
卷積神經網路的網路結構——FractalNet
- 《FractalNet: Ultra-Deep Neural Networks without Residuals》 2016,Gustav Larsson,Michael Maire,Gregory Shakhnarovich. FractalNet 轉載:https://www.cnblogs.com/liaohuiqiang/p/9218445.html
分形網路:無殘差的極深神經網路
文章提出了什麼(What) 1.ResNet提升了深度網路的表現,本文提出的分形網路也取得了優秀的表現,通過實驗表示,殘差結構對於深度網路來說不是必須的。 2.ResNet缺乏正則方法,本文提出了drop-path,對子路徑進行隨機丟棄
為什麼有效(Why) 1.分形網路不像ResNet那樣連一條捷徑,而是通過不同長度的子路徑組合,網路選擇合適的子路徑集合提升模型表現 2.drop-path是dropout(防止co-adaption)的天然擴充套件,是一種正則方法,可以防止過擬合,提升模型表現 3.drop-path提供了很好的正則效果,在不用資料增強時也取得了優秀的結果 4.通過實驗說明了帶drop-path訓練後的總網路提取的單獨列(網路)也能取得優秀的表現。 5.分形網路體現的一種特性為:淺層子網提供更迅速的回答,深層子網提供更準確的回答。
分形網路是怎麼做的(How)
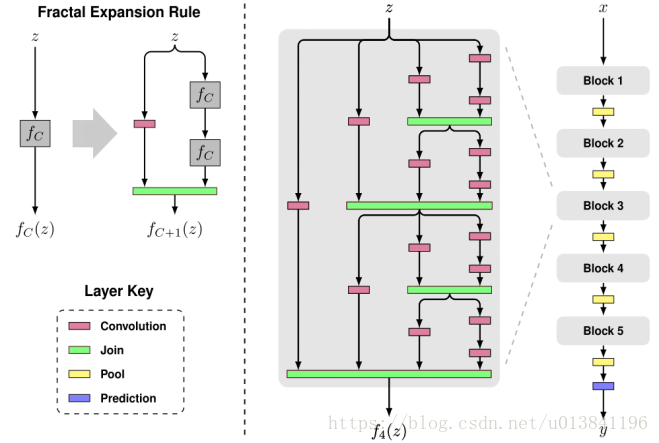
兩種drop-path:
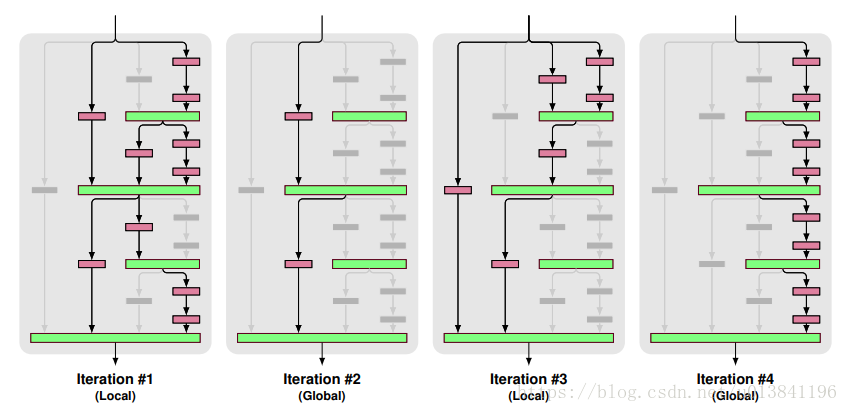 實驗訓練的時候,mini-batch之間交叉使用Local和Global
1.Local:對join層的輸入dropout,但是至少保證要有一個輸入
2.Global: 對於整個網路來說,只選擇一條路徑,且限制為某個單獨列,所以這條路徑是獨立的強預測路徑
實驗訓練的時候,mini-batch之間交叉使用Local和Global
1.Local:對join層的輸入dropout,但是至少保證要有一個輸入
2.Global: 對於整個網路來說,只選擇一條路徑,且限制為某個單獨列,所以這條路徑是獨立的強預測路徑
模型對比的實驗
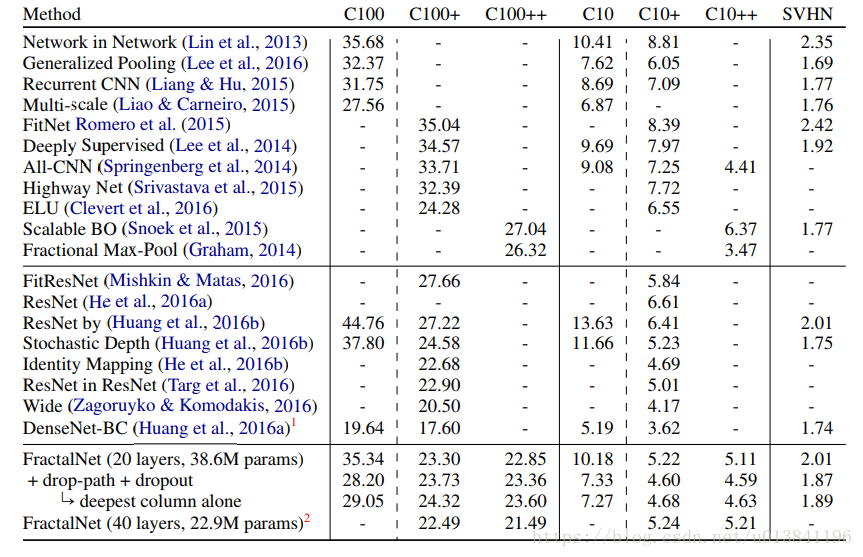
20層分形網路的模型細節 1.每個卷積層後面加了BN(先卷積,再BN,再relu啟用) 2.B=5,C=3 3.訓練集都是32323的影象,使用22的Max-pooling,經過5次下采樣後3232會變成1*1,最後的預測層使用softmax 4.為了實現方便,對於每一個block,調換了最後面的pool和join的順序 5.五個block的卷積核數量預設為64,128,256,512,512 6.每個block最後的dropout概率設為0,0.1,0.2,0.3,0.4 7.整個網路的local drop-path設為0.15 8.caffe實現,學習率為0.02,momentum為0.9,batchsize為100,使用Xavier初始化引數 9.CIFAR-10/CIFAR-100迭代了400輪,SVHN迭代了20輪 10.每當“剩餘epoch數減半”時,學習率除以10(比如剩餘epoch為200時,剩餘epoch為100時,剩餘epoch為50時候)
其它實驗
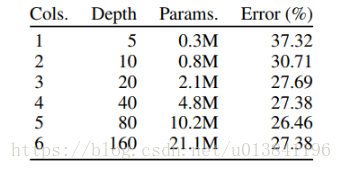
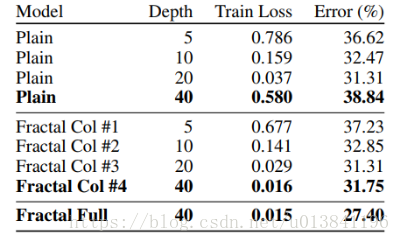
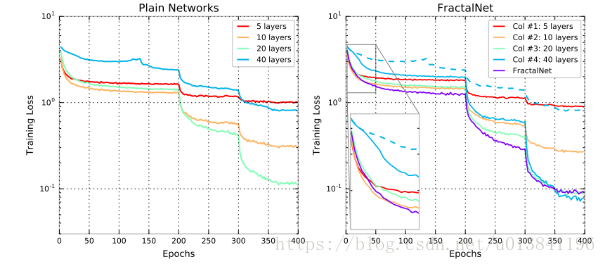
總結: 1.論文的實驗說明了路徑長度才是訓練深度網路的需要的基本元件,而不單單是殘差塊 2.分形網路和殘差網路都有很大的網路深度,但是在訓練的時候都具有更短的有效的梯度傳播路徑 3.分形網路簡化了對這種需求(更短的有效的梯度傳播路徑)的滿足,可以防止網路過深 4.多餘的深度可能會減慢訓練速度,但不會損害準確性