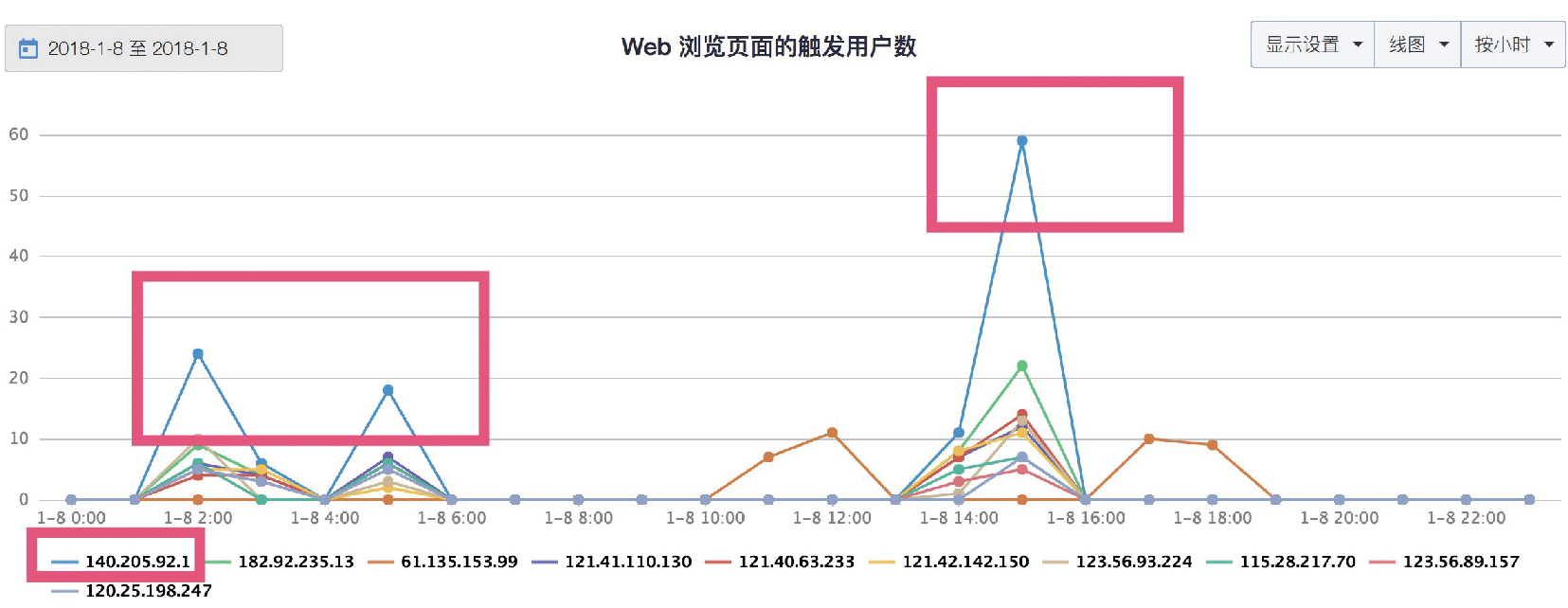
圖3 按 IP 檢視 Web 瀏覽頁面觸發使用者數
一般而言,IP 的頻繁點選、流量激增都是不正常的。我們通過資料可以看到,圖中 IP 帶來的流量在2:00、5:00和15:00 均有突變,尤其140.205.92.1 表現最明顯。經過以上維度診斷,此流量十分可疑,可結合產品參與度進行深度判定。
二. 產品參與度深度判定
1. 跳出率
虛假流量產生高跳出率的時間,通常會和使用者訪問時間段一致。因此可以結合流量時間等因素進行綜合對比。
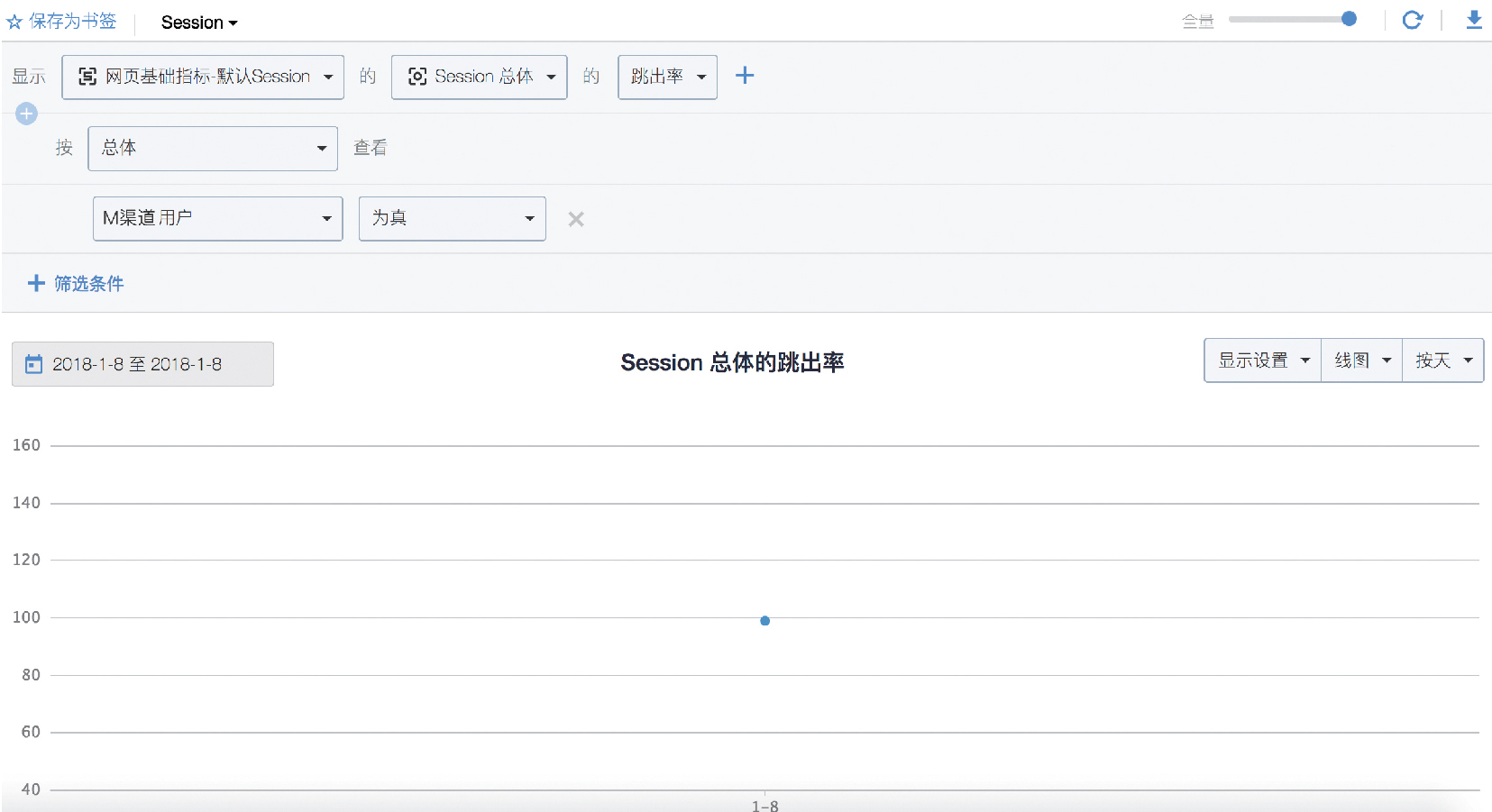
圖4 M 渠道來源流量的跳出率
從圖 4 來看,該渠道來的使用者跳出率高達98.88%,說明使用者通過渠道連結來到網站落地頁後,幾乎都沒有進行進一步 的瀏覽。
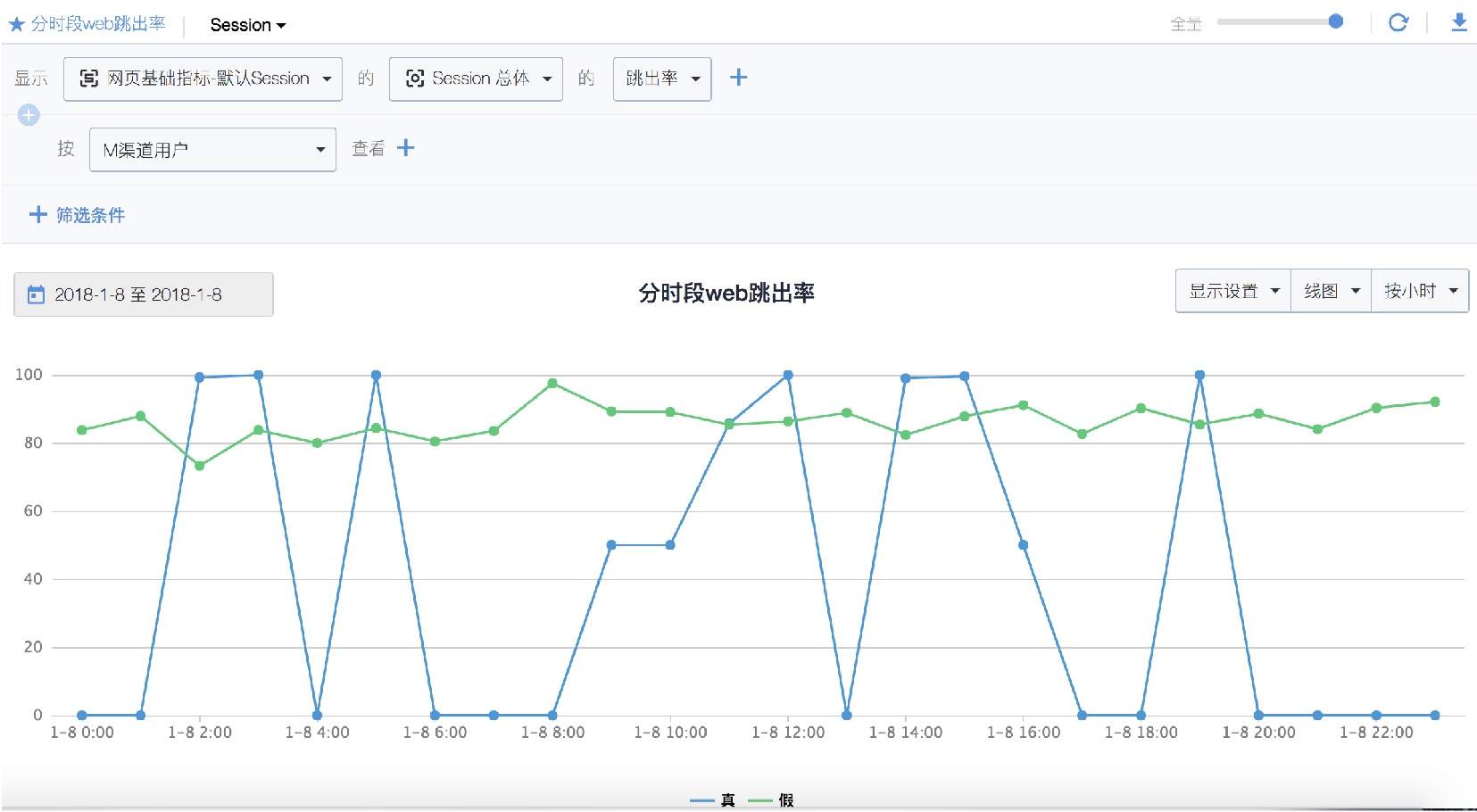
圖5 分時段檢視 Web 跳出率
通過 M 渠道使用者與非 M 渠道使用者跳出率情況的對比。我們可以看到,非 M 渠道使用者的跳出率變化比較平緩,分佈在 80% 上下。而 M 渠道使用者跳出率的變化則是分時段網站突然增高的,突增的時段恰好和前面的訪問突增時段吻合,比如凌晨 2:00 和 5:00 時段,這部分流量更值得懷疑。
當然,即使 M 渠道流量從跳出率指標上來看錶現很好,我們也不能直接定位它一定就是真實的流量,還應該結合訪問深度 和訪問時長、訪問路徑等來進行深度分析。
2. 平均訪問深度
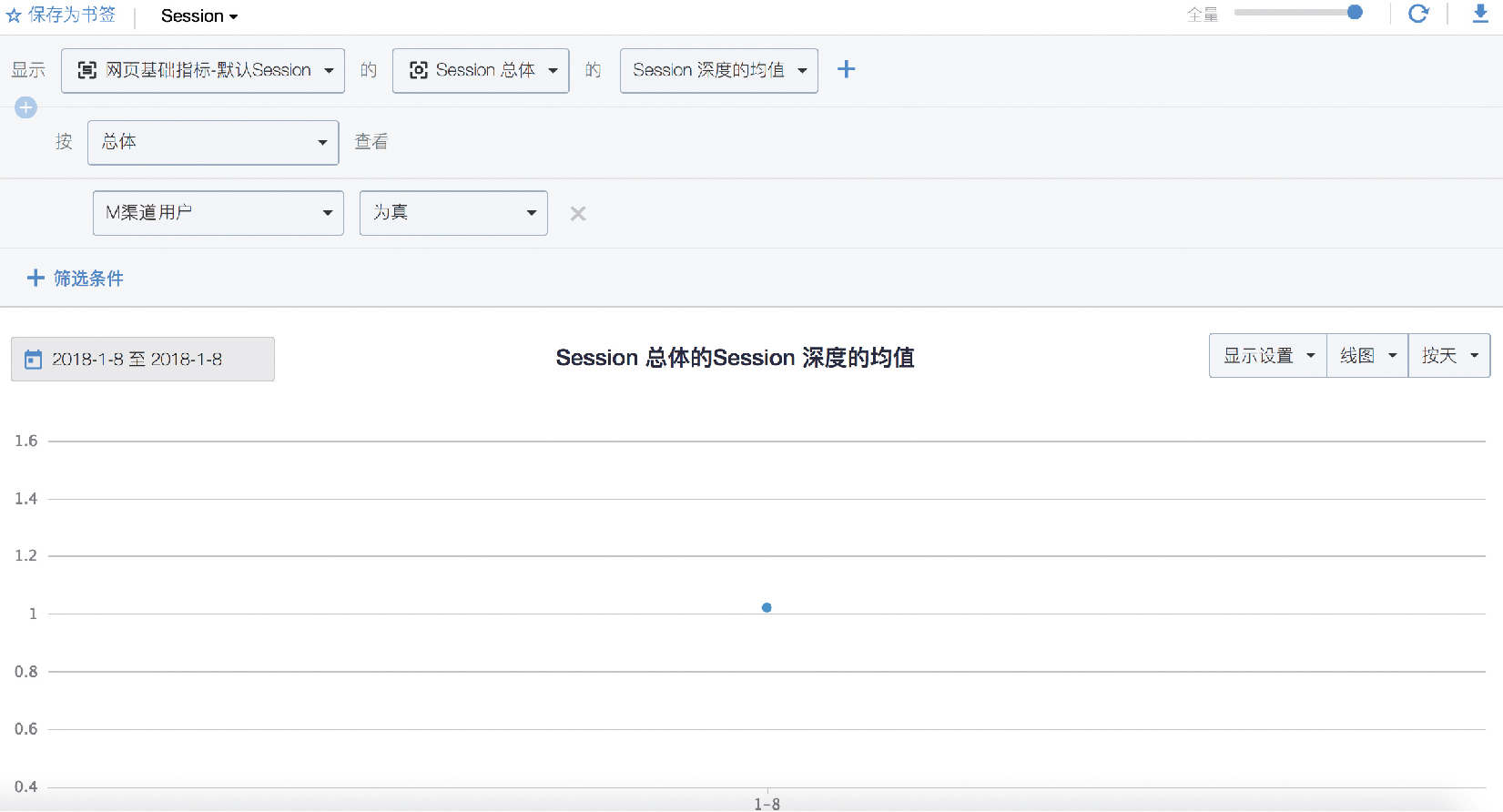

圖 6 平均訪問深度判定
從圖 6 中我們可以看到,M 渠道使用者一次訪問平均瀏覽了 一 個頁面,說明大部分的會話都是訪問一個頁面就退出了,並 沒有進行後續頁面瀏覽。
2. 平均訪問時長
如圖 7,M 渠道使用者平均在網站停留的時長 6.2s。6s 的時間,可能大部分使用者是在網站都瀏覽 1-2 個頁面就退出,並無 明顯的互動行為。為了驗證該猜想,可以看圖 8 的使用者路徑分析。
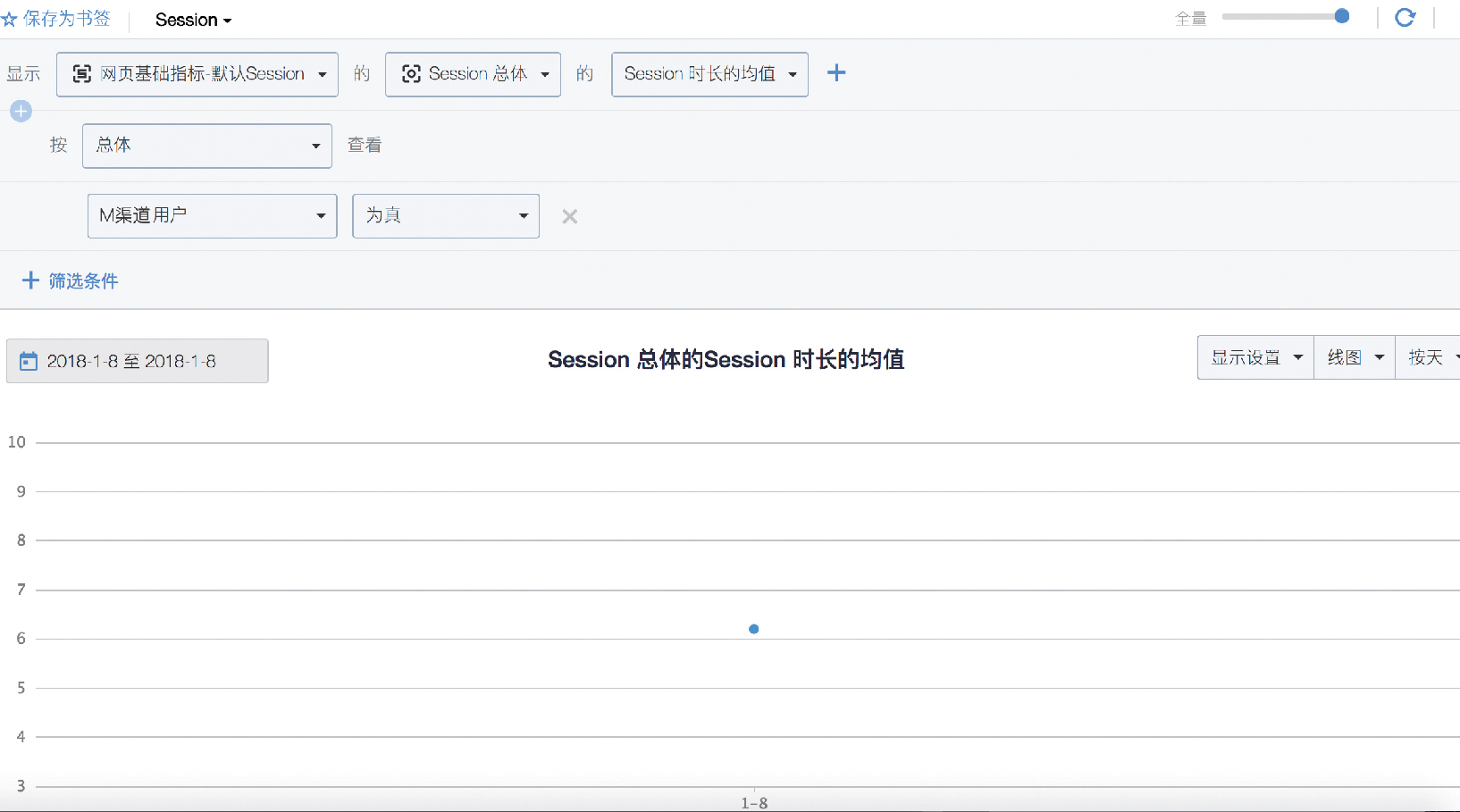

圖 7 M 渠道使用者的平均訪問時長分析
3. 使用者行為路徑
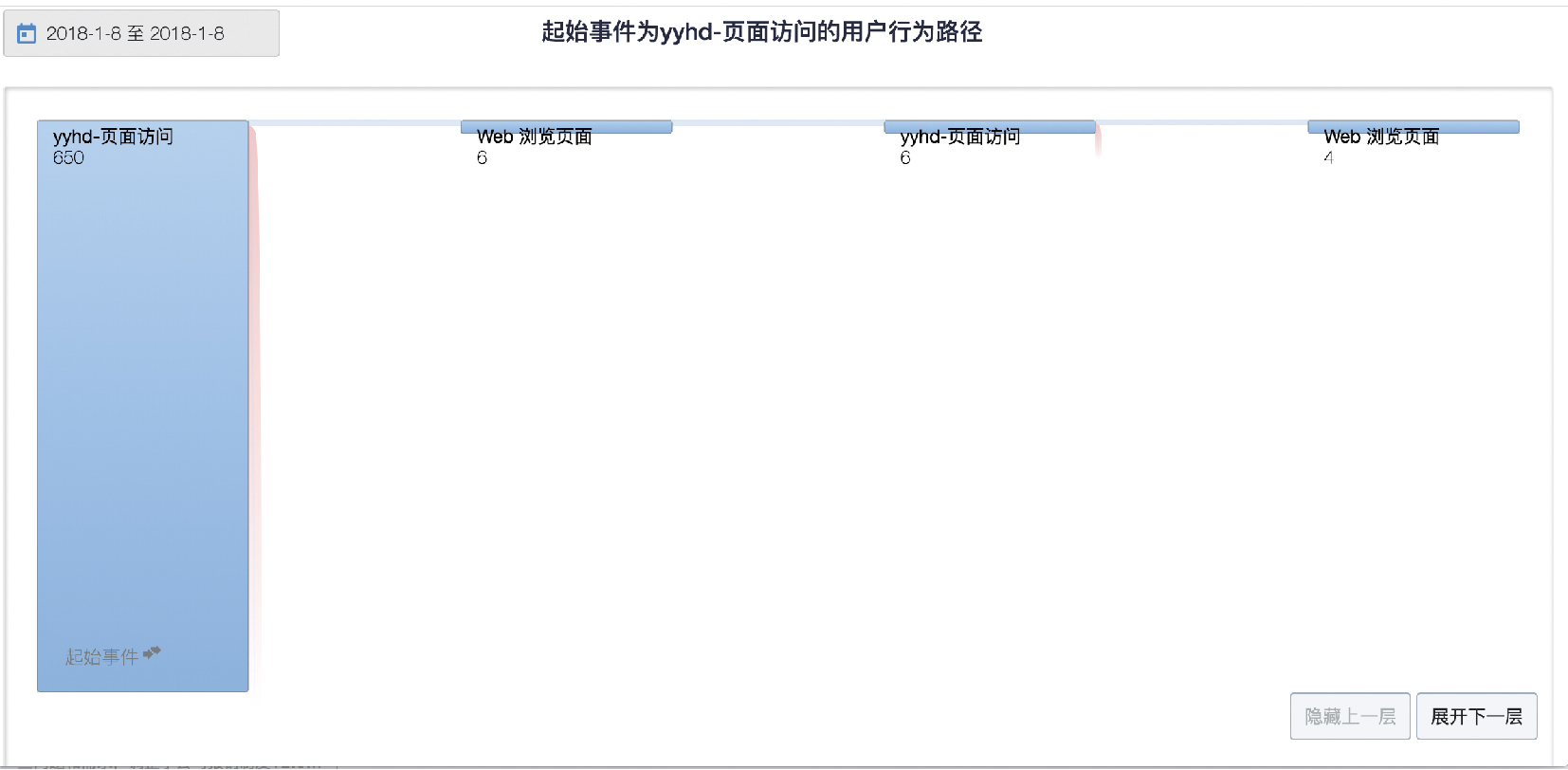
圖8 M 渠道使用者行為路徑
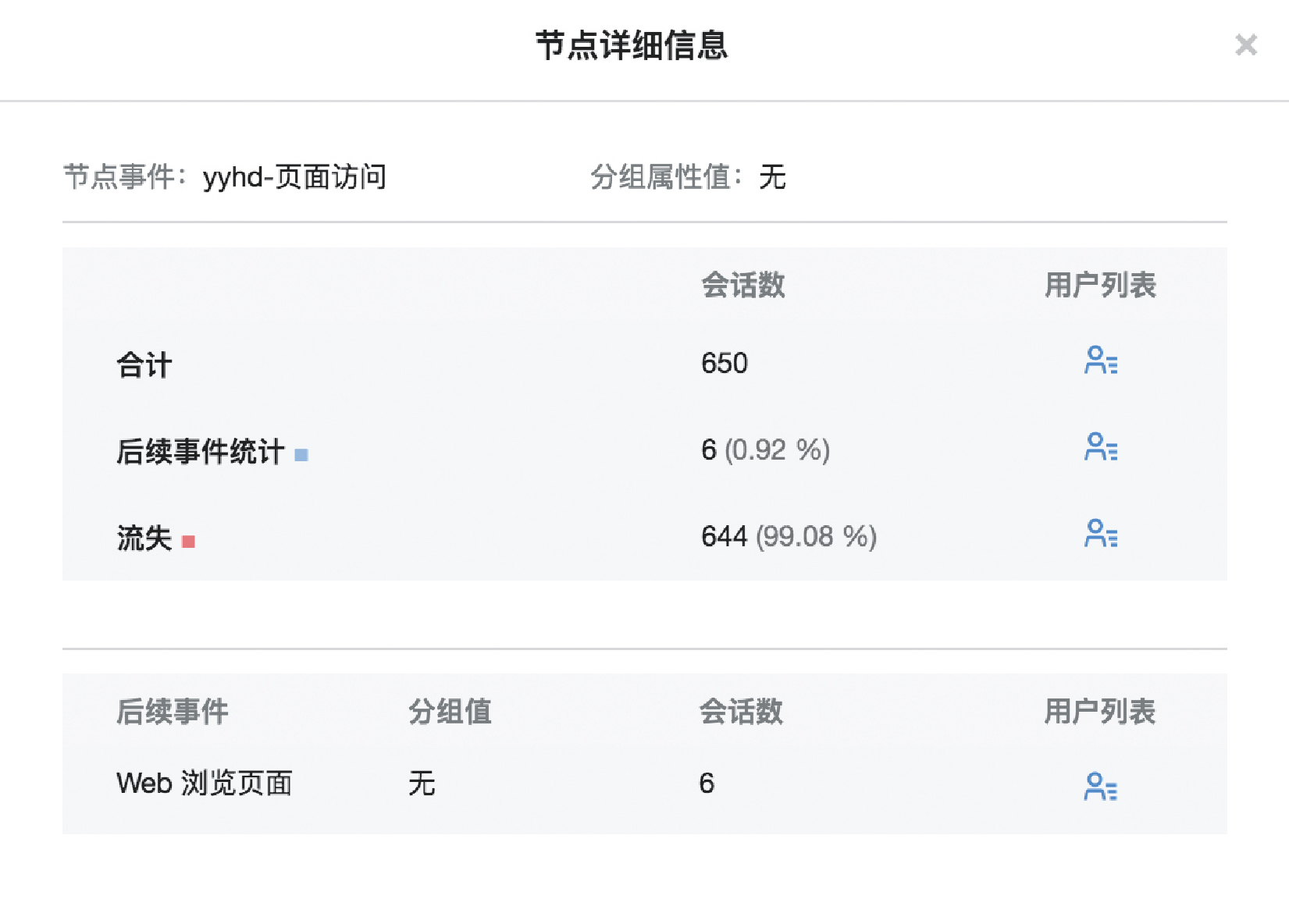
圖9 使用者行為路徑“頁面訪問”的節點資訊
在這個案例中,圖 9 是 M 渠道使用者的前 4 次訪問的分佈情況,可以發現,大部分使用者是先進行的首頁面訪問 -> 退出。 通過節點資訊檢視,還可以發現,在頁面訪問後,99.08% 的使用者無後續動作。
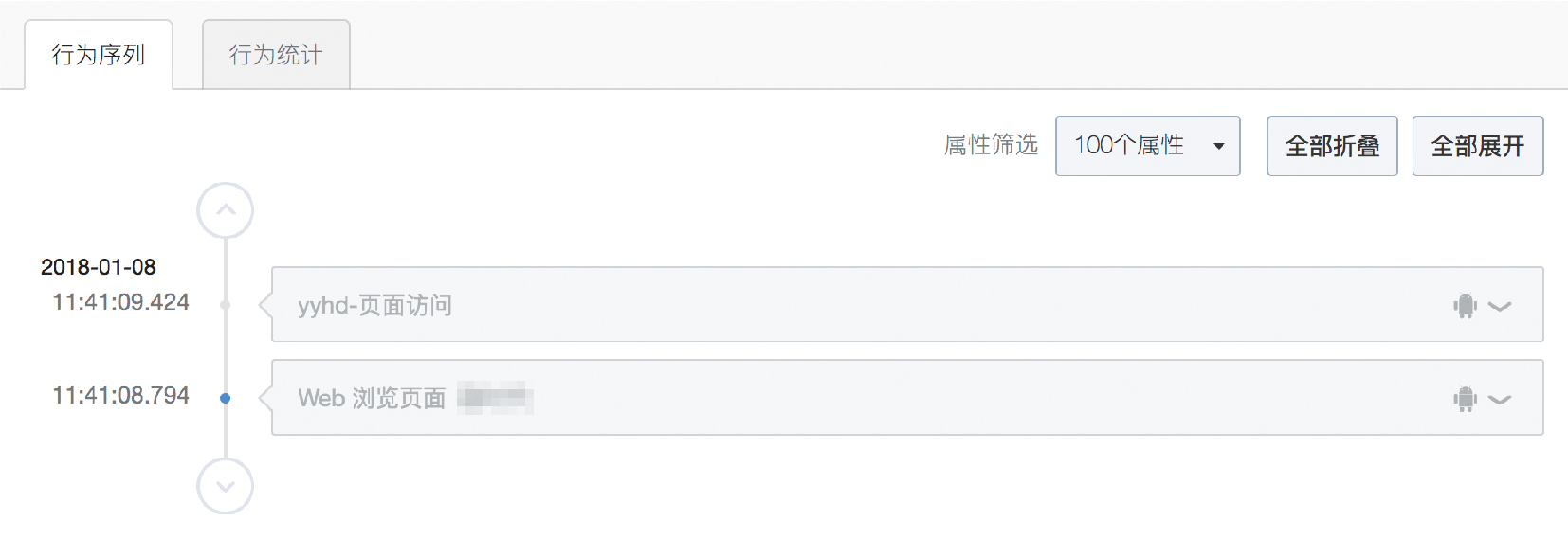
圖10 抽樣 M 渠道 30 個使用者,其中 29 個使用者的行為路徑
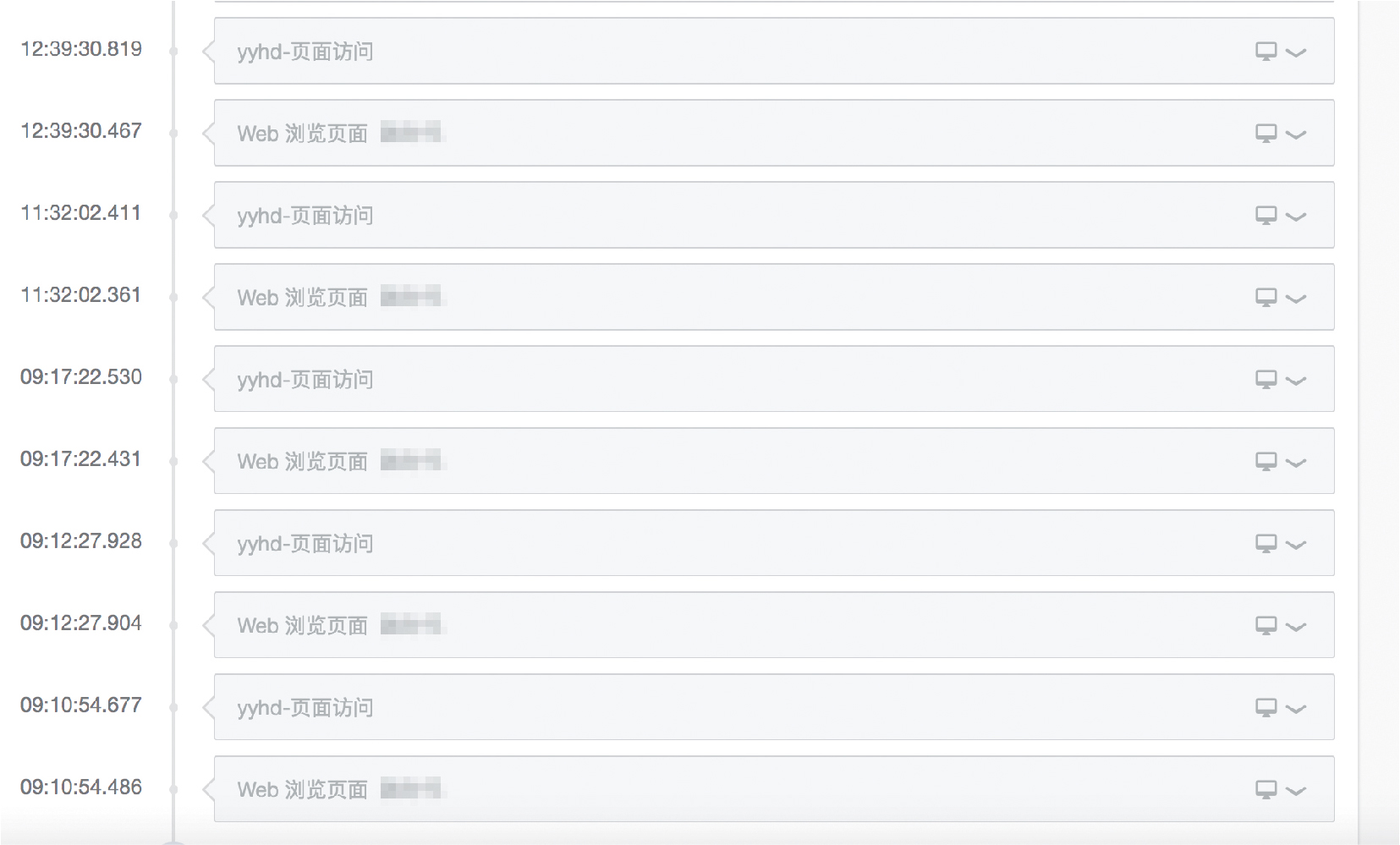
圖11 抽樣 M 渠道 30 個使用者,唯一使用者的行為路徑
在 M 渠道的使用者群體中,隨機抽取了 30 個使用者,發現其中 29 個使用者為上圖情況,這批使用者具有相同的行為序列,來到落 地頁後均無後續動作而退出。 針對唯一有後續行為的使用者,通過行為序列分析發現,使用者行為多次瀏覽落地頁,但瀏覽動作重複,隔一段時間進行一次 落地頁訪問,行為也有重複。因此 M 渠道使用者的行為路徑存在太強的規律性,是有跡可循的,進一步證實了是虛假流量。 ( 備註 : 一個迴圈單元中的兩個動作間隔極短,不到 1s,應該這兩個事件是一次瀏覽落地頁而觸發的神策預置採集的 Web 瀏覽事件和自定義事件頁面訪問,其實只是一個瀏覽落地頁的動作 )。
三. 轉化情況終極確認
目前有些作弊流量可以模仿人類行為,繞過跳出率、平均訪問深度和停留時長這些巨集觀指標,但是要模仿一個業務轉化就 比較難了,如果巨集觀指標表現很好,業務轉化很少的話,就需要提高警覺。 根據實際業務流程,我們定義“提交訂單”是核心轉化。我們設定核心轉化漏斗步驟如下 :
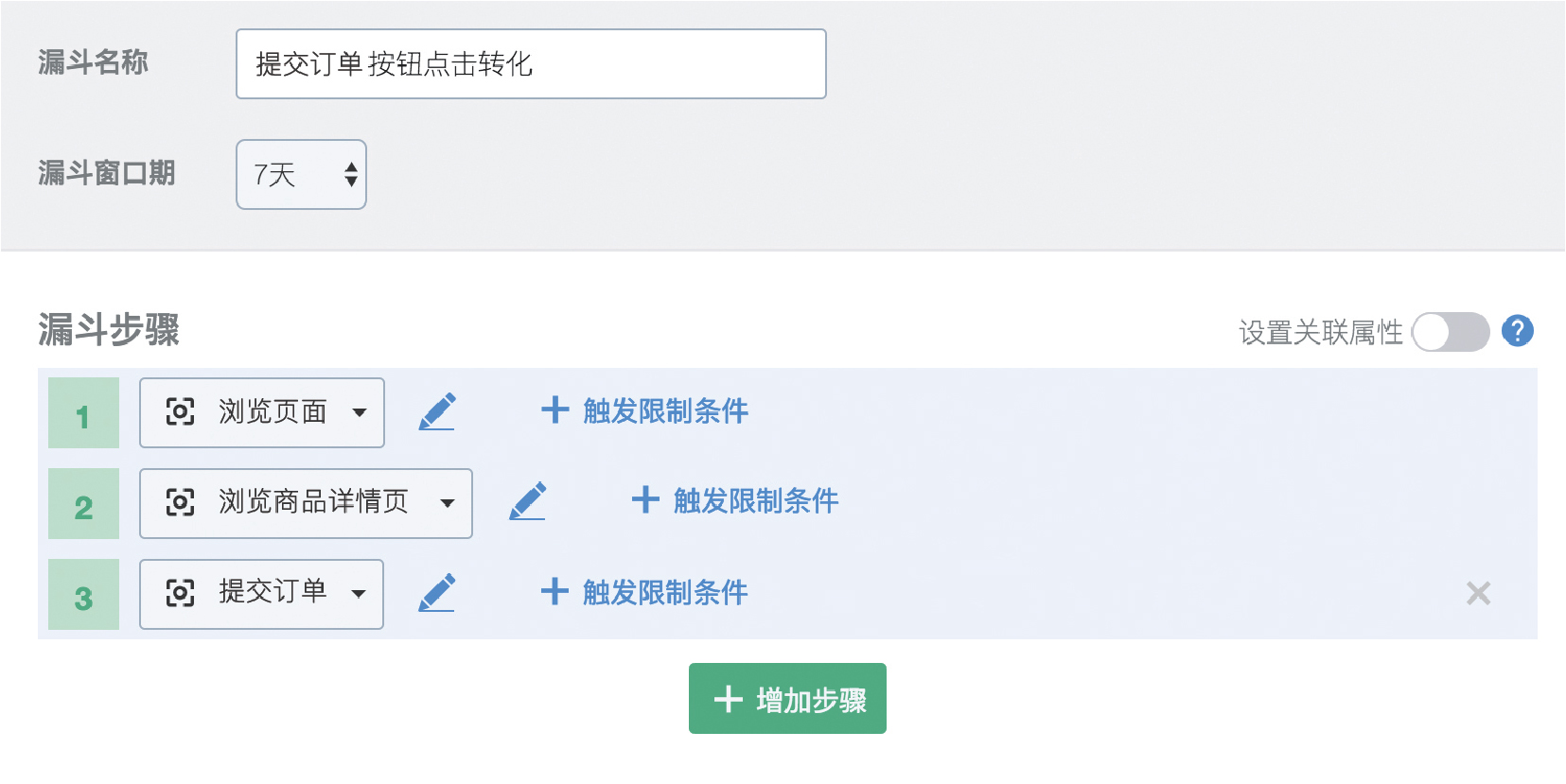
圖12 設定核心轉化漏斗流程
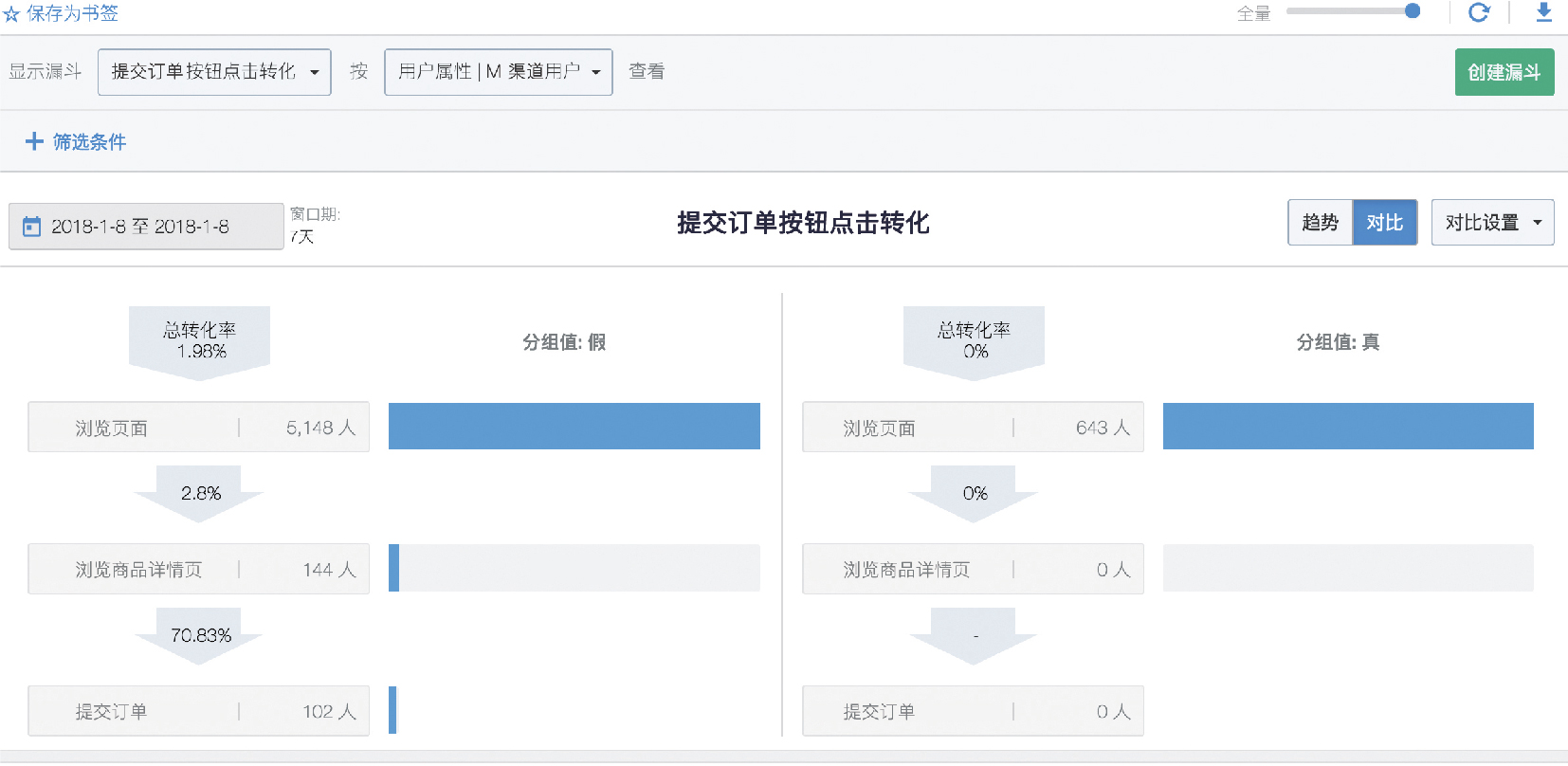
圖13 M 渠道使用者與非 M 渠道使用者核心轉化對比
通過漏斗分析對比,可以看到 M 渠道使用者完成核心轉化的使用者數為 0。在漏斗轉化中,我們發現當用戶訪問頁面訪問後, 並沒有使用者去點選核心按鈕“提交訂單”,更是沒有有效點選的使用者。M 渠道雖然給平臺帶來了很大流量,但是核心轉化的 人數為 0,對於我們核心業務並無幫助。再結合使用者在網站中的參與度與行為分析,該流量符合我們判斷虛假流量的常見 特徵。
通過神策分析平臺進行的上述分析,我們通過對 M 渠道流量產生的時間、流量的使用者終端、流量的跳出率、退出率、平均 訪問時長、平均訪問深度、使用者路徑以及流量的核心轉化等方面進行分析,可以發現,該批流量在流量分佈上呈現不自然性、 過於規律的特點,基本判斷 M 渠道產生的流量為虛假流量。
總結
面對虛假流量我們應該做什麼?資料分析是識別虛假流量的重要方式之一。除此之外,一些企業也嘗試通過邏輯判斷設定相應機制,來輔助識別虛假流量。 例如一家企業在 APPStore版本更新時,如果發版的第二天新增使用者為老版本,那麼這部分群體將自動被判定為疑似虛假 流量,並對其遮蔽相關功能,如預設福利、私信等,當然還會提供使用者申訴解封的途徑,以防誤判。
無論通過哪種方式,虛假流量都被證明為並非無跡可尋。其中資料分析是識別虛假流量相對直接且簡單的識別途徑,為廣 告主為提升數字營銷運營能力。這要求企業主:
一方面,要掌握可靠的衡量資料。依據對資料分析工具的熟稔應用以及監 測執行經驗,企業應與能夠實現多維資料分析平臺進行合作,神策資料幫助企業對疑似流量進行精細維度的排查,輔助網 絡投放環境的淨化;
另一方面,廣告主應不斷優化運營模式與改善運營狀況,虛假流量的監測與識別並非高度依靠技術能力, 廣告主在理解虛假流量特徵後,可通過基礎資料分析專業知識,評估數字廣告投放效果,不斷優化投放渠道。