統計學習方法(1) 理論基礎
基本概念:
1、基本假設:
統計學習假定資料存在一定的統計規律,監督學習關於資料的基本假設就是假設X和Y具有聯合概率分佈P(X, Y)。
2、假設空間(模型):
監督學習的模型可以是概率模型或非概率模型,由條件概率分佈P(Y|X)或決策函式Y=f(X)表示,隨具體學習方法而定。對具體的輸入進行相應的輸出預測時,寫作P(y|x)或y=f(x)。
3、策略:
在假設空間中選取模型f作為決策函式,對於給定的輸入X,由f(X)給出相應的輸出Y,這個輸出f(X)與真實值Y可能一致也可能不一致,用損失函式來度量預測錯誤的程度,如果能使這個損失函式足夠小,則可以保證模型具有較好的預測精度。損失函式是f(X)和Y的非負實數函式,記作L(Y, f(X))
- 損失函式:損失函式度量模型
一次預測的好壞; - 風險函式:風險函式度量
平均意義下模型預測的好壞,即期望損失。
(1)損失函式
-
0-1損失函式(0-1 loss function) 可以看出,該損失函式的意義就是,當預測錯誤時,損失函式值為1,預測正確時,損失函式值為0。該損失函式不考慮預測值和真實值的誤差程度,也就是隻要預測錯誤,預測錯誤差一點和差很多是一樣的。 感知機就是用的這種損失函式。但是由於相等這個條件太過嚴格,因此我們可以放寬條件,即滿足 |Y−f(X)|<T 時認為相等。
-
平方損失函式(quadratic loss function) 該損失函式的意義也比較簡單,就是取預測差距的平方。
-
絕對值損失函式(absolute loss function) 該損失函式的意義和上面差不多,只不過是取了絕對值,差距不會被平方放大。
-
對數損失函式(logarithmic loss function) 這個損失函式就比較難理解了。事實上,該損失函式用到了
極大似然估計的思想。P(Y|X)通俗的解釋就是:在當前模型的基礎上,對於樣本X,其預測值為Y,也就是預測正確的概率。由於概率之間的同時滿足需要使用乘法,為了將其轉化為加法,我們將其取對數。最後由於是損失函式,所以預測正確的概率越高,其損失值應該是越小,因此再加個負號取個反。
邏輯斯特迴歸的損失函式就是對數損失函式,
對數損失函式與極大似然估計的對數似然函式本質上是等價的,所以邏輯迴歸直接採用對數損失函式來求引數,實際上與採用極大似然估計來求引數是一致的。
-
指數損失函式 AdaBoost就是以指數損失函式為損失函式的。
-
Hinge損失函式 Hinge損失函式和SVM是息息相關的。線上性支援向量機中,最優化問題可以等價於 : 這個式子和如下的式子非常像: 其中就是hinge損失函式,後面相當於L2正則項。 Hinge函式的標準形式: y是預測值,在-1到+1之間,t為目標值(-1或+1)。其含義為,y的值在-1和+1之間就可以了,並不鼓勵|y|>1,即並不鼓勵分類器過度自信,讓某個正確分類的樣本的距離分割線超過1並不會有任何獎勵,從而使分類器可以更專注於整體的分類誤差。
(2)風險函式
全域性損失函式:
上面的損失函式僅僅是對於一個樣本來說的。而我們的優化目標函式應當是使全域性損失函式最小。因此,全域性損失函式往往是每個樣本的損失函式之和,也叫經驗風險函式。
模型的輸入、輸出(X, Y)是隨機變數,遵循聯合分佈P(X, Y),所以損失函式的期望:
這是理論上f(X)關於聯合分佈P(X, Y)平均意義下的損失,成為風險函式或期望損失。
如果知道聯合分佈P(X, Y),可以從聯合分佈直接求出條件概率分佈P(Y | X),就不需要學習了(例如:樸素貝葉斯是不需要學習的). 正是因為不知道聯合概率分佈,所以才需要學習。
那麼,聯合概率分佈不確定的情況下如何構建模型呢?
一個很自然的想法就是利用現實中觀察到的訓練樣本來對模型進行近似,資料越多,模型卻接近全域性。
給定一個訓練資料集:
模型f(X)關於訓練集T的平均損失稱為經驗風險或經驗損失:
根據大數定律,當樣本容量N趨於無窮,經驗風險趨於期望風險。但由於資料數目有限,需要對經驗風險進行一定的校正,從而涉及監督學習的兩個基本策略:
- 經驗風險最小化
- 結構風險最小化
經驗風險最小化和結構風險最小化:
當樣本容量足夠大時,經驗風險可以保證較好的學習效果:
經驗風險最小化求最優模型就是求解最優化問題:
當模型是條件概率分佈、損失函式是對數損失函式時,經驗風險最小化就等價於極大似然估計。
當樣本容量很小時,則會產生“過擬合”,結構風險最小化是為了防止過擬合而提出的策略。
機構風險最小化等價於正則化,結構風險在經驗風險上加上表示模型複雜度的正則化項或懲罰項。
結構風險定義如下:
其中J(f)為模型複雜度。
當模型是條件概率分佈、損失函式是對數損失函式、模型複雜度由模型的先驗概率表示時,結構風險最小化就等價於最大後驗概率估計。
結構風險最小化求最優模型就是求解最優化問題:
因此,監督學習問題就變成了經驗風險或結構風險函式的最優化問題,這時經驗或結構風險函式是最優化的目標函式。
4、模型評估
當損失函式給定時,基於損失函式的模型的訓練誤差和模型的測試誤差就自然成為學習演算法的評估標準,但統計學習方法具體採用的損失函式未必是評估時使用的損失函式,讓兩者一致是比較理想的。對於給定的兩種學習方法,測試誤差小的方法具有更好的預測能力。
-
錯誤率和精度 該評估方法與0-1損失函式對應。
-
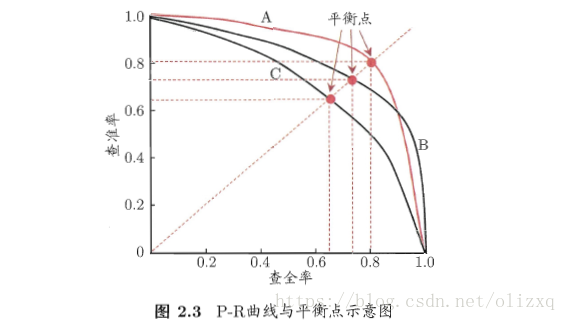
查準率、查全率和F1
查準率:表示預測為正例的樣本中有多少比例真實為正例(檢索的資訊中有多少比例是使用者感興趣的)。 查全率:表示真實為正例的樣本有多少比例被預測為正例(使用者感興趣的資訊有多少比例被檢索出來)。 查準率和查全率是一對矛盾的度量,比如選擇好瓜:當查準率高時,只會選擇最有把握的瓜,從而漏掉不少好瓜,查全率較低;當查全率高時,可通過增加選瓜的數量來實現,如果所有的瓜都被選上,則所有好瓜都被選中,這樣查準率就比較低。
-
F1度量 F1度量的一般形式: 寫成下面形式更容易理解: